MySQL分表
MySQL环境中,单表建议容量不超过千万条,否则查询效率会有较大影响。在常规的索引、读写分离、合理sql等方法都用上之后,剩下的方法就是分区分表,分表(sharding)就是水平切割。

mysql5.1版本开始,提供 分区(PARTITION)功能,也是对表数据进行切分你的方法之一。分表是把一张大表拆成N张小表;分区是把一张大表的数据分别存储在若干个区块上,仍然还是一张表。
分表策略一般有几类:
1.数字id可以按照数字范围切分,比如上图所示,ID为1~1000w的,放在第一个节点上;10000001~2000w的,放在第二节点上,依次类推。这种方法的好处是方便检索,按id查能够快速定位到那个节点,扩容也方便,增加一个节点就好了;不好的地方是数据不均匀,最后一个节点由于数据比较热,访问的频次会非常大。
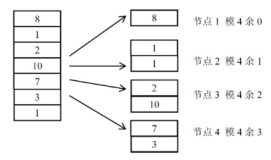
2.为了解决数据热点问题,可以采用取模的方式,进行切分。一般设置2^n个节点,对数字的2^n取模。这种方法的好处是起到负载均衡的作用,热点数据会均衡的散落在各个节点中。坏处是扩容比较费劲,不能随意扩容,只能进行双倍扩容,否则需要进行重新sharding。
3.如果是日志类的数据,可以按照日期进行切分。