大家好,我是欧K~
本期给大家推荐几个pandas高效数据处理函数(持续更新),希望对你有所帮助:
1. 字典创建Dataframe
2. 列拆分(split/extract)
3. 列合并(cat)
4. 左右填充(pad)
5. 根据类型筛选列(select_dtypes)
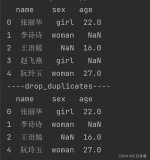
6. 排序(rank)
1. 字典创建Dataframe
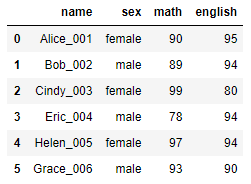
df_dict = {'name':['Alice_001','Bob_002','Cindy_003','Eric_004','Helen_005','Grace_006'],'sex':['female','male','female','male','female','male'],'math':[90,89,99,78,97,93],'english':[95,94,80,94,94,90]} #[1].直接写入参数test_dict df = pd.DataFrame(df_dict) #[2].字典型赋值 df = pd.DataFrame(data=df_dict)
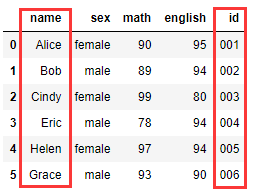
2. 列拆分(split/extract)
字符拆分:
df1[['name', 'id']] = df1['name'].str.split('_', 2, expand = True)
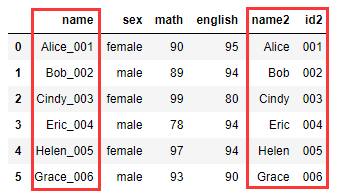
正则表达式拆分:
df2 = df.copy() df2['name2'] = df2['name'].str.extract('([A-Z]+[a-z]+)') df2['id2'] = df2['name'].str.extract('(\d+)')
3. 列合并(cat)
自定义连接符:
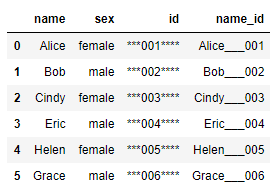
df1["name_id"] = df1["name"].str.cat(df1["id"],sep='_'*3)
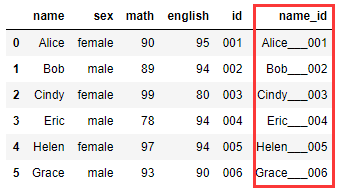
某列合并输出:
df1["name"].str.cat(sep='*'*5)

4. 左右填充(pad)
左填充:
df1["id"] = df1["id"].str.pad(10,fillchar="*") # 相当于ljust() df1["id"] = df1["id"].str.rjust(10,fillchar="*")
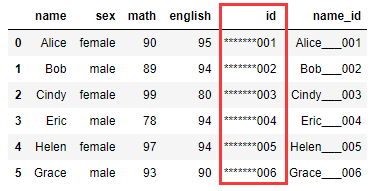
右填充:
df1["id"] = df1["id"].str.pad(10,side="right",fillchar="*")

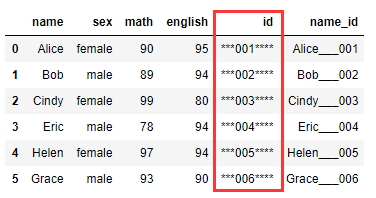
两侧填充:
df1["id"] = df1["id"].str.pad(10,side="both",fillchar="*")
5. 根据类型筛选列(select_dtypes)
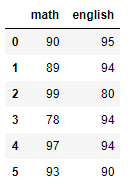
筛选数值列:
df1.select_dtypes(include=['float64', 'int64'])
筛选object列:
df1.select_dtypes(include=['object'])
6. 排序(rank)
英语成绩排名:
df1['e_rank'] = df1['english'].rank(method='min',ascending=False)
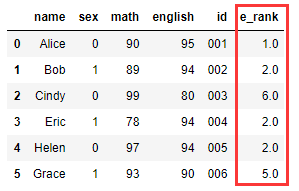
94分有三个,所以三个并列第2。
 END
END
以上就是本期为大家整理的全部内容了,赶快练习起来吧,喜欢的朋友可以 点赞、点在看
点赞、点在看 也可以分享让更多人知道
也可以分享让更多人知道