5.2.7 日期查询
- 日期查询
- year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
# 查询1980年发表的图书 books = BookInfo.objects.filter(pub_date__year='1980')

# 查询1990年1月1日后发表的图书 books = BookInfo.objects.filter(pub_date__gt='1990-1-1')
注意:
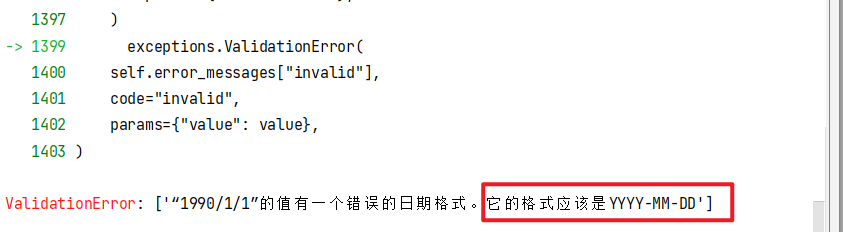
日期的格式只能
YYYY-MM-DD


5.3 F对象(两个属性进行比较)
之前的查询都是对象的属性与常量值比较,两个属性进行比较,使用F对象,F对象被定义在django.db.models中。
语法:
以filter为例
filter(字段名__运算符=F('字段名'))
from django.db.models import F # 查询阅读量大于等于评论量的图书。 books = BookInfo.objects.filter(read_count__gt=F('comment_count'))


# 查询阅读量大于2倍评论量的图书。 books = BookInfo.objects.filter(read_count__gt=F('comment_count') * 2)

5.4 Q对象(逻辑或与非查询)
需要实现逻辑或or、逻辑与and、逻辑非not的查询,可以使用Q()对象结合|、&、~运算符,Q对象被义在django.db.models中。
语法:
Q(属性名__运算符=值)|Q(属性名__运算符=值)|Q(属性名__运算符=值)|···
5.4.1 逻辑与查询
Q对象可以使用&连接,&表示逻辑或。
from django.db.models import Q # 查询阅读量大于20,并且编号小于3的图书。 # 方法一: 进行多次过滤得到结果 books = BookInfo.objects.filter(read_count__gt=20).filter(id__lt=3) # 方法二: books = BookInfo.objects.filter(read_count__gt=20, id__lt=3) # 方法三:使用Q对象相与 books = BookInfo.objects.filter(Q(read_count__gt=20) & Q(id__lt=3))

5.4.2 逻辑或查询
逻辑或查询只能使用Q对象实现
Q对象可以使用|连接,|表示逻辑或。
# 查询阅读量大于20,或编号小于3的图书 books = BookInfo.objects.filter(Q(read_count__gt=20) | Q(id__lt=3))

5.4.3 逻辑非查询
Q对象前可以使用~操作符,表示逻辑非 not。
# 查询编号不等于3的图书。 books = BookInfo.objects.exclude(id=3) books = BookInfo.objects.filter(~Q(id=3))

5.5 聚合函数
使用aggregate()过滤器调用聚合函数。
聚合函数包括:Avg平均,Count数量,Max最大,Min最小,Sum求和,被定义在django.db.models中。
语法:
aggregate(聚合函数('字段名'))
注意aggregate的返回值是一个字典类型,格式如下:
{'属性名__聚合类小写':值}
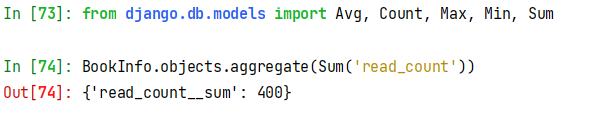
# 导入聚合函数 from django.db.models import Avg, Count, Max, Min, Sum # 查询图书的总阅读量。 books = BookInfo.objects.aggregate(Sum('read_count'))
5.6 排序
使用order_by()对结果进行排序.
降序排序只需要在指定字段前加一个负号即可
# 根据评论数对所有图书的查询结果进行排序 # 默认升序 books = BookInfo.objects.all().order_by('comment_count') # 降序 books = BookInfo.objects.all().order_by('-comment_count')

# 根据阅读数和id对所有图书的查询结果进行排序 # 阅读数升序,相同时按照id号升序排序 books = BookInfo.objects.all().order_by('read_count', 'id') # 阅读数升序,相同时按照id号降序排序 books = BookInfo.objects.all().order_by('read_count', '-id')

5.7 关联查询
5.7.1 由一到多的访问
已知主表数据,关联查询从表数据。
语法:
使用系统内部自动生成的关联模型,关联模型类型小写_set Django会自动生成添加。
主表模型(实例对象).关联模型类型小写_set
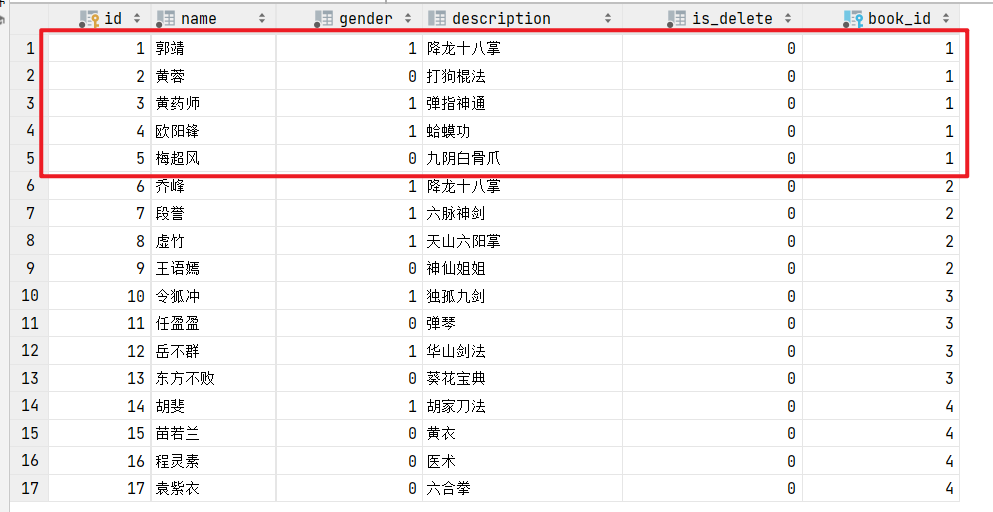
# 查询书籍为1的所有人物信息 # 1. 查询id为1的书籍 book = BookInfo.objects.get(id=1) # 2. 根据书籍关联任务信息 people = book.peopleinfo_set.all()

5.7.2 由多到一的访问
已知从表数据,关联查询主表数据。
语法:
从表模型(实例对象).从表模型中的外键属性 • 1
from book.models import PeopleInfo # 查询人物为1的书籍信息 # 1. 查询id为1的人物信息 person = PeopleInfo.objects.get(id=1) # 2. 根据人物信息获取人物对应的书籍信息 book = person.book

5.7.3 关联查询的筛选
系统内部自动生成的关联模型,Django会自动生成添加从表模型作为主表模型类的属性。
# 查询图书,要求图书任务为“郭靖” # 需要查询的为书籍信息,已知条件为人物信息 # 需要查询的为主表信息,已知条件为从表信息 # 语法: # filter(关联从表模型类名小写__字段名__运算符=值) book = BookInfo.objects.filter(peopleinfo__name__exact='郭靖') # 简写 book = BookInfo.objects.filter(peopleinfo__name='郭靖')

# 查询图书,要求图书中人物的描述包含"八" book = BookInfo.objects.filter(peopleinfo__description__contains='
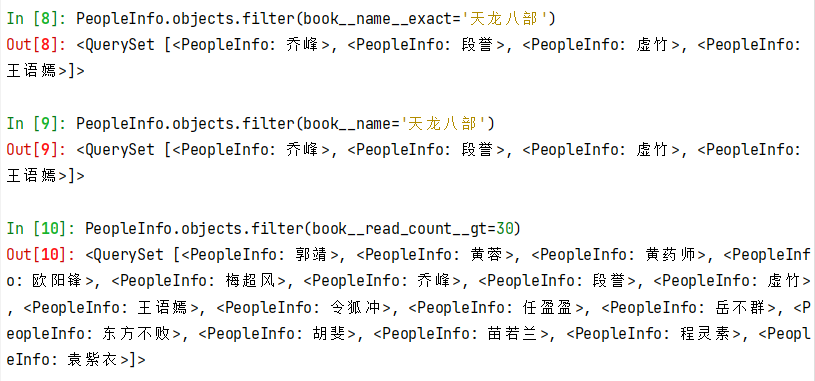
从表模型中有一个外键属性

# 需要查询的为人物信息,已知条件为书籍信息 # 需要查询的为从表信息,已知条件为主表信息 # 语法: # filter(外键__字段名__运算符=值) # 查询书名为“天龙八部”的所有人物 people = PeopleInfo.objects.filter(book__name__exact='天龙八部') # 简写 people = PeopleInfo.objects.filter(book__name='天龙八部') # 查询图书阅读量大于30的所有人物 people = PeopleInfo.objects.filter(book__read_count__gt=30)
5.8 查询集QuerySet
查询集,也称查询结果集(QuerySet),表示从数据库中获取的对象集合。
当调用如下过滤器方法时,Django会返回查询集(而不是简单的列表):
- all():返回所有数据。
- filter():返回满足条件的数据。
- exclude():返回满足条件之外的数据。
- order_by():对结果进行排序。
5.8.1 查询集的特性
- 惰性执行
- 创建查询集不会访问数据库,直到调用查询的数据时,才会访问数据库查询数据。
- 缓存
- 使用同一个查询集,第一次使用时会发生数据库的查询,然后Django会把结果缓存下来,再次使用这个查询集时会使用缓存的数据,减少了数据库的查询次数。
- 如果两个查询集无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载。
- 经过存储后,可以重用查询集,第二次使用缓存中的数据,减少了数据库的查询次数。
5.8.2 限制查询结果集
查询结果集可以看成一个列表,可以对查询集进行下标取值或切片操作。等同于sql中的limit和offset子句。
注意:不支持负数索引。


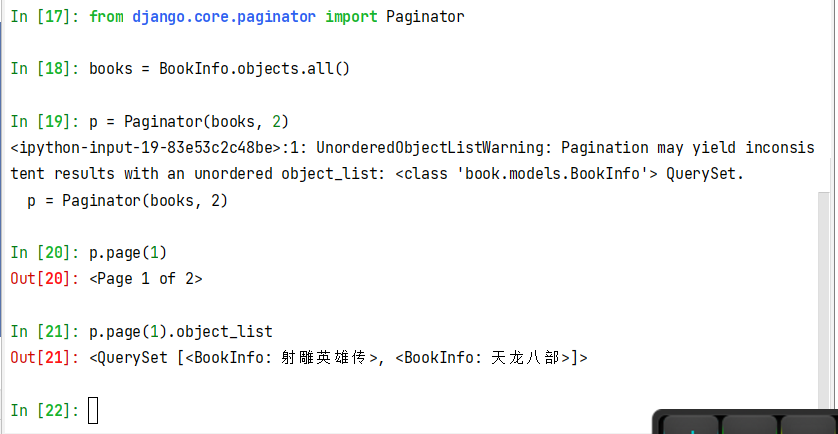
5.8.3 分页
导入分页模块:
from django.core.paginator import Paginator
from django.core.paginator import Paginator # 查询结果集 books = BookInfo.objects.all() # 对查询结果集进行分类 # 需要两个参数 # object_list:需要进行分页的结果集/列表 # per_page:每页多少条记录 # 对books进行分页,每页两条记录 p = Paginator(books, 2) # 获取第一页的数据 # 返回结果看成列表 # object_list获取分页后的结果集 books_page = p.page(1).object_list
获取每页对应的数据集,得到的为一个Page对象,object_list获取数据集