一、简单释义
1、算法概念
冒泡排序(Radix sort)是属于“分配式排序”(distribution sort),又称“桶排序”(bucket sort),顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序,其时间复杂度为O (nlog®m),其中r为所采取的基数,而m为堆数,在某些时候,基数排序法的效率高于其它的稳定性排序法。
2、算法目的
将原本乱序的数组变成有序,可以是 LSD或者 MSD (文中以LSD为例)
3、算法思想
将整数按位数切割成不同的数字,然后按每个位数分别比较。基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
4、算法由来
这个算法的名字由来是因为每个数按照它的位数进行拆分,对每一个对应的位数进行比较排序,直到所有位数都进行过一遍排序位置
二、核心思想
「迭代」:类似的事情,不停地做。
「哈希」:将一个数字映射到一个数组中。
「队列」:采用先进先出的数据结构。
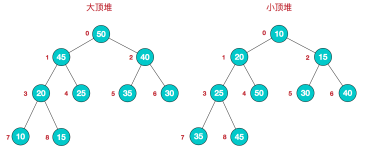
三、图形展示
1、宏观展示

2、微观展示
以324、61、4、10、222、166、512这个数组为例

1、第一次排序:按照每个元素个位数的值填入到对应的桶中,324的个位数是4所以放到4号桶中。从桶向外取值形成新的数组是以队列的先进先出的方式进行的。

2、第二次排序:按照每个元素十位数的值填入到对应的桶中,十位上没有数的元素默认填入到0号桶中即可。其余操作和第一次排序是一样的。比如512十位数的值是1,那么把512这个元素放到1号桶中。从1号桶中取值的时候先取10这个元素,在取512这个元素。

3、第三次排序:按照每个元素百位数的值填入到对应的桶中,百位上没有数的元素默认填入到0号桶中即可。其余操作和上面两次排序是一样的。数组中元素的最高位数就是基数排序要进行的排序的次数。
四、算法实现
1、实现思路
将图形化展示的过程转换成对应的开发语言,本文中主要以Java语言为例来进行算法的实现。
1. 将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零;
2. 从最低位开始,依次进行一次排序;
3. 这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列;
4. 重复步骤1~3,直到排序完成。
能把整个过程描述清楚实现起来才会更加容易!!!
2、代码实现
import java.util.Arrays; /** * @BelongsProject: demo * @BelongsPackage: com.wzl.Algorithm.RadixSort * @Author: Wuzilong * @Description: 描述什么人干什么事儿 * @CreateTime: 2023-05-06 11:24 * @Version: 1.0 */ public class RadixSort { public static void main(String[] args) { int[] numArray={324,61,4,10,222,166,512}; radixSort(numArray); } public static void radixSort(int[] arr) { // 获取数组中最大的数,确定最高位数 int max = arr[0]; for (int i = 1; i < arr.length; i++) { if (arr[i] > max) { max = arr[i]; } } int maxLength = String.valueOf(max).length(); // 定义一个桶,存储每个位数上的数字 int[][] bucket = new int[10][arr.length]; // 定义一个数组,记录每个桶中存储的数据个数 int[] bucketCount = new int[10]; // 按照从低位到高位的顺序进行排序 for (int i = 0, n = 1; i < maxLength; i++, n *= 10) { // 将每个数的第 i+1 位数存到桶中 for (int j = 0; j < arr.length; j++) { int digit = arr[j] / n % 10; bucket[digit][bucketCount[digit]++] = arr[j]; } // 将桶中的数字重新放回到原数组中,这里要注意桶的顺序 int index = 0; for (int j = 0; j < bucket.length; j++) { if (bucketCount[j] != 0) { for (int k = 0; k < bucketCount[j]; k++) { arr[index++] = bucket[j][k]; } bucketCount[j] = 0; } } // 打印每次排序的结果 System.out.println("第"+(i+1)+"次"+Arrays.toString(arr)); } } }
3、运行结果

五、算法描述
1、问题描述
给定一个 n 个元素的整型数组,数组下标从 0开始,采用基数排序,将数组按照 「LSD」排列。
2、算法过程
整个算法过程分为以下几步:
1) n个记录的关键字进行排序,每个关键字看成是一个d元组:ki=(ki1, ki2,…, kid) 其中c0 <=kij <=cr-1 ( 1 <=i <=n, 1 <=j <=d )
2) 排序时先按kid 的值,从小到大将记录分到r(称为基数)个盒子中,再依次收集;
3)然后按kid-1的值再这样作。直至按ki1分配和收集序列为止,排序结束。
3、算法总结
首先,准备 10 个队列,进行若干次迭代 。每次迭代 ,先清空队列,然后取每个待排序数的对应十进制位,通过 哈希 ,映射到它对应的队列 中,然后将所有数字按照队列顺序 塞回 原数组 完成一次 迭代 。
可以认为类似 关键字排序 ,先对 第一关键字 进行排序,再对第二关键字 排序,以此类推,直到所有关键字都有序为止。
六、算法分析
1、时间复杂度
基数排序的时间复杂度为O(d*(n+k)),其中d为最大数的位数,n为待排序的数据个数,k为桶的个数。在数据分布均匀的情况下,基数排序的效率很高,但如果数据分布极端不均匀,则可能导致效率下降,因此在实际使用中需要根据具体情况进行选择。
2、空间复杂度
基数排序的空间复杂度取决于排序过程中用到的辅助存储空间。在基数排序中,需要开辟多个桶(一般为10个)以及一个数组来存储排序结果,因此空间复杂度为O(n+k),其中n为待排序数组的长度,k为桶的个数。
3、算法稳定性
基数排序不会破坏相等元素的相对顺序,所以是稳定的。