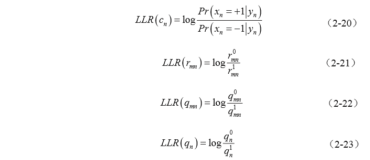背景
在存储和搜索等场景中,往往需要存储数据的整数列或倒排索引(Inverted Index)中的DocId等整数信息,使用数据压缩和编码的方法能够大大降低数据的大小,加快IO占用时间,降低数据的存储场景。本文主要围绕着对整形数据进行编码的场景进行讨论,对应的常见编码和压缩方式有Fixed length,RLE(Run-Length Encoding),Bit Packing,Delta,zigzag,VByte(Varint)或多种方法混合(Hybrid,比如RLE+bit-packing)等等,适合DocId的Simple系列和PForDelta等。本文不展开所有相关的方法,主要讨论最常见的整形编码方式之一:可变长编码(VARINT,即VByte编码),VByte是Byte Oriented的,将数据按照字节存储和解码,本文主要内容围绕两点
-
ByteOriented编码方式:VByte的编码方式和与VByte比较接近的一些变体,如VARINT-GB, VARINT-G8IU,Stream VByte等
-
如何通过SIMD方式加速Byte Oriented的编解码
SIMD补充
SIMD(Single instruction, multiple data),单指令流多数据流是一种采用一个控制器来控制多个处理器,同时对一组数据中的每一个分别执行相同的操作从而实现空间上的并行性的技术。 在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元,例如Intel的MMX或SSE,以及AMD的3D Now!指令集等。
我们能看到很多文章在介绍SIMD,也有很多技术使用了SIMD进行了加速,比如现在有许多的向量化的执行引擎,比如simdJson就利用SIMD技术加速json的编解码;又或者现代的编译器可能就会将我们写的“普普通通”和向量化无关的代码转换成向量化的实现
本文中会涉及到部分SIMD实现的说明,使用的皆为Intel的SSE family。主要讨论的是128
后续提到的指令中主要展开两个命令:Mask和Shuffle
Mask:每8个bit为一组,获取出8bit的最高位bit

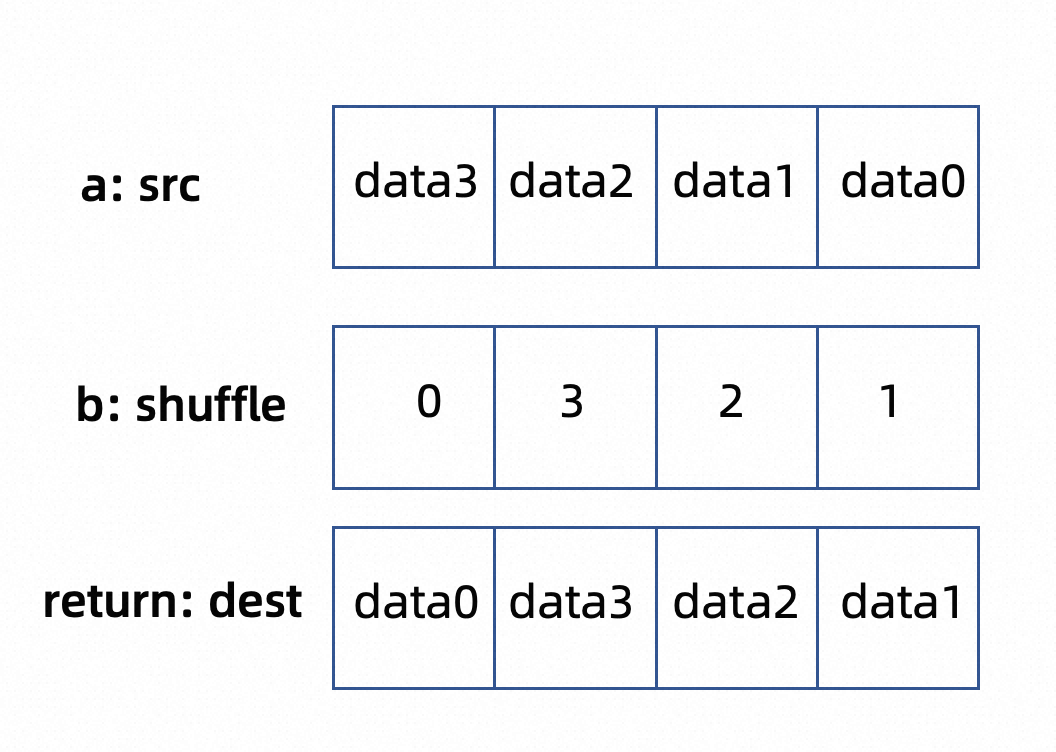
shuffle:将一个向量根据掩码向量进行shuffle,以128bit的向量,8bit为一组共16组为例,如果b第n组数据为m,则代码,则代表dest的第n组数据是a中的第m组 set过来的

以4字节,8bit一组为例,a向向量存取了4组数据,shuffle向量四组数据值分别为1 2 3 0,shuffle后的数据为data1, data2, data3, data0。
Var-Byte:Varint编码

将数据按照7位分组,每个字节有一个continuation bit,最终每组共8bit放在一个Byte中,当最高位(continuation bit)为1时代表还有数据,0代表结束。当复原数据时,主要有三个步骤
-
IF: 通过最高位判断是否此数据结束
-
MASK: 数据mask,去除continuation bit
-
SHIFT: 数据移位把多组数据复原成原始数据
VByte SIMD Decode
Masked VByte
我们能看到,解码VBytes数据时,影响解码速度的主要问题是
-
IF:不停判断每个字节的最高位,糟糕的分支预测情况
-
MASK/SHIFT:每个字节都要mask和shift
而Masked VByte方法主要针对解码:通过SIMD尽可能的减少或者消除上述的情况。其解码步骤如下
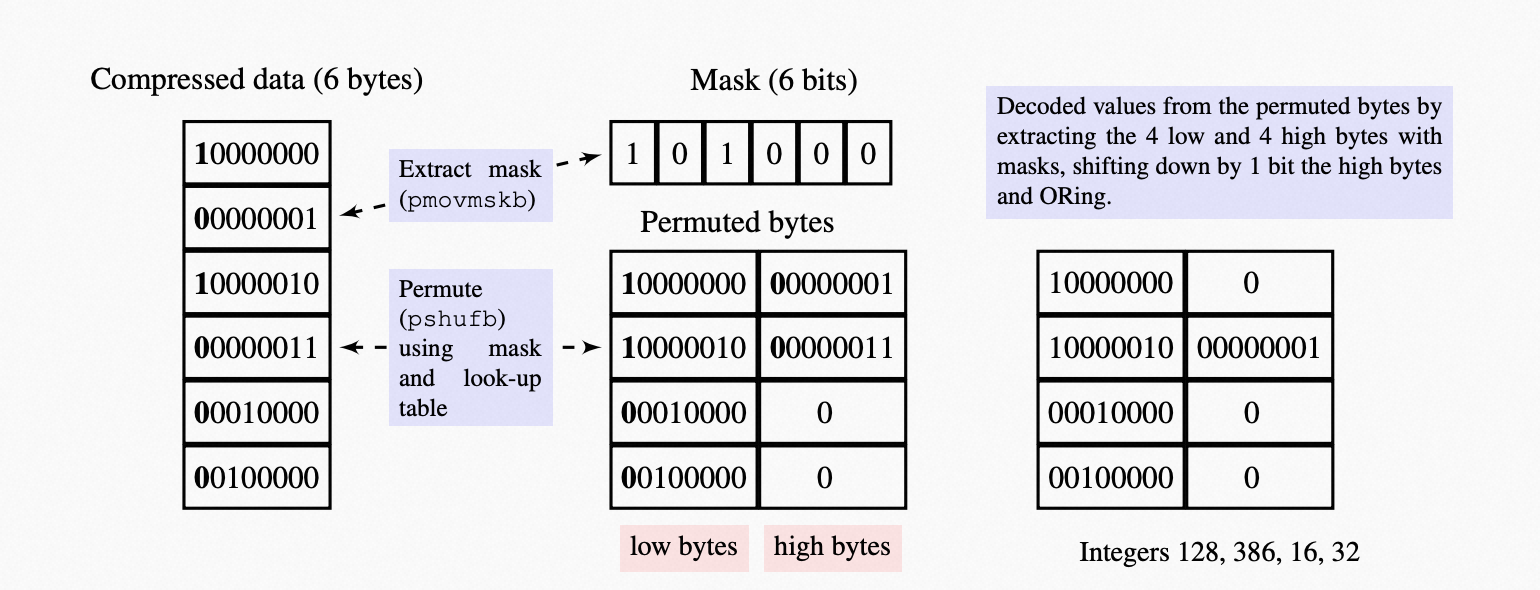
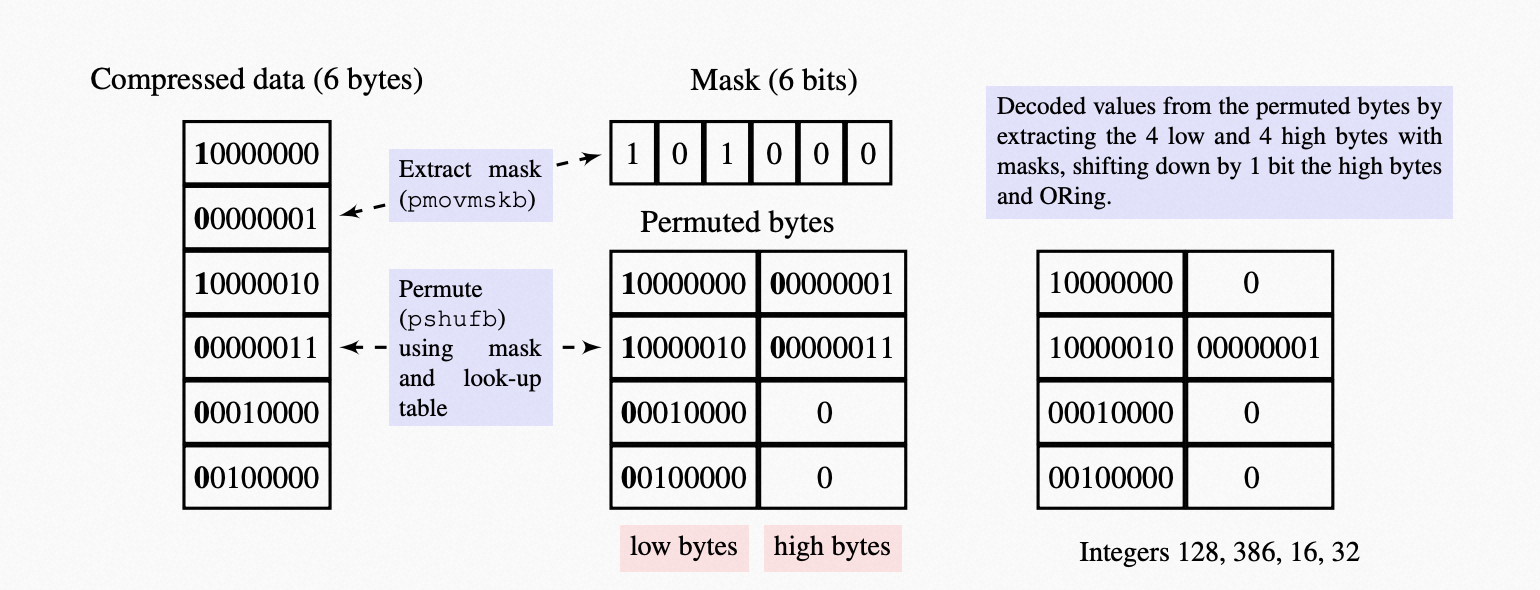
下面的示意图是6Bytes的简化的版本的其中一种情况
-
抽取Mask,一次性获得6Byte数据的continuation bit,作为mask
-
数据Shuffle:根据Mask查找对应的掩码向量(已预定义好不同的mask所对应的Shuffle向量的查找表),将6字节重排列
-
SHIFT:将高低字节(low bytes和high bytes)高位置0,高字节向右移位取或即可构成四个无符号整型数
上述是简单的情况,我们以论文和x86的SIMD代码进行真实情况的讨论
抽取MASK
首先会一次读取16字节,抽取mask,会分为两种情况
-
mask全为0,代表着编码中都只占用了一个Byte,其原始数据最多占用了7Bit,也就是0-127
-
mask不全为0,代表着数据可能存在着大于127的

MASK全为0场景
-
_mm_cvtepi8_epi32将initial的8bit为一组转化为32bit
-
并一次保存128位(4个integer)
-
再移位4*8bit后,继续1步骤,总共转化4次
总的16字节数能够读出16个uint32整数
if (!(mask & 0xFFFF)) {
__m128i result = _mm_cvtepi8_epi32(initial);
_mm_storeu_si128(mout, result);
initial = _mm_srli_si128(initial, 4);
result = _mm_cvtepi8_epi32(initial);
_mm_storeu_si128(mout + 1, result);
initial = _mm_srli_si128(initial, 4);
result = _mm_cvtepi8_epi32(initial);
_mm_storeu_si128(mout + 2, result);
initial = _mm_srli_si128(initial, 4);
result = _mm_cvtepi8_epi32(initial);
_mm_storeu_si128(mout + 3, result);
*ints_read = 16;
return 16;
}MASK低12位分析
我们mask取出16bit,但是我们这里只分析12位,16位的情况可能会超过128bit处理的能力,也会导致shuffle向量的lookup table数量过多
共分为3种情况
-
mask表示其能够至少解码6个数,每个数编码最多占用2Byte(其原始数据有效位最多14)
-
mask表示其能够至少解码4个数,每个数编码最多占用3Byte(其原始数据有效位最多21)
-
mask表示其能够至少解码2个数,每个数编码最多占用5Byte(原始数据可以是整个32位无符号整数范围)
这里只分析第一种情况,实现上和我们上述对Masked VByte是一样的,只是这里会更加具体
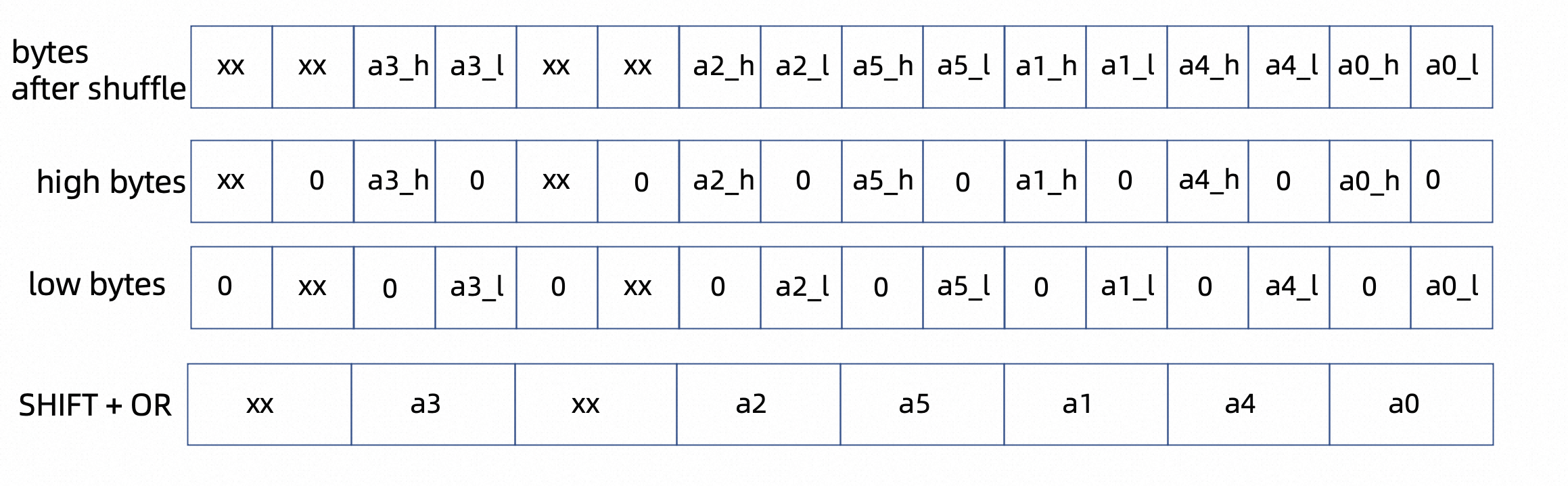
形成重排向量后,分别将low bytes位和high bytes位置0,形成low bytes, high bytes两个向量
__m128i bytes_to_decode = _mm_shuffle_epi8(initial, shuffle_vector);
__m128i low_bytes = _mm_and_si128(bytes_to_decode,
_mm_set1_epi32(0x0000007F));
__m128i middle_bytes = _mm_and_si128(bytes_to_decode,
_mm_set1_epi32(0x00007F00));high bytes右移后与low bytes取或即可构造出a0-a5 6个数据,每个数据占16字节。最后做一些操作分别取出a0-a3和a4-a5即可。
最后将上步结果与0x0000FFFF,仅保留32位的低16位,即uint32的a0-a3;a4-a5 向右shift16位后同理。
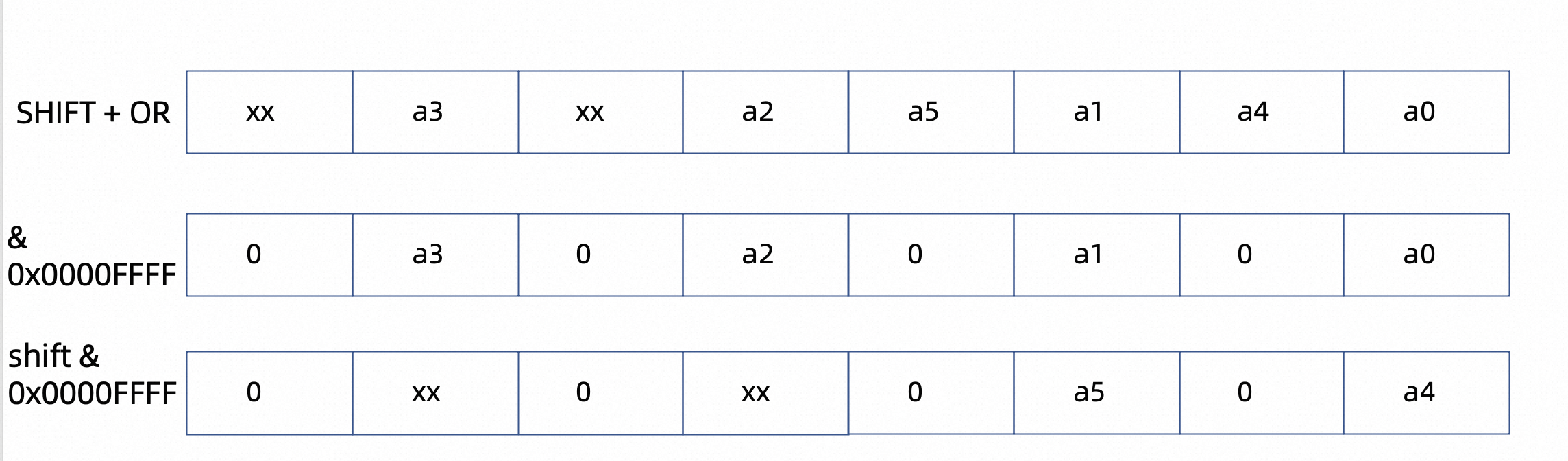
__m128i unpacked_result_a = _mm_and_si128(packed_result,
_mm_set1_epi32(0x0000FFFF));
_mm_storeu_si128(mout, unpacked_result_a);
__m128i unpacked_result_b = _mm_srli_epi32(packed_result, 16);
_mm_storel_epi64(mout+1, unpacked_result_b);上述是基于论文Vectorized VByte Decoding讨论,其实现代码在https://github.com/lemire/MaskedVByte/tree/master
SIMD-Varint
Rust也有基于SIMD的实现,实现上和上述有些小区别,但本质上也是查询lookup table快速得到shuffle的向量,将原始数据shuf后通过SIMD的指令加快操作速度。
https://github.com/as-com/varint-simd
VARINT-GB
Google的Jeff Dean在09年的会议上提出,相对于下图的原始VByte编码,branches/shifts/masks都很多

所以引入了下方的修改方式:通过前面的两bit来直接标识一个数字即 00代表仅本字节,01代表2字节,10代表3字节,11代表4字节(30位有效),但是缺点1是最多标识30bit数据,2是而且仍然需要频繁移位

所以他进一步的,将每个字符的两个标识为都提前标记,以四个为一组,一组正好占用1个字节,能够快速的根据tags的内容跳转到后续的数据和选择合适的mask

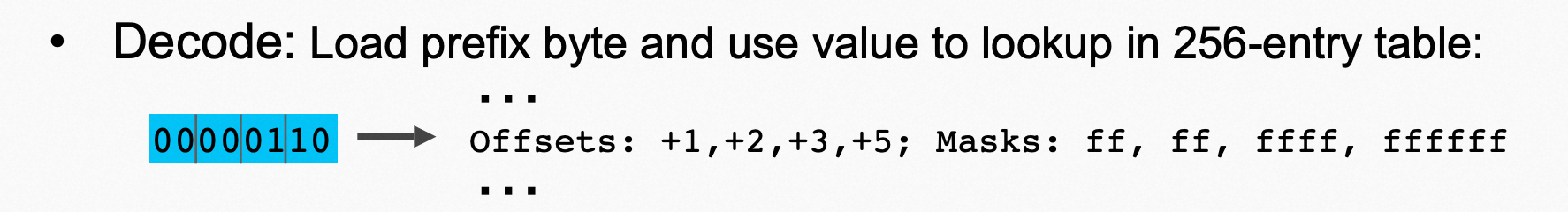

性能相比传统的VBytes,本文中没有实测,在2009年Slides中的数据,是普通的VByte解码速度快2倍以上。
VARINT-G8IU
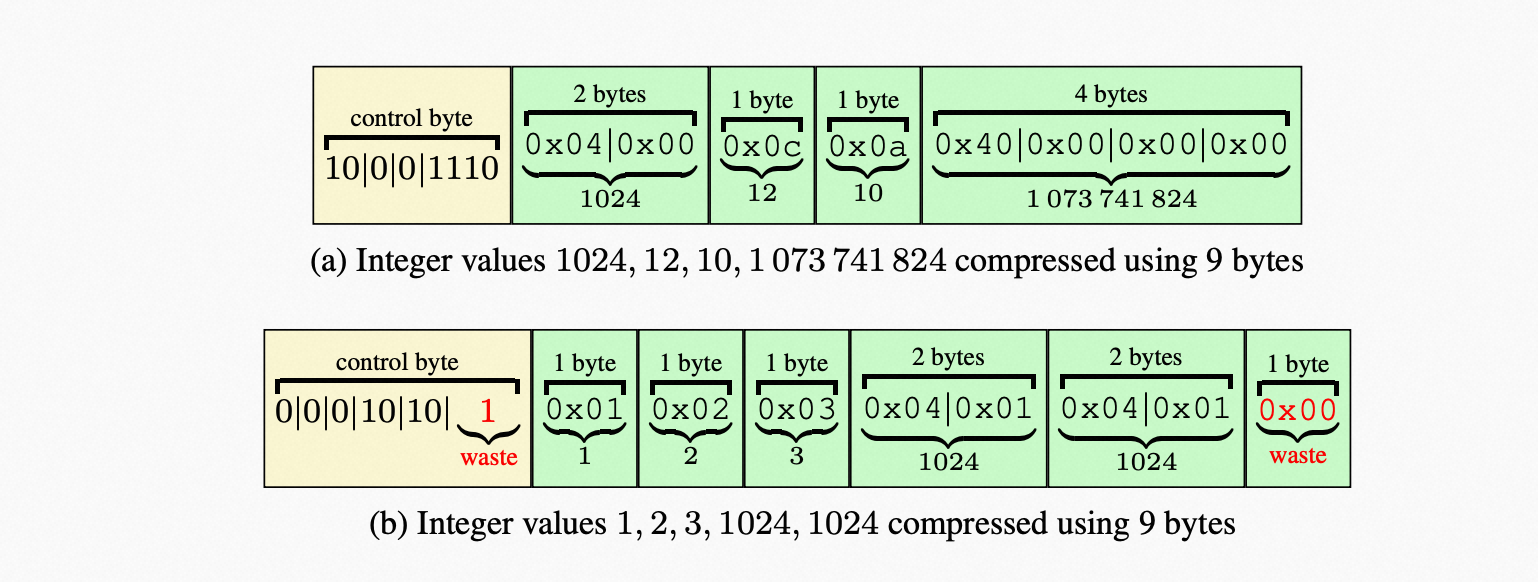
上述的VARINT-GB方法,即使有效位在7bit以内,仍需要额外两个2个control bit,所以相比VByte来说,有25%的额外占用。
新方法VARINT-G8IU将控制位进一步缩小,其理念是以9字节为一个block,在字节有效位少的情况下相比Varint-GB是有更高的利用率的。控制位0 -> 单字节,10 -> 两字节,110 -> 三字节,1110 -> 四子节,一个block可表示2-8个整数,比如说在全部8个数据都有效位都小于7bit的情况下,占用空间相比VARINT-GB小了许多
VARINT-G8CU
上一种编码中可能会出现waste的情况,比如上图中单个block只剩一个字节,但是下一个数需要两个个字节即以上,那么这个control位和block最后的部分旧浪费掉了。G8CU的编码方式会解决这个问题,这个算法会在下一个block中继续上一个block中未编码完成的数据
如下图,在编码完0xAAAA,0XBBBBBB,0xCC后,只有两个字节可用了,但是0xDDDDDDDD需要四个字节,那么继续在下个block中延续编码

stream vbyte
这种方法和VARINT-GB的控制位类似,但把control bytes都连续放置到一起,所有的数据位放置在一起
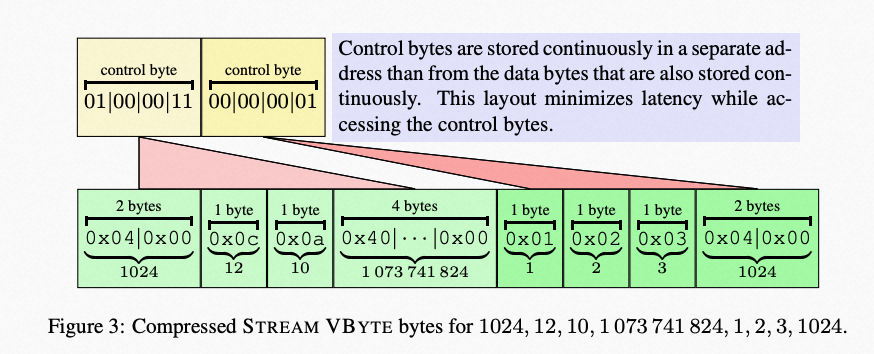
其解码过程本质上和我们上述提过的SIMD解码方法类似(求mask,查找表查shuffle向量,shuffle和解码),但区别是
-
获取mask更简单,只需要一次读取连续的control bytes
-
shuffle后还原数据无需再shift
总结
相对而言相比后面提供的几种变体,普通的VByte实现简单,压缩率最高,但是编解码速度较慢。
上述的多个实现中同时也提供了SIMD的varint+zigzag编码(负数),varint+delta的解码,比varint decode后再还原原始数据更快,具体的实现就不展开说明了。
欢迎指正!
参考
https://zhuanlan.zhihu.com/p/461461186
LEB128编码:http://gttiankai.github.io/2016/06/30/leb128%E7%BC%96%E7%A0%81%E6%A0%BC%E5%BC%8F/
VARINT-GB: https://static.googleusercontent.com/media/research.google.com/zh-CN//people/jeff/WSDM09-keynote.pdf
https://arxiv.org/pdf/1401.6399.pdf
Decoding billions of integers per second through vectorization