👳我亲爱的各位大佬们好😘😘😘
♨️本篇文章记录的为 基因法与倒排索引在MySQL分库分表的应用 相关内容,适合在学Java的小白,帮助新手快速上手,也适合复习中,面试中的大佬🙉🙉🙉。
♨️如果文章有什么需要改进的地方还请大佬不吝赐教❤️🧡💛
我们如何利用基因法与倒排索引来避免全表扫描的问题?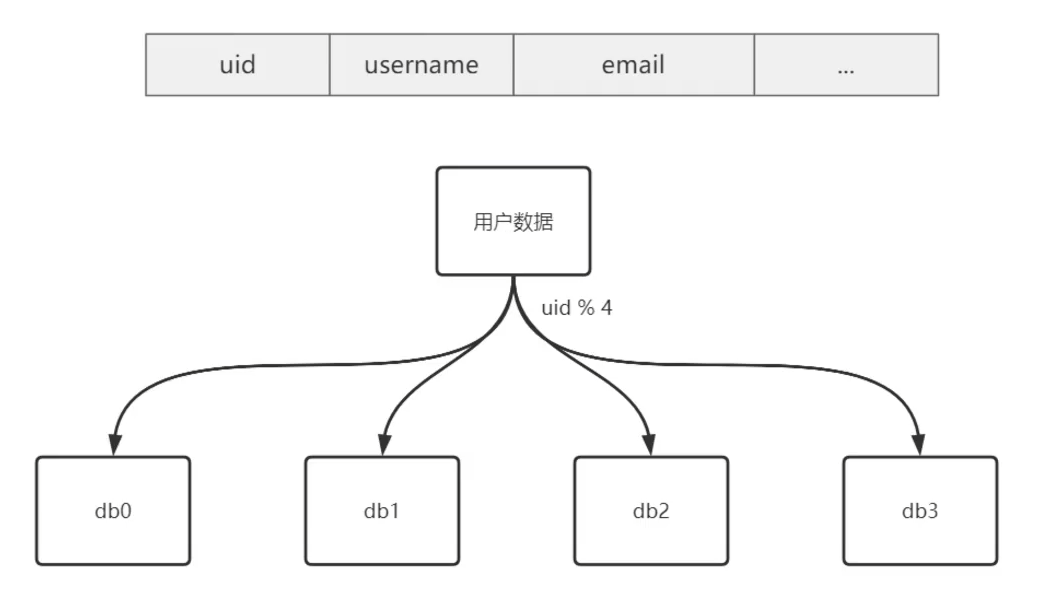
假设呢,现在我们有一个用户表,都知道用户表呢里边包含了用户的ID、用户名、密码、email各种
各样的信息,那么在常见的情况下,如果用户的数据量一大,我们往往就需要进行分户分表,也就
是说把数据呢均分到不同的数据库中,按照常见的哈希的分表方式呢,我们对UID主件来对四进行取
模,将数据呢分散在不同的数据库中,这是一个常见的方案,可是啊,这里我们遇到一个新的挑
战,如果此时我们要按照username或者email来进行数据的查询,那怎么办呢?
我们又不知道username这样对应的数据保存在哪一个数据库里边,那唯一能做的事情就是在我们所有的数据库表中呢,来进行一个查询,把符合要求的username来进行提取,显然呢。 这种操作是非常低效的。
如何高效的处理呢,直接的通过某一种方式快速定位到哪一个库,然后进行数据的提取
两种解决的思路,第一种呢,叫做基因法
基因法
比如说在当前呢,我们这个用户呢,他进行注册,注册本质上就是在用户表中新增一条数据。

那例如这里我们新增的这个数据username是itlaoqi,email是xx@itlaoqi.com,
不管ID=9,那看似平平无奇的这么一条记录,其实啊,里边有非常多的讲究,那我们来看一下
它的执行过程:
- 这个用户名经过前台的校验以后,在真正入库之前,我们要获取itlaoqi他经过数字化转换以后,转成二进制的最后两位,例如现在呢,我们对itlaoqi这个字符串将其MD5进行转换,转换以后呢,把它再从十进制转成二进制,最后会有一个128位的长串,作为这个长二进制串,取最后两位,假设呢最后两位是零和一
为什么要取最后两位
因为作为二进制情况下,两位就是二的二次方,正好对应了四个数据库。那我们就通过最后两位就可以确定我们当前的这个username保存在哪一个数据库中,例如这里我们模拟的最后两位是零一,诶,那经过二进制的转换转成十进制以后,它得到的就是一,那我们就可以决定将it老齐的这个用户呢,保存到了一号数据库中,那这是一个前提,那除此以外。 作为我们的用户编号user ID呢,也不能再像以前一样随意的去生成,哎,无论是数据库的自动编号或者snowflake这种全局的分布式组件生成器都不能这么用了。原因是假设我们的UID是一个长整形,也就是八个字节64位的话,那么在我们UID来进行数据提取的时候,前62位你爱怎么生成怎么生成,但是最后两位要和刚才我们用户名所对应的保持一致,都是零一,那通过这样的一个长串所生的最终的长整形呢,就是我们的主键了,那这里1001对应的ID号呢,它就是九,所以呢,这个九不是我们自动生成的,那是经过刚才的这个算法62加二来得到的,那这里呢,我们再扩展一个小知识。 如果此时呢,我们现在不是四个数据库,而是八个数据库,那这里我们要取最后几位呢?诶很明显嘛,我们要取最后三位,因为最后三位二的三
次方正好等于八,这也就意味着如果是八个基点,需要保留最后三位作为基因,那生成主键的时候就变成了61加上三位基因来构建这个主键编号了。基因法就是通过在我们的编号后面最后几位呢来插入一些基因片段来进行数据库的快速定位。 那么作为基因法呢?它在实际应用中有什么好处呢?
可以看这两项。 第一项呢,就是假设,比如说现在我们刚才用户注册成功了,现在重新登录,在输入了用户名和密码的时候,一旦输入了用户名以后,那么按照刚才的规则,我比如输入it老齐,还是按照MD5再转二进制,最后得到最后两位,他就知道零一,哎,那就知道我们数据呢,往一号库上
来进行查询,这个ID要么是在一号库上存在,要么就根本不存在,不可能出现在其他的地方,那这样我们通过用户名呢,就可以快速的定位到是哪一台服务器上了,那与之对应的,在很多时候,如果我们日常工作场景下,那传递的估计不是用户名,而是UID,那UID呢,刚才得到的是九,那我们们拿到了这个编号九的参数以后,诶,那就可以得到它最后的两位,那也就得到了九编号的用户存在一号数据库上直接。 在一号数据库中进行提取就行了,所以利用基因法我们可以非常方便的快速定位用户名或者user ID这两个关键字段呢,进行数据的定位。 那作为基因法呢,你可能刚才也发现了其中的一些问题,我这里也给你总结了一下,首先基因法呢,它的优点是性能是非常好
的,因为所有的操作呢,都是在我们程序层面上就可以决定是哪一个库,可以直接进行数据的分表快速查询,性能非常好,没有任何的额外的性能损失。但是基因法呢,它的问题呢,其实也比较明显,它受制于外界的约束是比较多的,比如说像刚才我们最后几位往往就决定了最多的数据库节点数量,如果是一位的话,那我们分库最多也可以有两个节点,二就是四三是八个数据库,那按照这样的方式,我们必须要对其进行一个完整的提前规划,利用基因法进行数据迁移的时候,这个工作量呢是非常非常恐怖,而且风险极高,那第二点就是主键生成器的算法呢,要求更高,它不能使用我们市面上的自动。 主件snowflake这样的全局唯一生成器,我们必须要自己构建出来一个全局的
主键生成器,因为最后几位是对应的基因序列,所以这个是稳定不能变化的,而第三个就是只能有一个非主键字段与主键字段来进行对应,就像刚才我们发现没有像登录这样的每一个用户都必须要用到的方案呢,他对于并发的要求可能是比较高的,这里username是每一次登录就必须要进行检查
与校验的,所以呢,它属于我们关键性字段,因此基于以上的这些优缺点呢,我们。 基因法呢,可以用在在关键字段上来使用,比如说用户名,同时因为基因法不支持节点的扩展,所以我们在使用时要提前的把这个数据库节点规划好,要么2486啊,当然了,如果这里你数据库节点哎是356,其实也可以,只不过我们在生成基因的时候,那要把不存在的这个节点编号呢,从中剔除就可以了。
以上便是基因法的优缺点和应用场景,那么针对基因法呢,性能是非常好的,可以适用于对性能要求极高的并发场景,那有没有一种更普适性,更具有通用性的一种设计呢?答案是肯定的。我们还有一种叫做倒排索引法
倒排索引
那就像现在咱们看到的,我们按照UID来进行数据的哈希分库,哎,通过取模决定落在哪一个数据库里边。 那这时如果我们有需求,希望按照用户名来进行查询的时候,我们需要额外的构建一个第三方,也就是redis的倒排索引.
倒排索引是什么?
以前我们叫正牌索引或叫正向索引呢,是通过ID号去标记其他的数据,所谓倒排索引啊,你一看就明白了,就是通过我们其他字段去绑定对应的ID号,那按照当前的规则我来说明一下,那redis中它有很多个K,那这个K呢,我们应用的规则呢,前面UR呢,其实就是user色的简写代表是用户表,下划线代表,这是基于email字段的倒排索引,那么我们直接就可以通过red的倒排索引来提取出来对应的邮箱,它的UID和存储在哪一台服务器上,非常的直接,然后我们就直接到对应的数据库提取真正的数据就可以了。那么与之类似的,如果我们上边还支持像这个手机号登录的话,那么手机号登录您可以在手机号这个上面增加倒排索引,把这个当前的手机和对应的UID和数据库节点的编号呢都有一个对照,通过这个倒排索引直接拿到UID和座落的服务器,然后再到对应的服务器。 器上进行查询就可以了,这就是倒排索引了,使用起来还是比较简单的。那针对倒排索引呢,它有缺点,它也有优点,那优点呢就是它是几乎最通用的分库分表的检索方案了,几乎适用于所有的系统,可以进行对其优化。
但是呢,作为倒排索引,它也有着非常多的缺点,第一个缺点呢,就是要多一次查询,我们需要先通过radi中查询到所对应的UID和坐落到数据库的哪一个节点上,然后呢我们再进行二次查询。第二个呢是控制不好数据量就会爆炸,对red的内存的需求是比较大的,我们可以看到,假设我们有200万用户,那现在呢,检索的条件可能有三个,一个可能是按用户名,一个是按email,还有一个可能是按手机号,这三个那按照倒排索引的规则呢,它应该会有200。 乘以三六百万条数据出现在咱们的RA中,尽管单条RA它的数据存量非常小,只保存了这些最基本的信息,但是架不住数量极大呀,如果是上千万数据呢,就可能会出现对red的内存的需求特别大,动辄呢可能是要上10G几十G啊,
那么出现这种情况下,有一个优化的方案是,如果我们服务器的SSD的性能够好,哎,采用的是企业级的这种高可靠的SSD,速度快,稳定性也好,这时我们也可以把放在radi中的这些数据呢,以mysql inno DB表的形式来保存,利用SSD的这种优秀的性能和这个啊缓存的特性呢,来瞬间完成我们数据提取的工作,而最后呢,就是需要手动维护数据库和缓存的一致性存在软状态,因为假设未来我们,比如某一个用户,他的email发生了变化的话,是不是我们对应的。 缓存的数据也要发生相应的变化,但是数据库和缓存本身呢,它更新的时候就不是强一致了,我们需要更多的精力去处理这个一致性的问题,所以说引入了倒排损以后,又会延伸出来一些新问题。
以上就是我在分库分表时查询优化的一些思路,希望能对你有帮助,谢谢大家
如果这篇【文章】有帮助到你💖,希望可以给我点个赞👍,创作不易,如果有对Java后端或者对
spring感兴趣的朋友,请多多关注💖💖💖
👨🔧 个人主页 : 阿千弟

