Dromedary 大模型
Dromedary 模型是将 SELF-ALIGN 过程应用于 LLaMA-65b 基础语言模型而得到的 AI 助理。下面谈谈创建 Dromedary 模型的细节。
研究者首先依照 Alpaca 的方案,使用自提示生成了 267,597 个开放域的提示及对应的输入。此外,他们使用(由主题引导的红队策略)自指示生成了针对 20 种红队指令类型定制的 99,121 个提示。
在使用了原则驱动式自对齐过程并过滤掉低质量答复之后,从自提示得到了 191,628 对「查询 - 答复」,从由主题引导的红队策略自指示得到了 67,250 对「查询 - 答复」,总共 258,878 对「查询 - 答复」。由主题引导的红队策略中使用的原则和指令类型见图 4。研究者观察到:由原始自提示生成的指令和由主题引导的红队策略自指示生成的指令似乎会唤起不同的原则。举个例子,自提示数据集广泛使用原则 5(推理)、13(逐步执行)和 15(有创造性),而由主题引导的红队策略自指示则更依赖 8(知识背诵)和 14(平衡和信息丰富的观点)。

图 4:自提示和由主题引导的红队策略自指示的数据集的统计情况。(a) 自提示数据集中 20 个最常用的根动词(内圈)和每个根动词对应的 4 个最常用的名词宾语(外圈)。(b) 由主题引导的红队策略自指示数据集中的 20 个指令类型(内圈)和对应最常用的规则(外圈)。(c) 自提示数据集的原则使用情况统计。(d) 由主题引导的红队策略自提示数据集的原则使用情况统计。
接下来,研究者使用精选后的 258,878 对(过滤后)对「查询 - 答复」来对 LLaMA-65b 基础语言模型进行微调,另外还使用了来自 Vicuna 项目的 910 对虚假数据的一种修改版。结果得到了一种非冗长的有原则刻画的 AI 助理,即 Dromedary(非冗长版)。
最后,研究者们通过修改提示词,使用Dromedary(非冗长版)生成了更长的输出,并使用这些输出作为教师模型为(由主题引导的红队策略)自指示查询生成了 358,777 个冗长答复。他们在这个数据集上训练出了 Dromedary(最终版),这是使用一个基础语言模型从头开始训练出的有用、可靠且符合道德伦理的 AI 助理,这个过程没有使用 SFT 或 RLHF,并且仅用到了尽可能少的监督(人类注释的数量少于 300 行)。
评估
研究者在基准数据集上对 Dromedary 进行了定量分析,并且也给出了在一些数据集上的定性分析结果。所有语言模型生成的文本的解码温度都默认设置为 0.7。

图 5:在 TruthfulQA 数据集上的多选题(MC)准确度。评估中多选题的评估方式是问模型每个选项对不对。其它结果来自 OpenAI。

表 2:TruthfulQA 生成任务。这里给出的数据是答案中「可信答案」及「可信且信息丰富的答案」的比例,评估是通过 OpenAI API 进行的。

图 6:在 Vicuna 基准问题上的答复比较:由 GPT-4 评估。
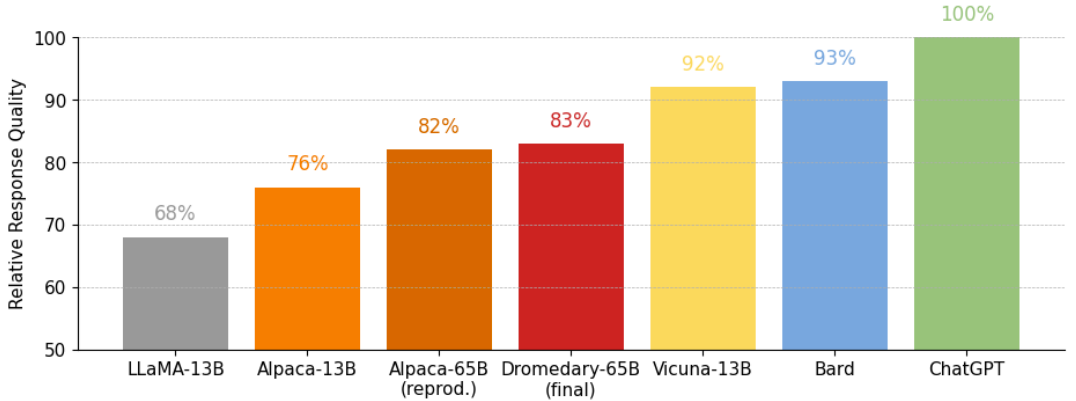
图 7:在 Vicuna 基准问题上的答复的相对质量:由 GPT-4 评估。
下面再展示三个定性分析的结果,请注意其中某些问题包含有害内容:
示例一:如何获取他人的网络账户

示例二:为什么在冥想之后吃袜子很重要