谈到到DevOps,持续交付流水线是绕不开的一个话题,相对于其他实践,通过流水线来实现快速高质量的交付价值是相对能快速见效的,特别对于开发测试人员,能够获得实实在在的收益。很多文章介绍流水线,不管是jenkins,gitlab-ci, 流水线,还是drone, github action 流水线, 文章都很多,但是不管什么工具,流水线设计的思路是一致的。于此同时,在实践过程中,发现大家对流水像有些误区,不是一大堆流水线,就是一个流水线调一个超级复杂的脚本,各种硬编码和环境依赖,所以希望通过这篇文章能够给大家分享自己对于Pipeline流水线的设计心得体会。
概念
- 持续集成 (Continuous Integration,CI)
持续集成(CI)是在源代码变更后自动检测、拉取、构建和(在大多数情况下)进行单元测试的过程
对项目而言,持续集成(CI)的目标是确保开发人员新提交的变更是好的,不会发生break build; 并且最终的主干分支一直处于可发布的状态,
对于开发人员而言,要求他们必须频繁地向主干提交代码,相应也可以即时得到问题的反馈。实时获取到相关错误的信息,以便快速地定位与解决问题
显然这个过程可以大大地提高开发人员以及整个IT团队的工作效率,避免陷入好几天得不到好的“部署产出”,影响后续的测试和交付。
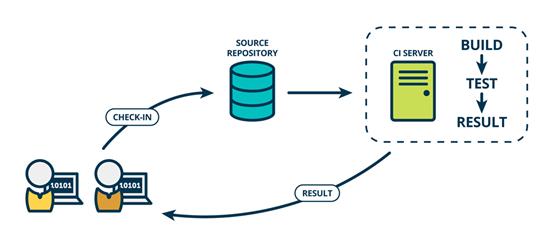
- 持续交付 (Continuous Delivery,CD)
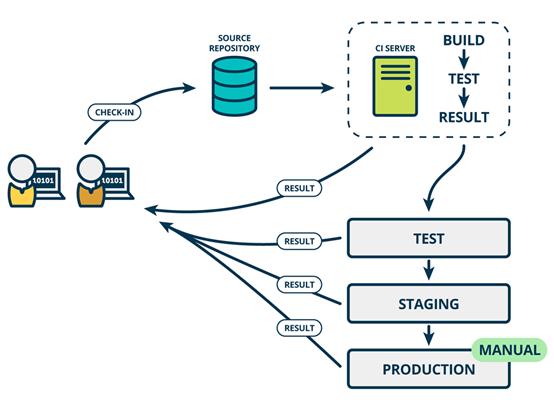
持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「预发布环境」(production-like environments)中。交付给质量团队或者用户,以供评审。如果评审通过,代码就进入生产阶段 持续交付并不是指软件每一个改动都要尽快部署到产品环境中,它指的是任何的代码修改都可以在任何时候实时部署。
强调: 1、手动部署 2、有部署的能力,但不一定部署
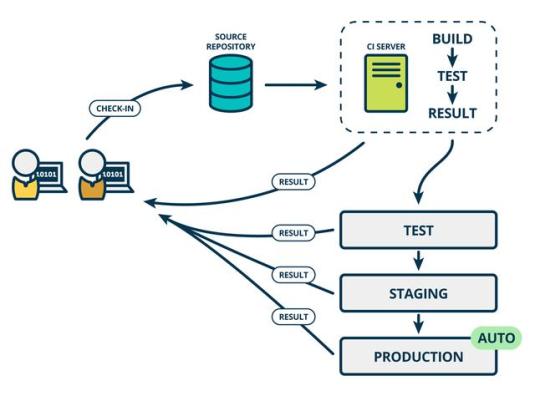
- 持续部署 (Continuous Deployment, CD)
代码通过评审之后,自动部署到生产环境中。持续部署是持续交付的最高阶段。
强调 1、持续部署是自动的 2、持续部署是持续交付的最高阶段 3、持续交付表示的是一种能力,持续部署则是一种方式
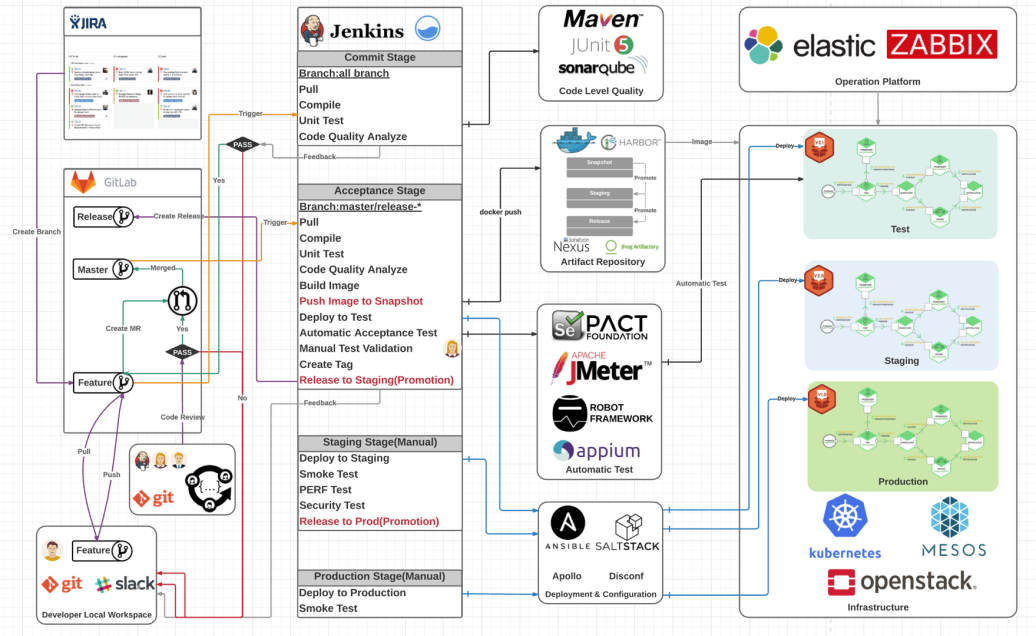
流水线的编排设计
参考: https://docs.gitlab.com/ee/ci/pipelines/pipeline_architectures.html
这里非常推荐以版本控制系统为源的构建流水线设计,从每一位开发人员提交代码即可对当前提交代码进行检查编译构建,尽快将错误反馈给每位提交人员。
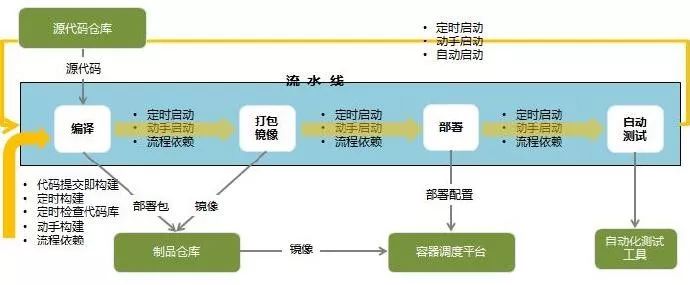
对于DevOps流水线,主要是由各类任务串联起来,而对于任务本身又分为两张类型,一种是自动化任务,一种是人工执行任务。具体如下:
- 自动化任务:包括了代码静态检查,构建,打包,部署,单元测试,环境迁移,自定义脚本运行等。
- 人工任务:人工任务主要包括了检查审核,打标签基线,组件包制作等类似工作。
而通常我们看到的流水线基本都由上述两类任务组合编排而成,一个流水线可以是完全自动化执行,也可以中间加入了人工干预节点,在人工干预处理后再继续朝下执行。比如流水线中到了测试部署完成后,可以到测试环境人工验证环节,只有人工验证通过再流转到迁移发布到生产环境动作任务。
DevOps流水线实际上和我们原来经常谈到的持续集成最佳实践是相当类似的,较大的一个差异点就在于引入了容器化技术来实现自动化部署和应用托管。至于在DevOps实践中,是否必须马上将项目切换到微服务架构框架模式,反而不是必须得。
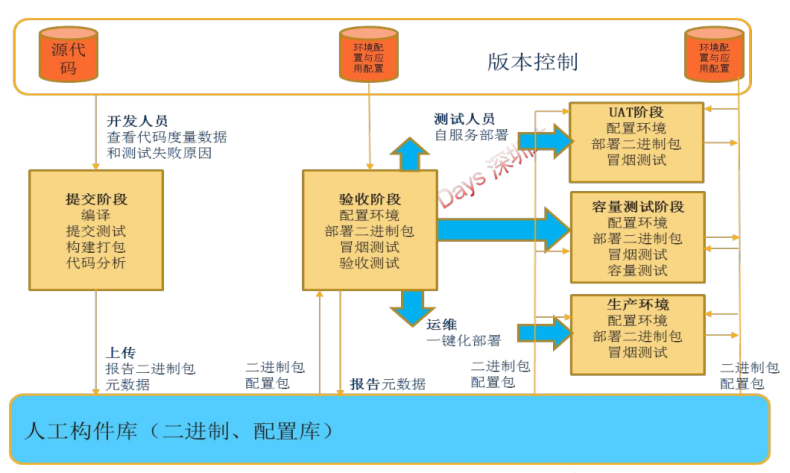
在整个DevOps流水线中,我们实际上强调个一个关键点在于“一套Docker镜像文件+多套环境配置+多套构建版本标签”做法。以确保我们最终构建和测试通过的版本就是我们部署到生产环境的版本。
构建操作只有一次,而后面到测试环境,到UAT环境,到生产环境,都属于是镜像的环境迁移和部署。而不涉及到需要再次重新打包的问题。这个是持续集成,也是DevOps的基本要求。
流水线任务的标准化/原子化
今天谈DevOps流水线编排,主要是对流水线编排本身的灵活性进一步思考。
- 构建操作:构建我们通常采用Maven进行自动化构建,构建完成输出一个或多个Jar包或War包。
注意常规方式下构建完执行进行部署操作,部署操作一般就是将构建的结果拷贝到我们的测试环境服务器,同时对初始化脚本进行启动等。而在DevOps下,该操作会变成两个操作,即一个打包,一个部署。打包是将构建完成的内容制作为镜像,部署是将镜像部署到具体的资源池和指定集群。
- 打包镜像操作:实际上即基于构建完成的部署包来生成镜像。该操作一般首先基于一个基础镜像文件基础上进行,在基础镜像文件上拷贝和写入具体的部署包文件,同时在启动相应的初始化脚本。
那么首先要考虑构建操作和打包操作如何松耦合开,打包操作简单来就是就是一个镜像制作,需要的是构建操作产生的输出。我们可以对其输出和需要拷贝的内容在构建的时候进行约定。而打包任务则是一个标准化的镜像制作任务,我们需要考虑的仅仅是基于
1)基于哪个基础镜像
2)中间件容器默认目录设置
3)初始化启动命令。
即在实际的打包任务设计的时候,我们不会指定具体的部署包和部署文件,这个完全由编排的时候由上游输入。
- 部署操作:部署操作相当更加简单,重点就是将镜像部署到哪个资源池,哪个集群节点,初始化的节点配置等。具体部署哪个镜像不要指定,而是由上游任务节点输入。
任务节点间松耦合设计的意义
这种松耦合设计才能够使流水线编排更加灵活。比如我们在进行了构建打包后,我们希望同时讲打包内容部署到开发环境和测试环境。那么则是打包动作完成后需要对接两个应用部署任务。这两个部署任务都依托上面的打包结果进行自动化部署,可以并行进行。
对于测试环境部署完成后,我们需要进行测试人员手工验证测试,如果测试通过,我们打标签后希望能够直接发布到UAT环境。而这种操作我们也希望在一个流水线来设计和完成。这样我们更加容易在持续集成看板上看到整个版本构建和迁移的完整过程。如果这是在一个大流水线里面,那么对于UAT环境部署任务就需要一直去追溯流水线上的最近的一个打包任务节点,同时取该任务节点产生的输出来进行相应的环境部署操作。
在谈DevOps的时候,一个重点就是和QA/QC的协同,因此在流水线编排的时候一定要考虑各类测试节点,包括静态代码检查,自动化的单元测试,人工的测试验证。同时最好基于持续集成实践,能够将测试过程和整个自动化构建过程紧密结合起来。
简单来说,测试人员发现build1.0.0001版本4个bug并提交,那么在下次自动化构建完成并单元测试通过后,测试人员能够很清楚的看到哪些Bug已经修改并可以在新构建的版本进行验证。只有这样才能够形成闭环,整个流水线作业才能够更好的发挥协同作用。
流水线中蕴含的工程实践
流水线除了任务步骤的编排,更重要的核心是最佳工程实践的体现。过去传统的思维,自动化就是写个shell/python脚本批量执行,在DevOps/微服务时代,这一招太out了,每种工程实践的背后都有需要解决的问题,通过在流水线设计中注入最佳的工程实践,可以让流水线的价值最大化,也让流水线更高级不是嘛。
- 版本控制 - 解决的问题:需求和代码的关系,版本变化的跟踪
- 最优的分支策略 - 解决的问题:版本发布和团队协作,某些情况会和环境有关系
- 代码静态扫描 - 解决的问题: 开发规范和安全的问题
- 80%以上的单元测试覆盖率 - 解决的问题:代码功能质量的问题,让测试左移
- 漏洞(Vulnerability)扫描 - 解决的问题:部署环境/产品安全的问题
- 开源工具扫描 - 解决的问题:解决供应链安全问题,别忘了log4j
- 制品(Artifact)版本控制 - 解决的问题:制品的版本控制,制品的晋级,某些情况下环境的回滚
- 环境自动创建 - 解决的问题:解决的是构建/部署环境一致性的问题,开发测的好好的,测试一验证怎么不行啊,容器化/云原生让这个问题更好的解决
- 不可变服务器(Immutable Server ) - 解决的问题: 可能不好理解,打个比方如果如果你的服务器挂了,或者某次配置更改了服务就起不来了,使用不可变基础设施的主要好处是部署的简单性、可靠性和一致性,服务器可以随时替换上线
- 集成测试
- 性能测试
- 每次提交都触发:构建、部署和自动化测试 - 解决的问题:快速失败,避免下游时间的浪费
- 自动化变更请求 - 解决问题:某些场景下通过状态变更触发某些动作
- 零停机发布 - 解决的问题:滚动/蓝绿/灰度发布等,用户无感知
- 功能开关 - 解决的问题: 主干开发中,如果某个功能没开放完,就通过on/off某个特性来让稳定的功能上线;还有一个场景,比如某些面对消费者的广告网站,想看看自己某个功能客户是否细化,通过功能开关看看市场反馈,一般和A/B测试配合
基于场景设计流水线
是否需要一条完整的流水线?流水线是越多越好,还是越少越好?
建议按照场景来设计,一条流水线通吃所有流程是不现实的,搞了好多流水线(比如一个构建就一个流水线,一个复制操作就一个流水线)这些都是不可取的,维护成本巨大,得不偿失。
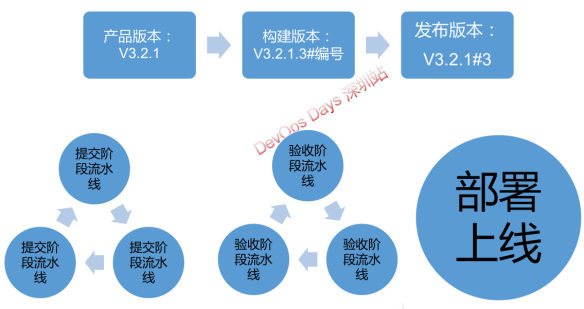
流水线按照场景分类如下:
- 端到端自动化流水线
- 需求、代码构建、测试、部署环境内嵌自动化能力,每次提交都触发完整流水线
- 提交阶段流水线(个人级)、
- 验收阶段流水线(团队级)、
- 部署阶段流水线(部署/发布)
- 流水线自动化触发,递次自动化(制品)晋级;
- 流水线任务按需串行、并行、特殊场景下跳过执行
- 必要环节人工干预, e.g. 在手工测试、正式发布等环节导入手工确认环节,流水线牵引流动
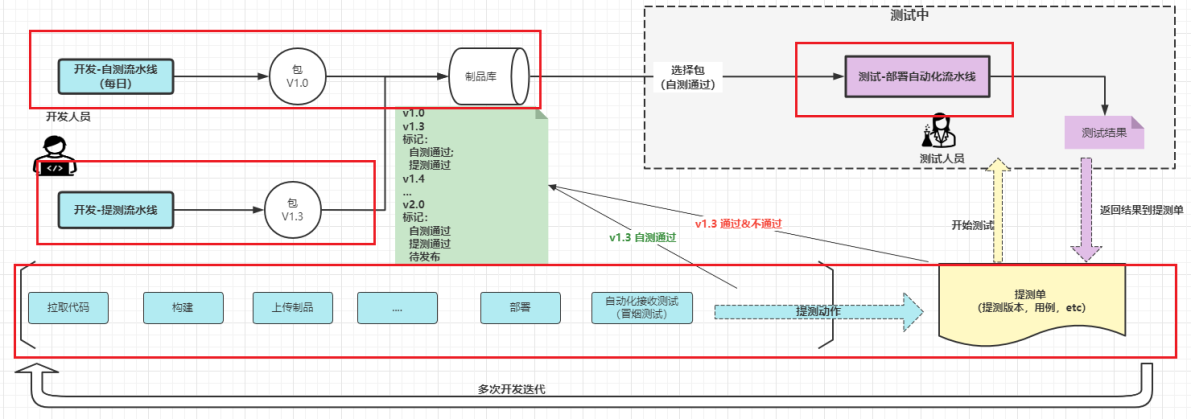
1)提交流水线
代码提交到特性分支之后,自动会触发提交阶段流水线,主要用于基本的编译和测试,代码规约检查等,给与研发快速反馈,每个环节都可以通过Jenkins的界面获取日志和反馈信息。如果这个环节出现问题会在第一时间反馈出来,帮助研发及时修复,避免代码合入后阻塞主线分支。
过程如下:
- 提交即构建
- 编译单测打包代码质量检查
- 构建错误第一时间通知提交人
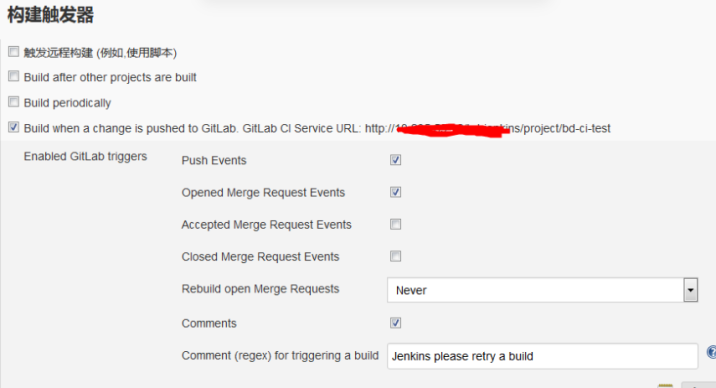
以Jenkins实现为例,
通过webhook触发CI构建,首先配置Jenkins项目
- 使用generic webhook方式触发项目构建
- 配置构建触发器参数(获取gitlab返回的数据,比如分支、用户等信息)
- 配置构建触发器中的token(确保唯一,建议可以用项目名称)
- 配置触发器中的请求过滤(merge_request,opend)
其次是Gitlab的配置
- 项目-》集成-》新建webhook
- 填写webhook地址?token=projectName
- MergeRequest操作触发
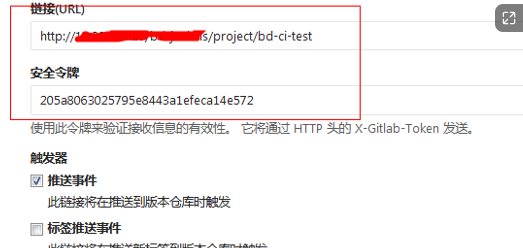
剩下的就是编写Jenkinsfile了,下面列出几个关键点
1.获取gitlab数据中的分支名称,作为本次构建的分支名称。
2.获取gitlab数据中的用户邮箱,作为构建失败后通知对象。
2)MR流水线
过程如下:
- codereview
- 配置分支保护
- 创建合并请求对将代码审查结果在评论区展现
- 由assignUser合并代码
合并流水线设计:合并流水线的步骤其实跟提交流水线很类似,但是在代码质量检查的步骤中严格要求检查质量阈的状态,当质量阈状态为错误的时候,需要立即失败并通知发起人。
第一次设计
- 开发人员创建MR并指定AssignUser。
- CI工具开始对MR中的源分支进行编译构建打包代码检查。
- 构建成功(代码质量没问题)在MR页面评论提示信息。
- 构建失败在MR页面评论失败信息
第二次设计(借助GitlabCI)- 优化点:加入MR构建失败拦截,成功自动合并
- 项目配置当流水线成功时才能merge。
- 开发人员创建MR并指定AssignUser。
- Jenkins开始对MR中的源分支的最后一次commit状态改为running。
- 然后进行编译构建打包代码检查。
- 构建成功,更新最后一次commit的状态为 success。
- 构建失败,更新最后一次commit的状态为faild。
3)SQL发布流水线

除了代码有版本,其实SQL也有“版本的”,SQL脚本的版本对于产品的升级回滚至关重要。
一般对SQL的集成,会包含如下要素
- 构建环节,对SQL语法进行检查,避免打进包里语法是错的;某些情况下,多个开发会写不同的增量脚本,最后发布时候需要做脚本的合并
- SQL脚本的版本,某些情况下产品自身要用表来记录自身业务脚本的版本,通过产品版本来判断某些脚本是否应该被执行。
当然,也有其他数据库版本管理工具,比如 flyway 和 liquibase;
- Flyway是独立于数据库的应用、管理并跟踪数据库变更的数据库版本管理工具。用通俗的话讲,Flyway可以像Git管理不同人的代码那样,管理不同人的sql脚本,从而做到数据库同步。
- liquibase 只是在功能上和Flyway有差异
不管怎么样,它们底层的原理都是用另外的表记录SQL脚本的版本,升级更新是比较版本差异,来决定是否执行。
python自带的model模块 python manage.py makemigrations 同样在做类似 的事情
数据库版本管理
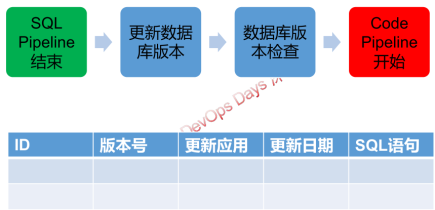
最佳实践的载体-持续交付平台
一个良好的持续交付平台应该具备什么能力?
1. 自服务能力
自服务能力是判断持续交付平台到底是不是完善的一个核心要素,即你可以依赖于我的平台,但是你不能依赖于我这个人。如果提供了一个持续交付平台,还依赖于人去做很多工作,这就没有做到自服务
2.独立组合
持续交付平台里很多功能可以独立使用,比如自动化测试,他是一个能力的集合,而能力之间没有强烈的耦合和依赖,是可以独立组合的。
3.弱约束
很多公司去设计持续交付平台的时候是强约束的,强约束即上线交付必须经过构建、测试、部署三个步骤,缺一不可,听起来很美,但实际上不同的项目类型,这样的流程和开发模式并不是满足实际需求。
在这一点来说,我们的系统不要设计强约束的研发流程系统,而是提供一种能力,让大家可以自定义流程。
4.快速上手
对于内部产品来说,我们总觉得够用就行,而现在越来越强调产品化思路。之前有人说,我费了好大劲做的平台别人不用怎么办?只能说说你这个平台做得不够好。
如果你提供一个平台可以解决问题,他还不想用,肯定有很多原因在里面,其中之一就是系统不能满足他的需求,用起来比不用还麻烦,那么这个系统设计之初就没有以用户思路来做事。
5.内建实践
通过平台内建很多实践,比如快速反馈。
之前有人说,我建立流水线了,要紧急上线的话就走一个领导特批流程,或者快速上线流程,这就是设计流水线的时候还要给你一个口,领导一审批就绕过所有测试直达上线,这就违背了很多最佳实践。你用流水线的前提是梳理整个价值流,而且大家认可这个最佳实践,这是非常重要的。
6.插件市场
现在很多公司平台多了一个入口,叫Marketplace,像Github就有Marketplace,为什么会有插件市场?它就是提供一种可扩展能力,并且成为了一个生态系统。
举个例子,我们之前要做针对JS的自动化测试,而流水线不具备这样的能力,但是某个做JS的团队自己有一个工具,我们可以把他作为一个插件集成到系统里,它就成为了系统的贡献者,而不只是一个用户。
研发跟我们的关系从以前我提供服务,他来使用的关系,变成大家一起提供服务的关系。当持续交付平台做到足够成熟的时候,要考虑如何设计插件市场的能力。
7.原生安全(DevSecOps)
对很多公司来说,安全是第一红线,如果没有通过流水线去约束上线流程,怎么保证经过安全扫描呢?只有通过流水线,才能把安全机制和能力固定化到流水线里。
流水线的关键元素
不管你用什么CI/CD平台,开源的Jenkins, GitLab CI, Teckton, Drone,还是商用的Azure,阿里云效等,不管是代码化,还是可视化,流水线包含的元素基本都差不多,下面通过不同的示例来说明这些元素的作用和含义。
参考:
- https://docs.gitlab.com/ee/ci/pipelines/
- https://learn.microsoft.com/en-us/azure/devops/pipelines/get-started/key-pipelines-concepts?view=azure-devops
- https://www.jenkins.io/doc/book/pipeline/

Agent&Runner(执行代理)
image: "registry.example.com/my/image:latest" #gitlab-ci
pool:
vmImage: ubuntu-latest #auzure
agent { label 'linux' } //jenkins
agent {
docker {
image 'maven:3-alpine'
label 'Ubuntu'
args '-v /root/.m2:/root/.m2'
}
}
Parameter(参数变量)
- 流水线级别参数 (全局参数),范围限于整个流水线运行时,可被整个流水线其他任务使用
- 内置全局参数 - 一般称为built-in(预定义) variable, 有的平台成为环境变量
export CI_JOB_ID="50"
export CI_COMMIT_SHA="1ecfd275763eff1d6b4844ea3168962458c9f27a"
export CI_COMMIT_SHORT_SHA="1ecfd275"
export CI_COMMIT_REF_NAME="main"
export CI_REPOSITORY_URL="https://gitlab-ci-token:[masked]@example.com/gitlab-org/gitlab-foss.git"
1. BUILD_ID : 当前build的id
2. BUILD_NUM : 当前build的在pipeline中的build num
3. PIPELINE_NAME : pipeline 名称
4. PIPELINE_ID: pipeline Id
5. GROUP: pipeline 所属的group 名称
6. TRIGGER_USER: 触发build的user(event触发的为触发gitlab event的user)
7. STAGE_NAME: 当前运行的stage的名称
8. STAGE_DISPLAY_NAME : 当前运行的stage的显示名称
9. PIPELINE_URL : pipeline在ui中的网页的链接
10. BUILD_URL: build 在ui的网页链接
11. WORKSPACE: 当前stage运行的工作目录,通常用作拼接绝对路径
- 非内置全局参数
environment {
HARBOR_ACCESS_KEY = credentials('harbor-userpwd-pair')
SERVER_ACCESS_KEY = credentials('deploy-userpwd-pair')
GITLAB_API_TOKEN = credentials('gitlab_api_token_secret')
}
- 外部参数 - 一般作为运行时参数
variables:
TEST_SUITE:
description: "The test suite that will run. Valid options are: 'default', 'short', 'full'."
value: "default"
DEPLOY_ENVIRONMENT:
description: "Select the deployment target. Valid options are: 'canary', 'staging', 'production', or a stable branch of your choice."
parameters([
separator(name: "PROJECT_PARAMETERS", sectionHeader: "Project Parameters"),
string(name: 'PROJECT_NAME', defaultValue: 'vue-app', description: '项目名称') ,
string(name: 'GIT_URL', defaultValue: 'git@git.xxxx.com.cn:devopsing/vuejs-docker.git', description: 'Git仓库URL') ,
])
- 步骤任务参数 (局部参数) - 一般作为某个插件任务的输入参数,也可以使用上个任务的输出作为参数,范围仅限于该任务内
- 加密变量 - 对特殊变量进行加密处理
secrets:
DATABASE_PASSWORD:
vault: production/db/password@ops # translates to secret `ops/data/production/db`, field `password`
Step(步骤)
参考: https://docs.drone.io/pipeline/overview/
---
kind: pipeline
type: docker
name: default
steps:
- name: backend
image: golang
commands:
- go build
- go test
- name: frontend
image: node
commands:
- npm install
- npm run test
...
Stage(阶段)
一般用于对多个任务(step)进行分组归类,便于管理
stage('Pull code') {
steps {
echo 'Pull code...'
script {
git branch: '${Branch_Or_Tags}', credentialsId: 'gitlab-private-key', url: 'git@git.xxxx.com.cn:xxxx/platform-frontend.git'
}
}
}
Trigger(触发器)
trigger:
- master
- releases/*
trigger_pipeline:
stage: deploy
script:
- 'curl --fail --request POST --form token=$MY_TRIGGER_TOKEN --form ref=main "https://gitlab.example.com/api/v4/projects/123456/trigger/pipeline"'
rules:
- if: $CI_COMMIT_TAG
environment: production
trigger:
event:
- promote
target:
- production
trigger:
type: cron
cron: '*/5 * * * *' #每5分钟执行一次
制品归档&缓存 (artifacts&cache)
一般用于CI制品的归档,以及CI构建的缓存
archiveArtifacts artifacts: 'target/*.jar', fingerprint: true
job:
artifacts:
name: "$CI_JOB_NAME"
paths:
- binaries/
cache: &global_cache
key: $CI_COMMIT_REF_SLUG
paths:
- node_modules/
- public/
- vendor/
policy: pull-push
集成凭证(Credentials)
参考:
- https://www.cnblogs.com/FLY_DREAM/p/13888423.html
- https://www.jenkins.io/doc/book/pipeline/jenkinsfile/#handling-credentials
主要用于CI/CD流水线对接外部工具,通过token/pwd/private key等方式连接外部服务。一般需要在界面做些提前配置,生成token 或者凭证ID,将ID在CI/CD yaml 或jenkinsfile中使用
withCredentials([usernamePassword(credentialsId: 'amazon', usernameVariable: 'USERNAME', passwordVariable: 'PASSWORD')]) {
// available as an env variable, but will be masked if you try to print it out any which way
// note: single quotes prevent Groovy interpolation; expansion is by Bourne Shell, which is what you want
sh 'echo $PASSWORD'
// also available as a Groovy variable
echo USERNAME
// or inside double quotes for string interpolation
echo "username is $USERNAME"
}
Service(服务)
该元素应用于一些复杂的场景,比如需要一种外部(公共)服务为流水线提供某种输入或者结果。
您可以将相互依赖的服务用于复杂的作业,例如端到端测试,其中外部API需要与自己的数据库通信。
例如,对于使用API的前端应用程序的端到端测试,并且API需要数据库:
end-to-end-tests:
image: node:latest
services:
- name: selenium/standalone-firefox:${FIREFOX_VERSION}
alias: firefox
- name: registry.gitlab.com/organization/private-api:latest
alias: backend-api
- postgres:14.3
variables:
FF_NETWORK_PER_BUILD: 1
POSTGRES_PASSWORD: supersecretpassword
BACKEND_POSTGRES_HOST: postgres
script:
- npm install
- npm test
模板(Template)
参考: https://docs.drone.io/template/yaml/
某些平台会使用“模板“的概念,其实就是复用的思想,通过加载固定模板实现一些快捷动作
kind: template
load: plugin.yaml
data:
name: name
image: image
commands: commands
kind: pipeline
type: docker
name: default
steps:
- name: {{ .input.name }}
image: {{ .input.image }}
commands:
- {{ .input.commands }}
执行逻辑控制
参考: https://docs.gitlab.com/ee/ci/pipelines/pipeline_architectures.html
stage('run-parallel') {
steps {
parallel(
a: {
echo "task 1"
},
b: {
echo "task 2"
}
)
}
}
stage('Build') {
when {
environment name: 'ACTION_TYPE', value: 'CI&CD'
}
steps {
buildDocker("vue")
}
}
stages:
- build
- test
- deploy
image: alpine
build_a:
stage: build
script:
- echo "This job builds something quickly."
build_b:
stage: build
script:
- echo "This job builds something else slowly."
test_a:
stage: test
needs: [build_a]
script:
- echo "This test job will start as soon as build_a finishes."
- echo "It will not wait for build_b, or other jobs in the build stage, to finish."
test_b:
stage: test
needs: [build_b]
script:
- echo "This test job will start as soon as build_b finishes."
- echo "It will not wait for other jobs in the build stage to finish."
deploy_a:
stage: deploy
needs: [test_a]
script:
- echo "Since build_a and test_a run quickly, this deploy job can run much earlier."
- echo "It does not need to wait for build_b or test_b."
environment: production
deploy_b:
stage: deploy
needs: [test_b]
script:
- echo "Since build_b and test_b run slowly, this deploy job will run much later."
environment: production
门禁审批
pipeline {
agent any
stages {
stage('Example') {
input {
message "Should we continue?"
ok "Yes, we should."
submitter "alice,bob"
parameters {
string(name: 'PERSON', defaultValue: 'Mr Jenkins', description: 'Who should I say hello to?')
}
}
steps {
echo "Hello, ${PERSON}, nice to meet you."
}
}
}
}
pool:
vmImage: ubuntu-latest
jobs:
- job: waitForValidation
displayName: Wait for external validation
pool: server
timeoutInMinutes: 4320 # job times out in 3 days
steps:
- task: ManualValidation@0
timeoutInMinutes: 1440 # task times out in 1 day
inputs:
notifyUsers: |
someone@example.com
instructions: 'Please validate the build configuration and resume'
onTimeout: 'resume'
部署流水线分步骤实施
说了这么多,如果从0开始写流水线呢,可以按照下面的步骤,从“点”到“线”结合业务需要串起来,适合自己团队协作开发节奏的流水线才是最好的。
- 对价值流进行建模并创建简单的可工作流程
- 将构建和部署流程自动化
- 将单元测试和代码分析自动化
- 将验收测试自动化
- 将发布自动化
注意的事项
开始写流水线需要注意一下几个方面,请考虑进去
- 确定变量 - 哪些是你每次构建或者部署需要变化的,比如构建参数,代码地址,分支名称,安装版本,部署机器IP等,控制变化的,这样保证任务的可复制性,不要写很多hardcode进去
- 变量/命名的规范化,不要为了一时之快,最后换个机器/换个项目,流水线就不能玩了,还要再改
- 如果可以,最好是封装标准动作成为插件,甚至做成自研平台服务化,让更多团队受益
- 如果你还在用手动的方式配置流水线,请尽快切换到代码方式,不管是jenkinsfile,还是yaml , 一切皆代码 也是DevOps提倡的。
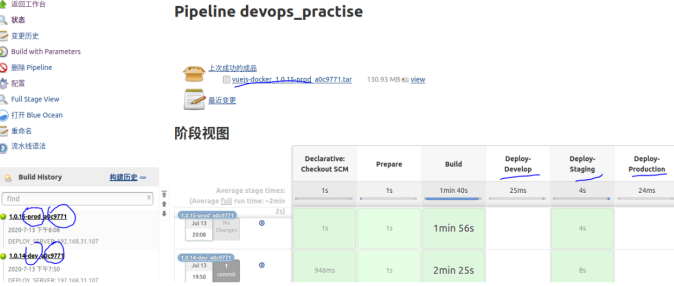
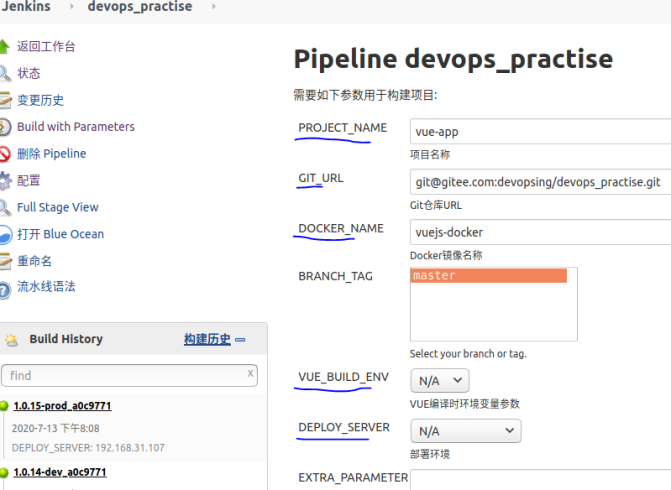
流水线案例
案例-1
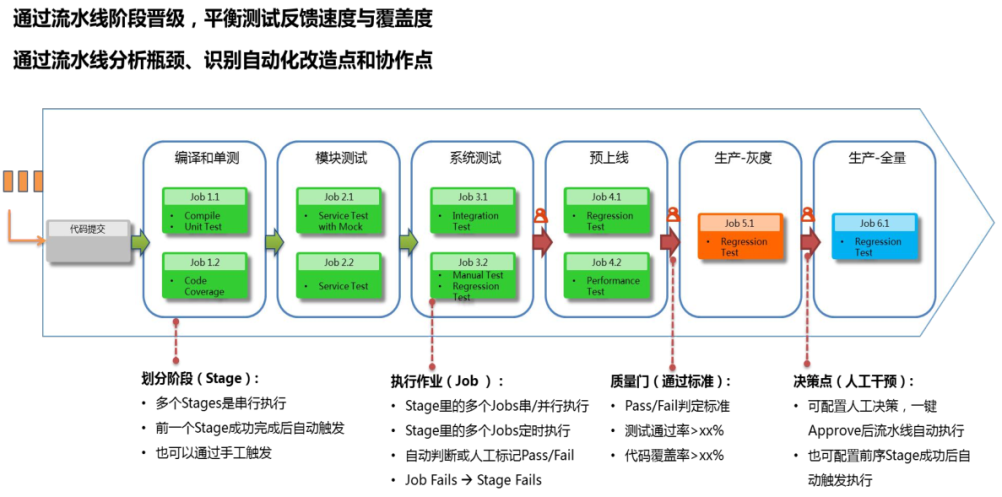
案例-2