🍎《python机器学习从入门到高级》:线性回归和正则化
- ✨本文收录于《python机器学习从入门到高级》专栏,此专栏主要记录如何使用python实现机器学习模型,尽量坚持每周持续更新,欢迎大家订阅!
- 🌸个人主页:JoJo的数据分析历险记
- 📝个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生
- 💌如果文章对你有帮助,欢迎✌
关注、👍点赞、✌收藏、👍订阅专栏
本专栏主要从==代码角度==介绍如何使用python实现机器学习算法,想要了解具体机器学习理论的小伙伴,可以看我的这个专栏:统计学习方法
@TOC
| 上一章中我们以minist数据集演示了如何实现一个分类算法,并进行选择。这一章中,我们将介绍广义线性模型。广义线性模型是机器学习的基础部分,也是很多其他算法的延伸。本文主要介绍一下如何实现简单的线性回归和正则化方法✨ 具体理论部分可以看这篇文章:[https://blog.csdn.net/weixin_45052363/article/details/123610610](https://blog.csdn.net/weixin_45052363/article/details/123610610) # 🍅1.线性回归 通常,线性回归通过简单计算输入特征的加权和,加上一个称为偏差项(也称为截距项)的常数来进行预测。具体公式如下: $$ \hat{y}=\beta_0 + \beta_1 X_1+...+\beta_n X_n $$ 接下来我们看看具体如何实现线性回归模型 ```python import numpy as np import matplotlib.pyplot as plt ``` ```python # 生成模拟数据集 X = np.random.randn(100,1) y = 3*X+4+np.random.randn(100,1) ``` 观察一下生成的数据集 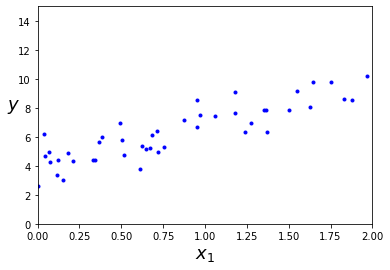 ```python plt.plot(X, y, "b.") plt.xlabel("$x_1$", fontsize=18) plt.ylabel("$y$", rotation=0, fontsize=18) plt.axis([0, 2, 0, 15]) plt.savefig("generated_data_plot") plt.show() ``` 可以看出数据呈现比较明显的线性趋势,下面使用`LinearRegression`实现对线性模型的训练 ```python from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X, y) a = lin_reg.intercept_ b = lin_reg.coef_ a,b#回归系数和截距 ``` (array([3.86880209]), array([[3.0229374]])) 下面根据训练好的线性回归模型进行预测, ```python X_new = np.array([[0], [2]]) y_predict = lin_reg.predict(X_new) y_predict ``` array([[3.86880209], [9.91467688]]) 将预测结果可视化如下 ```python plt.plot(X_new, y_predict, "r-", linewidth=2, label="Predictions") plt.plot(X, y, "b.") plt.xlabel("$x_1$", fontsize=18) plt.ylabel("$y$", rotation=0, fontsize=18) plt.legend(loc="upper left", fontsize=14) plt.axis([0, 2, 0, 15]) plt.show() ``` 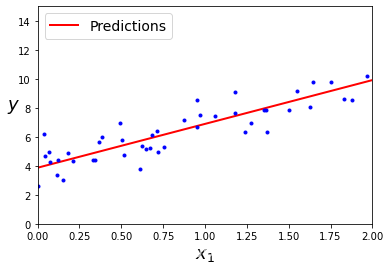 可以看出拟合结果还不错,下面我们绘制一下Learning curve:随着模型训练样本的变化观察训练集和测试集的误差 ```python from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split ''' 定义learning_curves函数 ''' def plot_learning_curves(model, X, y): X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=10)#将数据分为训练集合验证集 train_errors, val_errors = [], []#定义训练误差和验证误差 for m in range(1, len(X_train) + 1): model.fit(X_train[:m], y_train[:m])#根据训练集大小训练模型 y_train_predict = model.predict(X_train[:m])#拟合训练集 y_val_predict = model.predict(X_val)#拟合验证集 train_errors.append(mean_squared_error(y_train[:m], y_train_predict))#计算训练集MSE val_errors.append(mean_squared_error(y_val, y_val_predict))#计算测试集MSE plt.plot(np.sqrt(train_errors), "r-", linewidth=2, label="train")#绘制训练集RMSE plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")#绘制测试集RMSE plt.legend(loc="upper right", fontsize=14) #增加图例 plt.xlabel("Training set size", fontsize=14) plt.ylabel("RMSE", fontsize=14) ``` ```python lin_reg = LinearRegression() plot_learning_curves(lin_reg, X, y) plt.axis([0, 80, 0, 3]) plt.show() ``` 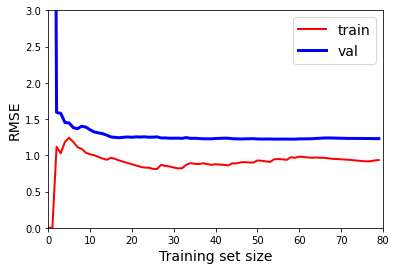 从`Learning Curve`看出,随着样本增加val不断下降,对于该数据集而言,当训练集为80时,训练集和测试集误差基本相等。 # 🍒2.正则化 `过拟合`是机器学习中一个非常重要的问题,减少过拟合有很多方法,例如`正则化`、`增加数据`或`early stopping`等对于线性模型而言,正则化通常通过约束模型系数来实现。接下来主要介绍岭回归、Lasso回归、early stopping ## 🍑2.1岭回归 岭回归相对于最小二乘法的优势来源于能通过$\lambda$来权衡偏差方差。随着$\lambda$ 的增加,岭回归拟合的灵活性降低,导致方差减小,但偏差增大。岭回归和最小二乘法估计非常类似,但是最小化的损失函数不同,这里是让下述损失函数最小: $$ \sum_{i=1}^{n}(y_i-\beta_0-\sum_{j=1}^{p}\beta_jx_{ij})^2+\lambda\sum_{j=1}^{p}\beta_j^2=RSS+\lambda\sum_{j=1}^{p}\beta_j^2 $$ $\lambda \geq 0$.其中$\lambda\sum_{j=1}^{p}\beta_j^2$是惩罚项.此时如果$\beta_j$越小,那么损失函数越小,以此来控制回归系数。当$\lambda=0$时,相当于就是普通的线性回归,当$\lambda$接近无穷大时,所有的回归系数均为0.因此对于每一个$\lambda$都会产生一系列不同的回归系数。因此如何选择$\lambda$是一个需要思考的问题,下面我们看看如何实现岭回归 ```python #生成数据集 np.random.seed(42)#设置随机种子,保障代码重用性 m = 20 X = 3 * np.random.rand(m, 1) y = 1 + 0.5 * X + np.random.randn(m, 1) / 1.5 X_new = np.linspace(0, 3, 100).reshape(100, 1) ``` ```python #训练模型 from sklearn.linear_model import Ridge ridge_reg = Ridge(alpha=1, random_state=42) ridge_reg.fit(X, y) ridge_reg.get_params() ``` {'alpha': 1, 'copy_X': True, 'fit_intercept': True, 'max_iter': None, 'normalize': False, 'random_state': 42, 'solver': 'auto', 'tol': 0.001} 上述是我们去alphl=1的情况下的拟合值,但是alpha是一个超参数,我们有时候需要对进行交叉验证等方法来进行选择,下面我们来看一下alphl分别为1,10,100的拟合结果图 ```python : for alpha, style in zip(alphas, ("b-", "g--", "r:")): model = model_class(alpha, **model_kargs) if alpha > 0 else LinearRegression() model.fit(X, y) y_new_regul = model.predict(X_new) lw = 2 if alpha > 0 else 1 plt.plot(X_new, y_new_regul, style, linewidth=lw, label=r"$\alpha = {}$".format(alpha)) plt.plot(X, y, "b.", linewidth=3) plt.legend(loc="upper left", fontsize=15) plt.xlabel("$x_1$", fontsize=18) plt.axis([0, 3, 0, 4]) plt.figure(figsize=(8,4)) plot_model(Ridge, alphas=(0, 10, 100), random_state=42) plt.ylabel("$y$", rotation=0, fontsize=18) plt.savefig("ridge_regression_plot") plt.show() ``` 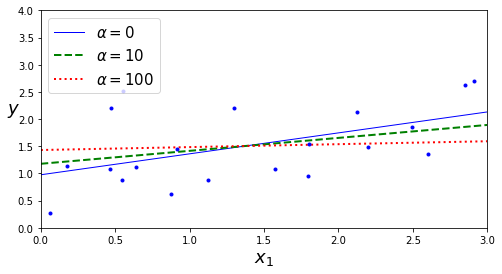 上图是在$\alpha$取不同值的拟合结果,可以发现,当$\alpha$越大,回归曲线越平缓,因为对这些系数的约束越大 ## 🍐2.2 Lasso回归 岭回归确实有一个明显的缺点。岭回归将在最终模型中包含所有预测变量。惩罚项只会让所有的回归系数接近于0,但是不会等于0(除非$\lambda=\infty$)。这对预测准确性来说可能没有影响,但在变量数量相当大的情况下,模型的可解释性有待考量。然后Lasso回归相对而言可以解决这个问题。与岭回归不同的是,Lasso回归可以选择最重要的几个特征拟合模型,可以让某些不重要变量的系数等于零,从而达到降纬的效果,基本公式如下: $$ \sum_{i=1}^{n}(y_i-\beta_0-\sum_{j=1}^{p}\beta_jx_{ij})^2+\lambda\sum_{j=1}^{p}|\beta_j|=RSS+\lambda\sum_{j=1}^{p}|\beta_j| $$ ```python from sklearn.linear_model import Lasso plt.figure(figsize=(8,4)) plot_model(Lasso, alphas=(0, 0.1, 1), random_state=42) plt.ylabel("$y$", rotation=0, fontsize=18) plt.savefig("lasso_regression_plot") plt.show() ``` 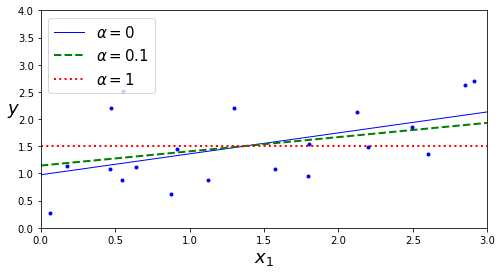 ## 🍏2.3 early stopping 正则化迭代学习算法(如梯度下降)的另一种非常不同的方法是,一旦验证误差达到最小值,就停止训练,被称为`early stopping`该方法通过批量梯度下降进行训练。随着时间的推移,算法学习,训练集上的预测误差(RMSE)和验证集上的预测误差都会下降。但过了一段时间后,验证误差又会上升(导致了过拟合)。这个时候我们可以做的是提取结束训练,当模型不会达到过拟合的程度。也被称为“免费的午餐”,下面我们来看看具体是如何实现的 ```python # 生成数据集 np.random.seed(42) m = 100 X = 6 * np.random.rand(m, 1) - 3 y = 2 + X + 0.5 * X**2 + np.random.randn(m, 1) X_train, X_val, y_train, y_val = train_test_split(X[:50], y[:50].ravel(), test_size=0.5, random_state=10) ``` ```python from copy import deepcopy from sklearn.preprocessing import PolynomialFeatures poly_scaler = Pipeline([ ("poly_features", PolynomialFeatures(degree=90, include_bias=False)),#生成多项式回归 ("std_scaler", StandardScaler()) ]) X_train_poly_scaled = poly_scaler.fit_transform(X_train)#标准化处理 X_val_poly_scaled = poly_scaler.transform(X_val)#标准化 sgd_reg = SGDRegressor(max_iter=1, tol=-np.infty, warm_start=True, penalty=None, learning_rate="constant", eta0=0.0005, random_state=42)#拟合SGD回归 minimum_val_error = float("inf") best_epoch = None#定义最优的迭代次数 best_model = None#定义最优的模型 for epoch in range(1000): sgd_reg.fit(X_train_poly_scaled, y_train) # 拟合模型 y_val_predict = sgd_reg.predict(X_val_poly_scaled)#预测 val_error = mean_squared_error(y_val, y_val_predict)#计算MSE if val_error < minimum_val_error: minimum_val_error = val_error best_epoch = epoch best_model = deepcopy(sgd_reg) best_epoch,best_model ``` (239, SGDRegressor(eta0=0.0005, learning_rate='constant', max_iter=1, penalty=None, random_state=42, tol=-inf, warm_start=True)) 可以看出第239次迭代时,拟合效果最好,下面进行可视化 ```python sgd_reg = SGDRegressor(max_iter=1, tol=-np.infty, warm_start=True, penalty=None, learning_rate="constant", eta0=0.0005, random_state=42) n_epochs = 500 train_errors, val_errors = [], [] for epoch in range(n_epochs): sgd_reg.fit(X_train_poly_scaled, y_train) y_train_predict = sgd_reg.predict(X_train_poly_scaled) y_val_predict = sgd_reg.predict(X_val_poly_scaled) train_errors.append(mean_squared_error(y_train, y_train_predict)) val_errors.append(mean_squared_error(y_val, y_val_predict)) best_epoch = np.argmin(val_errors) best_val_rmse = np.sqrt(val_errors[best_epoch]) plt.annotate('Best model', xy=(best_epoch, best_val_rmse), xytext=(best_epoch, best_val_rmse + 1), ha="center", arrowprops=dict(facecolor='black', shrink=0.05), fontsize=16, ) plt.plot([0, n_epochs], [best_val_rmse, best_val_rmse], "k:", linewidth=2) plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="Validation set") plt.plot(np.sqrt(train_errors), "r--", linewidth=2, label="Training set") plt.legend(loc="upper right", fontsize=14) plt.xlabel("Epoch", fontsize=14) plt.ylabel("RMSE", fontsize=14) plt.savefig("early_stopping_plot") plt.show() ``` 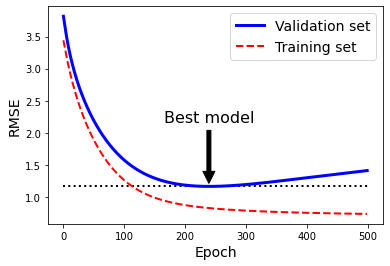 ```python best_epoch, best_model ``` (239, SGDRegressor(eta0=0.0005, learning_rate='constant', max_iter=1, penalty=None, random_state=42, tol=-inf, warm_start=True)) 本章的分享到此结束,下一章将进一步分享广义线性模型:`logistic回归`和`softmax回归`等 本章的介绍到此介绍,如果文章对你有帮助,请多多点赞、收藏、评论、关注支持!! |
