作者简介:周雁波,阿里云资深云储研发工程师,曾就职Intel参与spdk软件研发工作, 《Linux开源存储全栈详解:从Ceph到容器存储》作者之一。
版权声明:本文由周雁波先生授权发表,未经授权请勿转载。
本文主要分享主题在阿里云本地盘存储中,基于Optane SSD和SPDK WSR的功能,降低QLC SSD的写放大。

本地盘是ECS实例所在物理机上的本地硬盘设备。本地盘能够为ECS实例提供本地存储访问能力,具有低时延、高随机IOPS、高吞吐量和高性价比的优势。
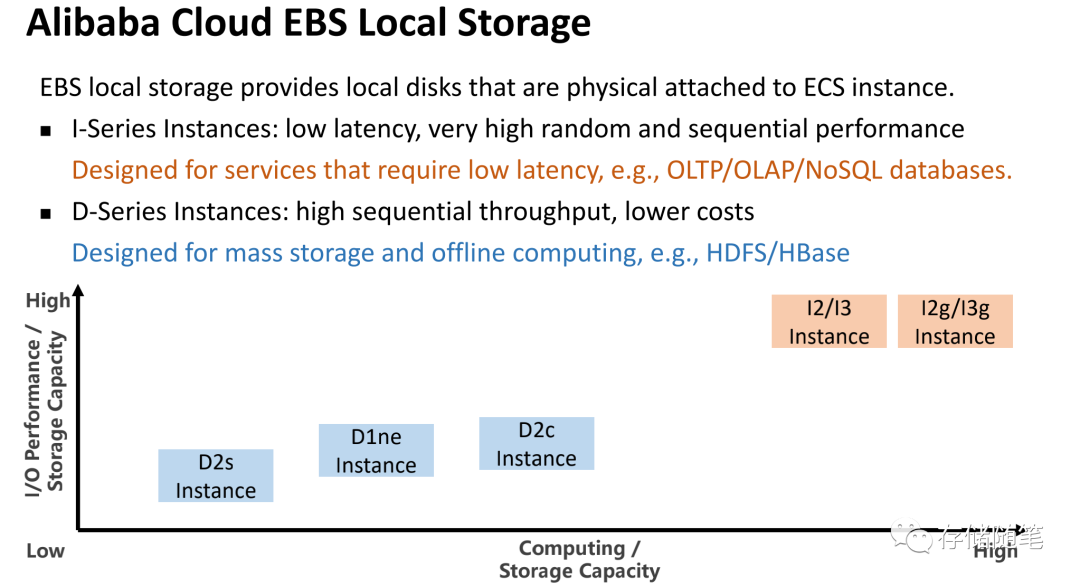
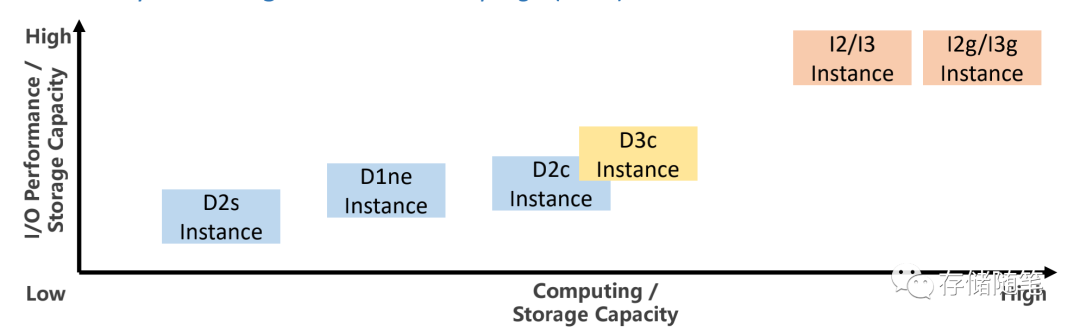
在本地盘会提供两种规格的产品:
- I系列实例:提供低延迟、高随机/顺序性能,适合OLTP/OLAP/NoSQL等数据库场景。
- D系列实例:提供高顺序带宽,低成本,适合HDFS/HBase等海量数据存储场景。

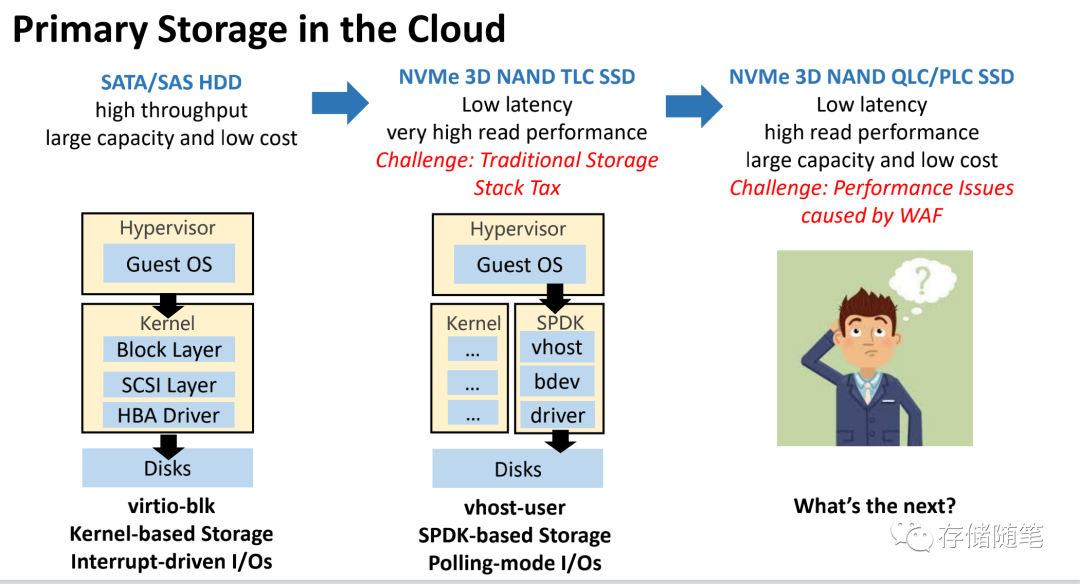
在云存储的演进过程中,有几个阶段:
- 第一阶段:基于SATA/SAS HDD高带宽、大容量、低成本的优势,在内核态virtio-blk虚拟化存储,提供中断响应的IO场景。
- 第二阶段:基于NVME 3D TLC NAND SSD低延迟、高性能的优势,基于SPDK用户态,提供Polling模式的IO场景。解决了基于传统软件栈一些开销
- 第三阶段:随着QLC和PLC SSD的来临,由于大容量低成本的特性,但是性能和寿命却受到写放大的影响。如何解决这个问题,也是本文的重点。
写放大是NAND-based SSD中最让人头疼的因素。主要的根源是操作粒度之间的差异:
- SSD IU(Indriection Unit, 盘内部物理的访问的大小)比用户操作数据块要大。Intel QLC SSD有16K IU和64K IU两个代次。
- SSD擦除的数据块大小比应用层的数据块也要大。
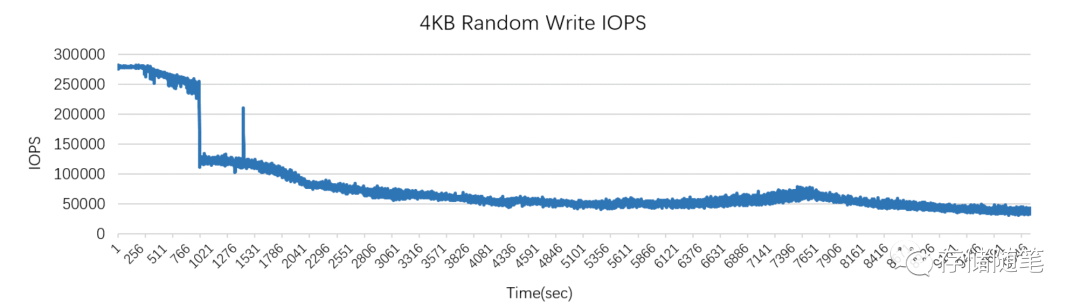
写放大会影响性能和寿命,比如下图,随机写IOPS性能会不断的下降直到一个稳态,此时盘内部的写放大会达到最大。写放大如果太大的话,也会降低SSD的寿命,加速盘的老化。
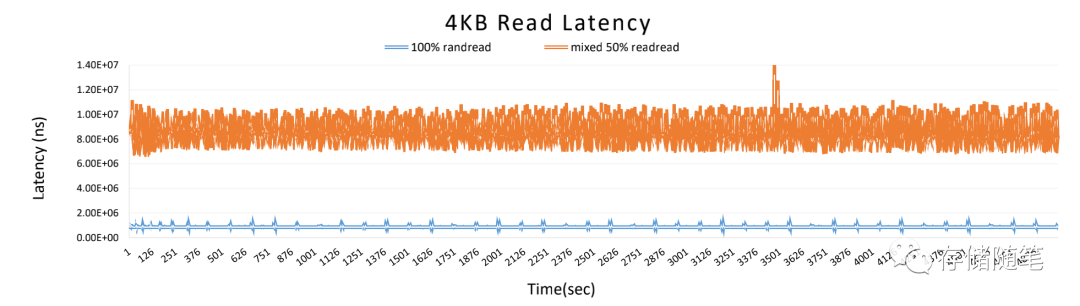
下图中,采用50%混合随机读场景比100%纯随机读场景的延迟要高出一个量级,这里面的原因也主要是GC和写放大对延迟的影响。
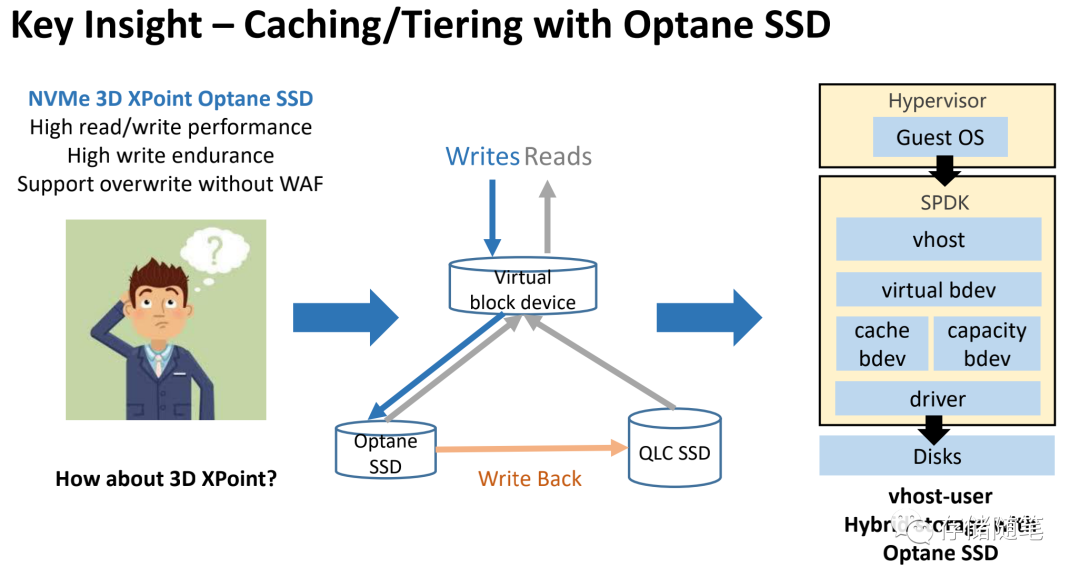
为了解决写放大对QLC SSD性能和寿命的影响,我们采用了基于Optane SSD的缓存和分层存储架构。Optane SSD的优势是高读写性能,高可靠性/耐久性,同时没有类似NAND-SSD因为复写而带来的写放大的影响。作为缓存层是非常理想的选择。
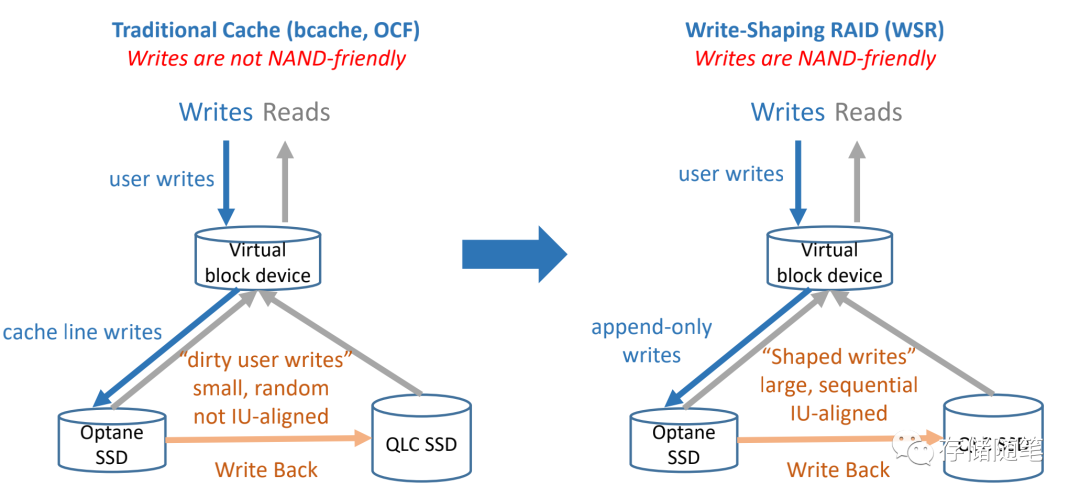
在写过程的IO传输路径中,IO会写到本地盘虚拟块设备中,然后优先落盘到Optane SSD,完成写入响应后,再从Optane SSD中通过聚合/压缩等算法,形成大块顺序写场景,把数据下刷到QLC SSD中,降低写放大。
- 传统的cache缓存改进基于bcache,OCF,对NAND不是很友好的写入。在Optane下刷过程,也不是SSD IU对齐的IO pattern。
- 基于WSR(Write-Shaping RAID)的写入对NAND非常友好,大块写且顺序,同时与SSD IU对齐。这样实现的方式从软件上做了彻底的优化,降低写放大。
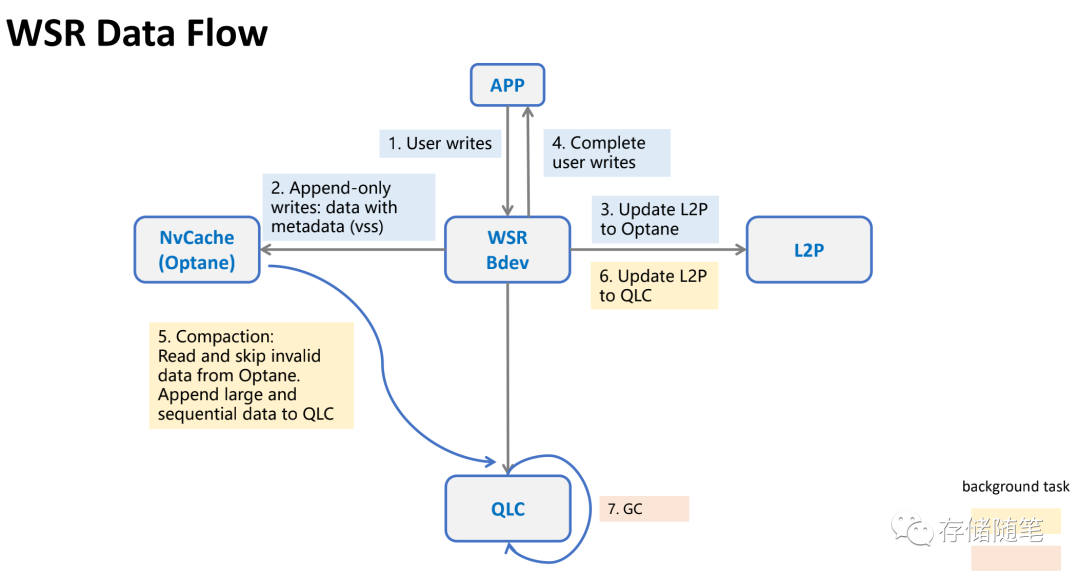
整个WSR的数据流过程,主要有几个步骤:
- 第1步:数据会写写入WSR Bev
- 第2步:通过Append-only追加写的方式,写入数据到Optane SSD,同时基于VSS实现meta的安全校验,保证数据安全性。
- 第3步:更新软件管理的L2P映射表,这里面为了提升效果,热点访问的映射表放在DRAM,其他的放在Optane缓存盘。
- 第4步:通知用户完成写入。到这里跟用户之间的交互就完成了。
- 第5-7步:是后台执行的动作,Optane SSD中通过聚合/压缩等算法,形成大块顺序写场景,把数据下刷到QLC SSD,同时更新QLC对映的L2P映射表。
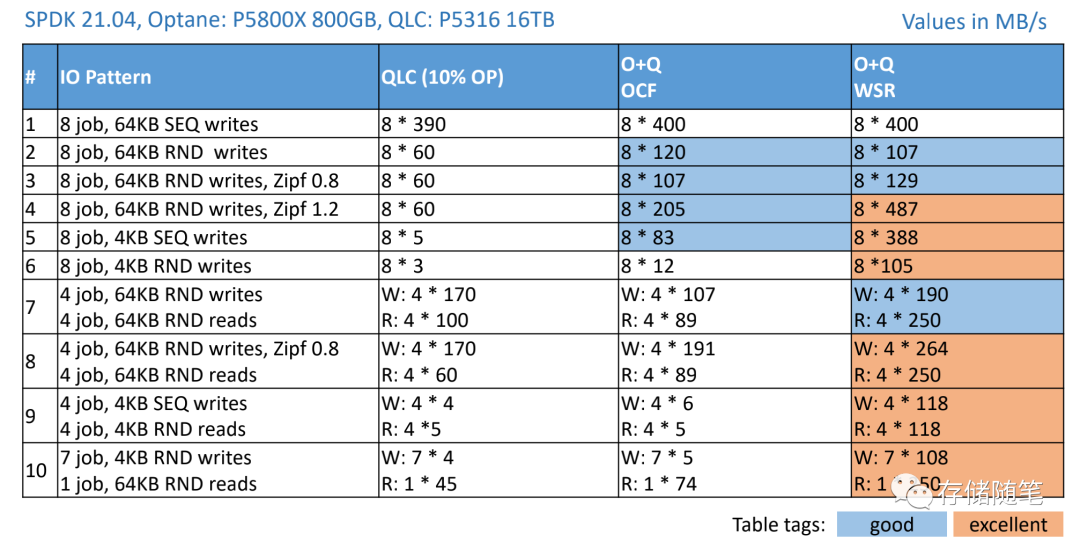
一些软件优化之后,分别针对QLC 10% OP、Optane+QLC & OCF、Optane+QLC & WSR三种场景测试IO性能,测试结果提升明显:
- 特别是#5,#6测试项,针对4K顺序和随机写场景,Optane+QLC & WSR的性能提升2个数量级
- #3,#4测试项中,基于齐普夫定律的反应热频高低,在热点数据场景(Zipf 1.2)中,Optane+QLC & WSR对性能的提升更加优异。
基于Optane+QLC和SPDK WSR的优化能力,在阿里云本盘D3C场景已经实现。