一、LakeHouse演进

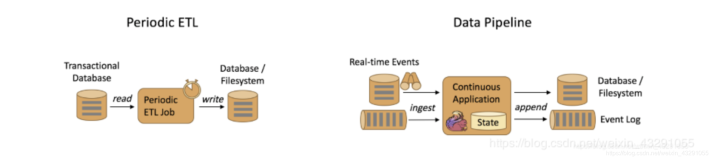
数仓的产品形态已经非常成熟。2012年之前,BI、报表是最主要的私有化部署数仓产品。2012年,Google 提出 BigQuery概念,引爆大数据分析的潮流,其主打特色是 Serverless 架构,同时能够提供非常好的分析性能。
2013年,Amazon云厂商收购了Redshift做数仓产品,目前也是他们最核心的数仓产品形态,主打特色为弹性与智能化分析。2014 年,Snowflake 数仓问世,将资源的扩展性做到极致,存储层能够按对象存储很方便地进行扩容,并将计算层与存储层解耦,实现了存储计算分离的架构和足够的弹性,是一款为云而生的数仓产品。
从是上述演变可见,数仓的演变路线整体是从on frame的产品形态逐渐地往 on cloud、存储计算分离的产品形态演变。
大数据在分析场景一直与数仓存在交集。2000 年左右的Hadoop时代主要解决大数据问题,被称为一代数据库产品。它主要面向搜索以及社交场景,得益于社交媒体的蓬勃发展,数据的时效性、用户画像的分析、各种 BI 分析的需求逐渐出现。
2014年的Spark 计算框架解决了Hadoop界限性的问题,面向的 data science或数据分析的场景,颇具前瞻性。目前, Spark 在 batch 分析领域依然是主流以及事实标准。
随着Uber公司的发展,打车场景下乘客订单之间存在很多状态的变更,尤其是小时级别以内的状态变更、数据的打宽以及数据的实时/近实时变更场景非常多,在这些场景下如何解决增量的消息处理,如何提供高效率的状态变更,如何做增量数据的处理以及高效率的更新等需求不断增加。
2016年,Uber推出了Apache Hudi初代的数据产品的原型。紧接着在2017 年,Databricks公司推出了Delta Lake ,Netflix 公司也推出了Iceberg。
渐渐地我们发现,面向大数据的分析场景与原先的商业化数仓产品的迭代路线越来越靠近,产品边界越来越模糊。数仓的数据体量越来越大,且上云之后对资源的智能化、弹性要求也越来越高。大数据随着数据场景的丰富度以及数据体量的增加,分析型需求越来越丰富,底层对分析的产品形态、存储形态也有了越来越多丰富的诉求。其核心实对时效性和底层存储的事务要求越来越高。
最终,DataBricks公司提出了Lake House的概念,将大数据的产品海量数据的特性与warehouse的廉价存储的特性结合在一起,解决了海量数据的分析和机器学习诉求。
Lakehouse引入湖格式之后,对事务的要求越来越贴近于传统数据库场景,尤其是对事务丰富度的支持和对更新的支持。可以预见,未来 3 到 5 年随着数据湖产品的成熟, Lake House的事务以及用Hudi验会逐渐往 MySQL 等数据库产品靠拢,这也是一代数据湖产品的一次更新与迭代。

Lake House架构的最上层为执行引擎层,包含执行层、优化器层、local cache 层。往下连接到事务层,提供了5个模块的核心组件:
① 事务管理(transaction manager):由组件来管理表的事务,比如块表隔离、异步 tableservice MVCC 的事务并发控制。
② 高效率的索引:将索引做成单独的组件,面对不同的执行引擎会提供不同形式的 index 实现,比如主键索引、二级索引、Data Skipping的多模索引等。
③ Metadata:一部分Metadata可以理解为 index 本身的存储数据;其次Metadata还会保留模块化的内容,比如max-min 的信息辅助 Data Skipping、当前文件视图的文件列表、某些场景下做索引加速会存储bloom filter 信息等;Metadata还包含事务层,比如事务的状态、当前活跃的事务视图集合等,辅助事务的管理。
④ Table Service :它是Hudi区别于 Delta Lake 和Iceberg 的特色。能够将小文件合并、数据的清理或 transaction 的 rollback 做成 MVCC 形式的异步的 service ,在写流程里定期维护数据集,实现自动化治理的状态,这也是Hudi设计的核心。后续我们会将table service 做成独立的 meta server 来维护与管理,以实现更高效的文件布局的优化与资源的协调。
⑤ TableFormat:将 streaming 与 batch 融合到TableFormat ,抽象出micropartition 概念,将文件按照一定的关系划分为不同的micropartition ,并在micropartition 级别对外暴露copy on write 以及 message queue的抽象。Hudi是目前三个流行的湖格式产品里唯一有文件 layout 布局的产品,另外两个产品均只有一层完全展平的文件结构,只能依靠metadata 来维护。这也是Hudi更适合流批统一存储的原因。
Lakehouse架构的最下层为存储层,可以对接HDFS、S3、GoogleCloud 上的对象存储、ABS 存储或他云厂商的对象存储。
整体来看,Lakehouse 与数据库的架构越来越接近,相较于一代的数据库产品,Lakehouse在计算层可以使用多种计算引擎,效率更高;其次在事务层提供了比 Hive 更加丰富的语义,比如ACID 的支持、对更新的支持、对 plugable 索引支持以及对Meta Service的支持,都是 Hive 所不具备的。
二、Apache Hudi架构

Hudi云原生数仓架构如上图所示。
上游提供了非常丰富的数据源摄入方式,可以通过 Binlog的方式streaming 地写入数据库的数据,也可以通过 buckload 的方式将库表里的数据以非常高效的方式转化为Hudi的湖表格式。此外,对 log 数据、来自 Kafka 或消息队列的数据也能提供友好的支持。
总结来看,Hudi支持的数据类型有两种,分别为 log 数据和数据库的 CDCchangelog ;支持的数据形态也包含两种,分别是历史的全量数据以及 streaming 的增量数据。Hudi主打近实时,可通过 streaming 导入的方式将数据摄入的时效性降至分钟级别。
Hudi在中间的计算层的支持也非常丰富。 针对OLAP产品,对于 Presto 、Spark、云厂商的 Redshift、云厂商的流产品等都做了非常深度的集成。因此,分析端也有较多的产品选择,比如Doris、StarRocks等,用户可根据自己的不同需求比如查询场景、性能、成本等自由选择相应的产品。
计算层能够支持 Spark、Flink 以及 Hive 等。比如流分析或增量、消费Hudi上的数据或 streaming 地消费流上的数据,可以选择 Spark streaming或Flink,实现一个表视图能够暴露两种形态;Hive、Spark 等batch引擎高效地做传统的离线任务,也可以实现Kafka架构的streaming 语义,达到分钟级的实时数据消费,做近实时的 BI 场景;可以流读Hudi表,做轻量的加工、聚合,导入到下游的 ADS 层再对接分析引擎,可以在数据的时效性上有数量级的提升,可以将基于 Hive 的 T+ 1 场景提升到分钟级;同时在分析端通过丰富的分析引擎的支持,也能够得到很好的查询效率。目前比较主流的场景多是与streaming 结合的场景,比如数据的实时摄入、端到端的数据实时加工或近实时加工。
对比 Hive 的架构,其优势主要体现在数据的灵活性上。不仅支持batch高效处理,也支持增量处理,这也是Hudi格式的开放性所体现的优势。
ACID事务主要体现在文件格式上的高效率更新。Hudi的框架可以直接将数据库的 changelog、CDC 或 Flink 输出的changelog 写到Hudi表里,可以实时地以行级别的粒度处理 insert、update、delete。对比 Hive 的更新方式,它无需 override 整个 partition,而是以近实时、分钟级 streaming 的方式将变更导入Hudi表里。
另外,Hudi也正在研发增量的 changelog feed。Hudi会输出类似于数据库 changelog 的方式,只要定义好 primary key 即记录数据的变更操作,并以同样的changelog语义暴露给下游的reader 做增量的消费与处理。
这也表明,Lakehouse架构的确与数据库越来越贴近。不仅能够对数据库Binlog 的实时摄入做增量处理,表格式也会暴露类似于数据库的changelog 提供给下游 reader ,同时提供了增量的中间层的数据消费与数据加工。
Hudi的最底层是云原生的架构,因此各个主流云厂商的对象存储或开源的对象存储等的加速层都会主动适配湖表格式。
Hudi在Amazon EMR已经积累了相当数量的用户,国内的阿里云、华为云都会湖产品将陆续推出。目前,整个湖的生态与产品形态正处于快速蓬勃的迭代阶段,达到完全成熟的状态大约还需3-5年的时间。

Hudi云原生架构提供类 DB 事务层。查询引擎层提供非常丰富的支持,能够适配 Spark、Flink、Presto、StarRocks等主流的 batch引擎、流引擎、分析引擎等。平台提供的 service 包括 catalog、Metadata、streaming/batch,能够对不同场景暴露不同的 reader/writer 视图,reader端包括 update、insert、小文件治理,writer端会暴露快照视图、基于时间旅行的增量视图、streaming 消费视图等。
事务层包含一些核心组件,其中Table Format湖表格式的基础功能,比如 scheme evolution 、统计信息的Data Skipping等。此外,Hudi将数据的清理、数据的 compaction 、小文件合并、文件布局的动态优化等封装成了自动化形式。
同时,Hudi的事务项还提供了丰富的 plugable 索引机制,比如基于 Spark ,可能会用 bloomfilter或无状态的 index ,其缺点为受bloomfilter 影响,streaming摄入性能会性能会出现毛刺;比如Flink是基于 state 做了 KV 的索引机制,支持高效率的 update 以及高效率主键索引的点查,对比 bloomfilter 的索引,它的写入更稳定,但同时会有 index 的存储开销;比如bucket index ,它保留了 KV index 的稳定性,同时也有不错的数据写入性能,但缺点为没有 parttaion的更新能力。
并发控制的组件包括 writer 之间的乐观并发控制、writer与 table service 之间的 MVCC 的事务控制,后续也会对MOR表做无锁的并发写入机制,将lock做成 plugable 并提供丰富的 lock 实现,比如会适配amazonDynamoDB 或基于文件系统的锁等,同时也提供接口给用户做定制化的 log 实现。
后续还将实现Lake Cache,包括文件的 cache、基于轻量的表语义的 cache 来加速查询性能。Metaserver功能目前正在推进中,会将 type service 的调度统计信息做成类似于 Hive metastore 的组件,统一进行管理维护。写入端和查询端都能统一对接到 Metaserver上做查询的优化。
在Hudi内部,为了保存 metadata ,会做kv存储。Metadata是Hudi内置的表,存储层为KV 抽象,能够保证较好的点查效率。因此我们对Metadata 表的 format 直接复用了 HFile,因为 HFile提供了不错的行存抽象,行存内部会提供主键的稀疏索引,能够加速 kv的查询效率,单个 key 在 HFile里的查询大约只需50ms。
Hudi云原生架构的最底层是物理存储层,包括对象存储、HDFS 等。
Hudi与另外两个 format 的演化区别在于,另两个 format 更加注重本身的抽象以及 read/writer 抽象;而Hudi更注重的是整个Lakehouse事务平台层的抽象,涉及丰富的场景支持,对事务层的各种组件、元数据的各种组件、plugable 索引的各种支持,并持续朝着数据库产品的形态迭代。

在三个format中,Hudi率先提出 copy onwrite和merge on read 概念。Copy on write主要是为查询端的查询性能优化而做的文件视图,merge on read主要为适配较高的数据新鲜度和较大吞吐的实时摄入场景。因此写入与读取之间会有 trade off ,可能会牺牲一部分的写入吞吐来达到比较高的产品性能,比如 copy on write可能会牺牲一部分查询性能,达到比较高的数据摄入。
Copy on write 思路为:每次对 micropartition 做更新时,会将老的数据复制一份,再append 上新增的数据,merge 在一起成为新的版本,存在一定程度的写放大。但由于 copy onright的bucket 大小可控,micropartition 的文件不会无限增大,因此写放大可控,micropartition的默认大小通常为120M。暴露给 reader 端的快照视图为新的版本,如上图 V2 版本。做 Snapshot 查询只会针对 V2版本进行查询,多次写入会产生多个版本,预留版本数可配置。
Mergeon on Read的思路为:以追加的形式做更新,会追加行存的抽象至micropartition,数据写入时不会再生成新版本。 Compaction 时,会将老版本+追加的数据生成一个新版本。因此,Mergeon on Read查询性能的关键在于compaction,默认情况下五个写入commits压缩一次,可动态调整。此外,也可以通过控制micropartition的大小限制文件无限增大。
相比传统 Hive 的基于文件目录partition的粒度,Hudi以更细粒度进行维护,可以得到更加高效的更新和查询,提高了数据新鲜度和数据增量摄入的效率。Merge on read做compaction 之后的表形态与 copy on write类似。没有 compaction 时做快照查询,会对大版本的列存文件和行存的新增文件进行查询并merge到一起,查询粒度为 micropartition 。
Merge on read 的micropartition 语义能够保序,因此能够保留 micropartition 级别的数据顺序。Streaming reader 也会从micropartition 粒度进行适配,保证了数据的顺序写入和顺序读取,保留了 message queue 的消息消费语义。
总结来说,Hudi既保留了仓的 batch 查询效率,也提供了message queue 的保序能力。
三、Hudi应用场景
Hudi应用场景一:DB数据入仓/湖

传统的数据摄入工具基本只能实现小时级别或 T+1 级别,而DB数据入仓入湖方案可以将数据新鲜度提升到分钟级别,主要有两套实现方案。
方案一:Hudi支持实时摄入changelog 流,可以通过CDC-onnector 无缝对接数据库的数据,将全量+增量的数据实时导入到Hudi。
方案二:规模较大的公司比如字节、美团等,有统一的 message queue,归拢了数据库的changelog ,可以统一使用CDC-format使得 Flink实时地消费 Kafka,将changelog 流导入Hudi。
方案一的优势在于为 Serverless 架构,可以比较方便地将数据库里的全量+新增的数据实时地导到Hudi,同时提供了分钟级别的端到端的数据新鲜度。方案二的优势在于可以利用 message queue的分发属性提供更好的扩展性与稳定性。目前云上用户多选择第一套方案。
Hudi应用场景二:近实时OLAP

近实时OLAP的核心思想为利用Hudi的增量摄入能力,提供分钟级的数据新鲜度,结合下游开放的查询引擎,可以对接 message queue 做数据的实时打宽、轻量的聚合加工等,写入Hudi的湖表格式里,并最终对接分析引擎比如StarRocks、Presto 等。当更新引擎本身对更新的支持不够时,可以用Hudi框架处理更新流,接上更新引擎。如果希望统一仓与 OLAP 的存储层,也可使用该方案。
该方案的优势在于既可以做到分钟级的 streaming 、近实时的数据处理与加工,同时也能够满足一定的查询分析 OLAP 需求。将仓的数据加工与 OLAP 的场景集成到一个存储抽象里,无需进行数据的双写,只用一套存储的抽象完成两个场景的需求。
Hudi应用场景三:近实时ETL

近实时ETL的核心卖点是可以实现端到端的增量 ETL 生产。主要思路为将kafka架构里的 kafka 换成 Hudi,Hudi的format提供了message queue的抽象,可以对数据进行保序,并且能够提供 micropartition 粒度的文件分片以及消息的抽象。因此可以利用 message queue的特性,实时地对Flink的changelog 流进行consume,并进行保存,供下一计算层继续使用,以此实现端到端的增量处理。
该架构的优势在于节省了batch调度,同时提供了不错的端到端的数据新鲜度以及稳定性。目前,产品的成熟度比如数据运维依然有所欠缺,比如中间链路失败后进行容灾恢复的成本较高。消费历史数据场景下,batch的计算形式相比于流join更高效,流的优势主要在于消费增量的部分。可以通过增量的 ETL 的生产导入到湖表格式里,再对接其他的应用场景,比如导出到 ES 、service 、MySQL 等。导出形式也非常多样,可以使用 streaming ,也可以使用 batch 增量拉取。
四、Pulsar&Hudi

Pulsar与Hudi的结合目前正在研发中。成熟之后,Pulsar将可以覆盖毫秒、秒级、分钟级、小时级、天级等场景,Hudi将可以覆盖分钟级以上场景。Pulsar+Hudi的组合可以解决流的时效性问题,同时也能解决数据长期存储的成本问题,比如可以将在 streaming 实时数仓的生态系统将对时效性要求比较高的数据存到Pulsar里,将冷数据或历史数据保存到Hudi format 里。基于此,Pulsar+Hudi的组合能够覆盖从毫秒到无穷大时域的大数据生态与场景。
此外,每个场景的计算层面都会有对应的计算引擎或产品,这也是生态开放性的体现。
有了Pulsar,实时湖仓的解决方案可从近实时升级为实时,既覆盖了传统的毫秒级别的实时场景,也覆盖了仓的主流场景,非常值得期待。
Q&A
Q:详细叙述metadata 与 index 的功能。
A:index 目前提供的主要是写入端的主键索引,会给每个文件构建主键索引,用于描述主键到文件句柄的 mapping 关系,从而实现行级别的写入,即实现了行级的更新能力。每一个key 的生命周期的所有变更都必须在一个 micropartition 里,通过主键索引的方式维护了 key 与 microposition的对应关系。 0.1 版本开始已经支持了与metadata结合的多模索引,会在写入过程中记录每一个文件、每一个 column 的 max-min 值、bloomfilter 值。多模索引面向查询端,在查询时会利用多模索引做 Data Skipping,比如利用查询里的filter 过滤以及 max-min 多模索引提前将需要扫描的文件列表做一层过滤,使得查询性能得到数量级的提升。
Metadata分为两个方面。其中,Hudi为了做事务的多版本和状态控制,提出了 timeline 的概念。 timeline 里每一个事务对应一个 instance,instance里记录了Metadata,Metadata 里会记录事务的基础信息,比如事务写的文件数、新增的消息数量、更新的消息数量等。
另外,在写入的过程中如果想要做查询加速,可开启多模索引记录额外的信息,比如bloomfilter 、行存的每一个 column 的 max-min,并将信息写入 metadata 表里。
Q:Data Source 与Lake Storage 的界限在哪里?
A:Lake House对上层暴露的接口分为两种形态,分别为 API的方式和经典的 SQL 方式。
如果将Lake Storage理解为数据湖产品,则数据库产品本身已经暴露了 data source 的能力;如果将 Lake Storag 定义为物理存储,比如云厂商的对象存储或开源的 HDFS,则界限即在于数据湖提供的能力,比如对查询引擎的适配以及事务层丰富的支持。