# -*- coding:utf-8 -*- # @Time : 2019-10-23 # @Author : carl_dj import xlrd from Interface_python3.public import config from Interface_python3.public.log import Log class ReadExcel(object): # 参数excel_path是文件的绝对路径,sheet_name是表名 def __init__(self, excel_path, sheet_name="Sheet1"): self.data = xlrd.open_workbook(excel_path) # 根据路径打开一个文件 self.table = self.data.sheet_by_name(sheet_name) # 根据表名打开表 self.keys = self.table.row_values(0) # 获取第一行作为字典的key值 self.rowNum = self.table.nrows # 获取总行数 self.colNum = self.table.ncols # 获取总列数 self.log = Log("读取excel").get_logger() # 获取整张表的数据(数据装在列表中,列表的每个子元素是字典类型数据) def get_dict_data(self): if self.rowNum <= 1: self.log.error('xlsx表的总行数小于1') else: r = [] # 定义列表变量,把读取的每行数据拼接到此列表中 for row in range(1, self.rowNum): # 对行进行循环读取数据,从第二行开始 s = {} # 定义字典变量 s['rowNum'] = row + 1 # 存储行数,从第二行开始读,行数等于下标加1 values = self.table.row_values(row) # 获取行的数据 for col in range(0, self.colNum): # 对列进行循环读取数据 cell_value = values[col] if isinstance(cell_value, (int, float)): # 判断读取数据是否是整型或浮点型 cell_value = int(cell_value) # 是,数据转换为整数 s[self.keys[col]] = str(cell_value).strip() # 获取到单元格数据(去掉头尾空格)和key组成键对值 r.append(s) # 把获取到行的数据装入r列表中 return r # 返回整个表的数据 if __name__ == "__main__": file_path = config.test_data_path + 'test.xlsx' sheetName = "test" sheet = ReadExcel(file_path, sheetName) data = sheet.get_dict_data() print(data[0]['checkpoint']) print(type(data[0]['checkpoint'])) print(data)
接口自动化框架(Python)之 四,读取exlce表格
2022-11-01
108
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
接口自动化框架(Python)之 四,读取exlce表格

目录
相关文章
|
28天前
|
人工智能
搜索推荐
数据管理
|
27天前
|
数据处理
索引
Python
用Python实现数据录入、追加、数据校验并生成表格
本示例展示了如何使用Python和Pandas库实现学生期末考试成绩的数据录入、追加和校验,并生成Excel表格。首先通过`pip install pandas openpyxl`安装所需库,然后定义列名、检查并读取现有数据、用户输入数据、数据校验及保存至Excel文件。程序支持成绩范围验证,确保数据准确性。
75
14
14
|
9天前
|
Python
自动化微信朋友圈:Python脚本实现自动发布动态
本文介绍如何使用Python脚本自动化发布微信朋友圈动态,节省手动输入的时间。主要依赖`pyautogui`、`time`、`pyperclip`等库,通过模拟鼠标和键盘操作实现自动发布。代码涵盖打开微信、定位朋友圈、准备输入框、模拟打字等功能。虽然该方法能提高效率,但需注意可能违反微信使用条款,存在风险。定期更新脚本以适应微信界面变化也很重要。
106
60
61
|
5天前
|
人工智能
编解码
自然语言处理
AGUVIS:指导模型实现 GUI 自动化训练框架,结合视觉-语言模型进行训练,实现跨平台自主 GUI 交互
AGUVIS 是香港大学与 Salesforce 联合推出的纯视觉 GUI 自动化框架,能够在多种平台上实现自主 GUI 交互,结合显式规划和推理,提升复杂数字环境中的导航和交互能力。
34
8
8

|
15天前
|
人工智能
Linux
API
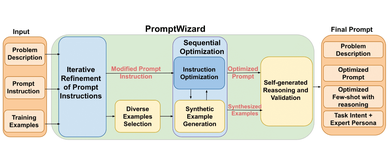
PromptWizard:微软开源 AI 提示词自动化优化框架,能够迭代优化提示指令和上下文示例,提升 LLMs 特定任务的表现
PromptWizard 是微软开源的 AI 提示词自动化优化框架,通过自我演变和自我适应机制,迭代优化提示指令和上下文示例,提升大型语言模型(LLMs)在特定任务中的表现。本文详细介绍了 PromptWizard 的主要功能、技术原理以及如何运行该框架。
103
8
9
|
3天前
|
存储
测试技术
API
pytest接口自动化测试框架搭建
通过上述步骤,我们成功搭建了一个基于 `pytest`的接口自动化测试框架。这个框架具备良好的扩展性和可维护性,能够高效地管理和执行API测试。通过封装HTTP请求逻辑、使用 `conftest.py`定义共享资源和前置条件,并利用 `pytest.ini`进行配置管理,可以大幅提高测试的自动化程度和执行效率。希望本文能为您的测试工作提供实用的指导和帮助。
36
15
15
|
11天前
|
数据采集
人工智能
自然语言处理
Midscene.js:AI 驱动的 UI 自动化测试框架,支持自然语言交互,生成可视化报告
Midscene.js 是一款基于 AI 技术的 UI 自动化测试框架,通过自然语言交互简化测试流程,支持动作执行、数据查询和页面断言,提供可视化报告,适用于多种应用场景。
121
1
1

|
3天前
|
安全
前端开发
数据库
Python 语言结合 Flask 框架来实现一个基础的代购商品管理、用户下单等功能的简易系统
这是一个使用 Python 和 Flask 框架实现的简易代购系统示例,涵盖商品管理、用户注册登录、订单创建及查看等功能。通过 SQLAlchemy 进行数据库操作,支持添加商品、展示详情、库存管理等。用户可注册登录并下单,系统会检查库存并记录订单。此代码仅为参考,实际应用需进一步完善,如增强安全性、集成支付接口、优化界面等。
12
1
1
|
21天前
|
JSON
数据可视化
测试技术
python+requests接口自动化框架的实现
通过以上步骤,我们构建了一个基本的Python+Requests接口自动化测试框架。这个框架具有良好的扩展性,可以根据实际需求进行功能扩展和优化。它不仅能提高测试效率,还能保证接口的稳定性和可靠性,为软件质量提供有力保障。
52
7
7
|
18天前
|
分布式计算
大数据
数据处理
技术评测:MaxCompute MaxFrame——阿里云自研分布式计算框架的Python编程接口
随着大数据和人工智能技术的发展,数据处理的需求日益增长。阿里云推出的MaxCompute MaxFrame(简称“MaxFrame”)是一个专为Python开发者设计的分布式计算框架,它不仅支持Python编程接口,还能直接利用MaxCompute的云原生大数据计算资源和服务。本文将通过一系列最佳实践测评,探讨MaxFrame在分布式Pandas处理以及大语言模型数据处理场景中的表现,并分析其在实际工作中的应用潜力。
57
2
3
热门文章
最新文章
1
智能化软件测试:AI驱动的自动化测试策略与实践####
2
Selenium:强大的 Web 自动化测试工具
3
ChatMCP:基于 MCP 协议开发的 AI 聊天客户端,支持多语言和自动化安装 MCP 服务器
4
探索软件测试中的自动化框架选择####
5
CDP与Selenium相结合——玩转网页端自动化数据采集/爬取程序
6
Agent-E:基于 AutoGen 代理框架构建的 AI 浏览器自动化系统
7
探索软件测试中的自动化测试框架选择与优化策略
8
智能化运维:从自动化到AIOps的演进之路####
9
利用Python自动化处理Excel数据:从基础到进阶####
10
Python脚本:自动化下载视频的日志记录
1
Python中实现类似MATLAB的常用技巧
101
2
python函数
24
3
python学习之变量类型
49
4
python小案例-re正则
52
5
玩转Python的fake-useragent库
308
6
Python Django框架
46
7
python中的SyntaxError: invalid character in identifier(语法错误:标识符中有无效字符)
601
8
python中SyntaxError: unexpected EOF while parsing(语法错误:解析时遇到意外的文件结束)
374
9
Python 多进程日志输出到同一个文件并实现日志回滚
132
10
使用 Python Flask 创建简易文件上传服务
111