1.线性回归闭合形式参数求解的原理
如果定义X为m*(n+1)的矩阵,Y为m1的矩阵,θ为(n+1)1维的矩阵,那么在之前的定义中就可以表示为h(x)=Xθ。则代价函数可以表示为J(θ)=1/2(Xθ-y)Т(Xθ-y),J(θ)为凹函数,我们要让其值最小化,只需对该函数求导,然后令导数为0即可求得θ。对其求导后得到XTXθ-XTy,令其等于0,得到θ=(XTX)^-1XT*y。
2.线性回归梯度下降参数求解的原理
我们构造了拟合函数h(θ),并且得到了损失函数J(θ),我们要求得使J(θ)取得最小值的θ,其原理还是求偏导然后使导数为0,我们对J(θ)求导得到(hθ(x) − y) xj,然后可以得到对θj的更新公式
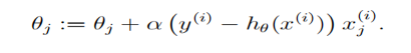
由于数据量较大,所以采用了随机梯度下降,但是准确度相较于批量梯度下降来说会下降。在我的程序里,由于数据采用矩阵形式存储,所以更新过程可以替换为
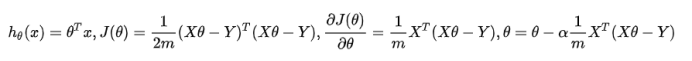
其中θ为(n+1)1维,X为m(n+1)维,Y为m*1维。梯度为0用损失函数差值小于1e-18来表示,说明这个点是损失函数的极小值点,但并不一定是最小值点。
3.相关文件
4.程序清单
相关包:
from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split import pandas as pd import numpy as np import os import time from numpy import median from sklearn.preprocessing import OneHotEncoder
(一)读取数据:
# 读取数据 HOUSE_PATH = './' def load_housing_data(housing_path=HOUSE_PATH): csv_path = os.path.join(housing_path, 'housing.csv') return pd.read_csv(csv_path) housing = load_housing_data()
(二)数据处理:
# 将中位数补全空位 median = housing["total_bedrooms"].median() housing["total_bedrooms"].fillna(median, inplace=True) # 独热编码 housing_category = housing[["ocean_proximity"]] cat_encoder = OneHotEncoder() housing_category_onehot = cat_encoder.fit_transform(housing_category) housing = housing.drop("ocean_proximity", axis=1) housing_values = np.c_[housing.values, housing_category_onehot.toarray()] housing_fixed = pd.DataFrame( housing_values, columns=list(housing.columns) + ['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'], index=housing.index )
(三)分析数据相关性
# 分析数据相关性 corr_matrix = housing_fixed.corr() # 用corr计算两两特征之间的相关性系数 correlation = corr_matrix["median_house_value"].sort_values(ascending=False) # 跟街区价格中位数特征的其他特征的相关系数 print(correlation)
(四)将数据集分类
# 将数据集分类 train_set, test_set = train_test_split( housing_fixed, test_size=0.3, random_state=42) X_train = train_set[['longitude', 'latitude', 'housing_median_age', 'total_rooms', 'total_bedrooms', 'population', 'households', 'median_income', '<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN']] y_train = train_set[["median_house_value"]] X_test = test_set[['longitude', 'latitude', 'housing_median_age', 'total_rooms', 'total_bedrooms', 'population', 'households', 'median_income', '<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN']] y_test = test_set[["median_house_value"]] X = np.hstack([np.ones((len(X_train_std), 1)), X_train_std]) # 训练集X Y = np.array(y_train_std) # 训练集Y x = np.hstack([np.ones((len(X_test_std), 1)), X_test_std]) # 测试集x y = np.array(y_test_std) # 测试集y y_var = np.var(y) # 标准差
(五)特征标准化
# 特征标准化 stdsc = StandardScaler() X_train_std = stdsc.fit_transform(X_train) X_test_std = stdsc.transform(X_test) y_train_std = stdsc.fit_transform(y_train) y_test_std = stdsc.fit_transform(y_test)
(六)初始化θ
theta = np.zeros((14, 1)) # 初始化theta
(七)正规方程
# 正规方程 def nomal(X, Y): theta = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(Y) return theta
# 损失函数 def cost_function(x, theta, y): cost = np.sum((np.dot(x, theta)-y)**2) return cost/(2*len(y)) # 正规方程 def nomal(X, Y): theta = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(Y) return theta # 梯度下降方向 def gradient(X, theta, Y): return X.T.dot((X.dot(theta)-Y))/len(Y) # 梯度下降 def gradient_descent(X, theta, Y, eta): while True: last_theta = theta grad = gradient(X, theta, Y) theta = theta - eta*grad if abs(cost_function(X, last_theta, Y) - cost_function(X, theta, Y)) < 1e-18: break return theta # theta = nomal(X, Y) # 闭合形式求解 theta = gradient_descent(X, theta, Y, 0.001) # 梯度下降 # 评估项(R2) def evaluation(x, theta, y, y_var): return 1 - ((np.sum((np.dot(x, theta)-y)**2))/(y_var*len(y))) MSE = np.sum(np.power((np.dot(x, theta)-y), 2))/len(y) cost = cost_function(x, theta, y) # 损失函数值 R2 = evaluation(x, theta, y, y_var) # 评估值 end = time.time() # print("The normal equations:") print("Gradient descent:") print("theta=") print(theta) print("MSE=", MSE) print("cost=", cost) print("R2=", R2) print('Running time: %s Seconds' % (end-start))
实验结果:
(一)正规方程求解

(二)梯度下降求解

可以看到两个方法得出的结果差别不大,用测试集进行测试时候,损失函数值均为0.18,评估项R²均为0.6多,梯度下降的拟合效果会比正规方程的好一点。在运算过程中,能很明显看到正规方程的计算速度要比梯度下降快很多,原因在于梯度下降在更新θ时候需要迭代很多次才能得到较优解。但是梯度下降在特征数量n较大时也能很好使用,而正规方程需要计算(X*X)-1,如果特征数量太多则运算代价较大因为矩阵的运算时间复杂度为O(n³),而且只适用于线性模型,不适用于逻辑回归模型等其他模型。在这个模型里面,由于特征数量不是很多,因此用正规式求解比较合理。