





暂无个人介绍
2022年08月
 发表了文章
2022-08-28 17:26:35
发表了文章
2022-08-28 17:26:35
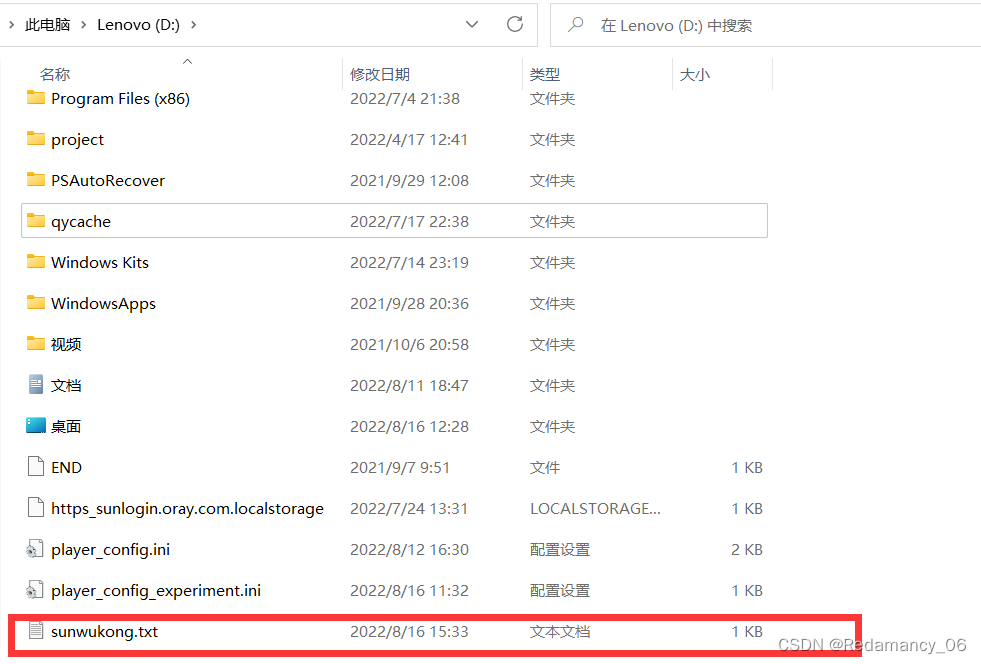 发表了文章
2022-08-28 17:26:02
发表了文章
2022-08-28 17:26:02
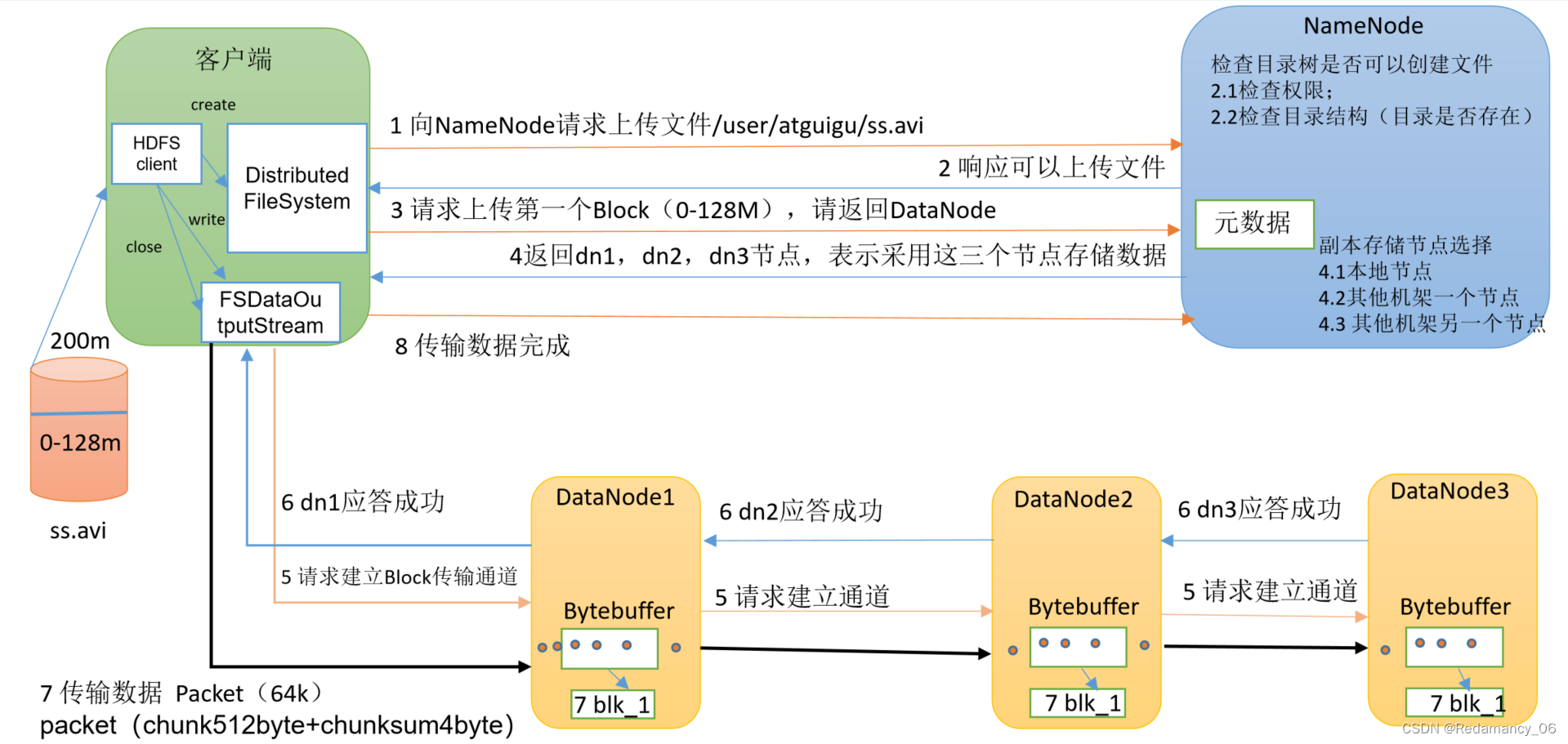 发表了文章
2022-08-28 17:25:27
发表了文章
2022-08-28 17:25:27
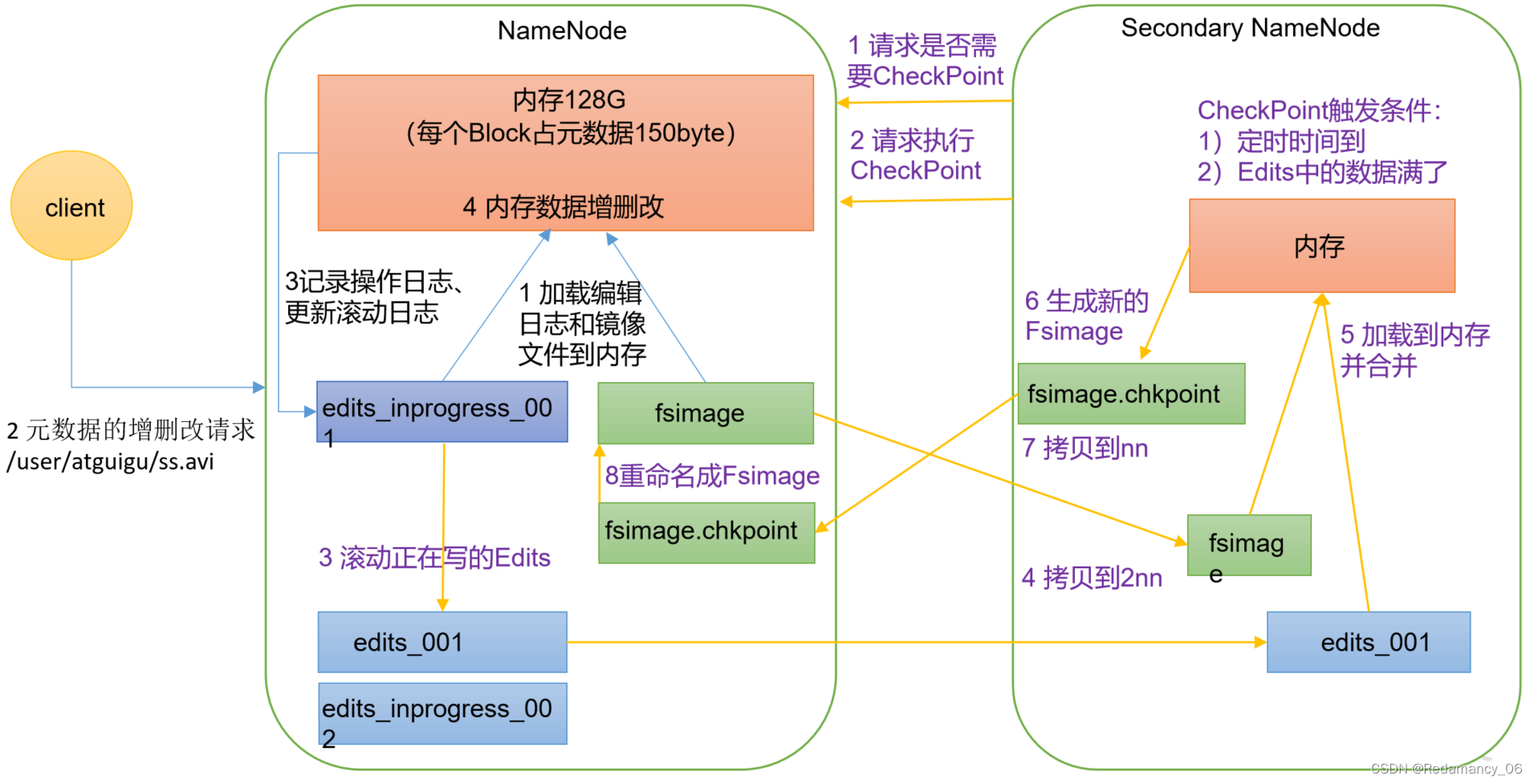 发表了文章
2022-08-28 17:24:51
发表了文章
2022-08-28 17:24:51
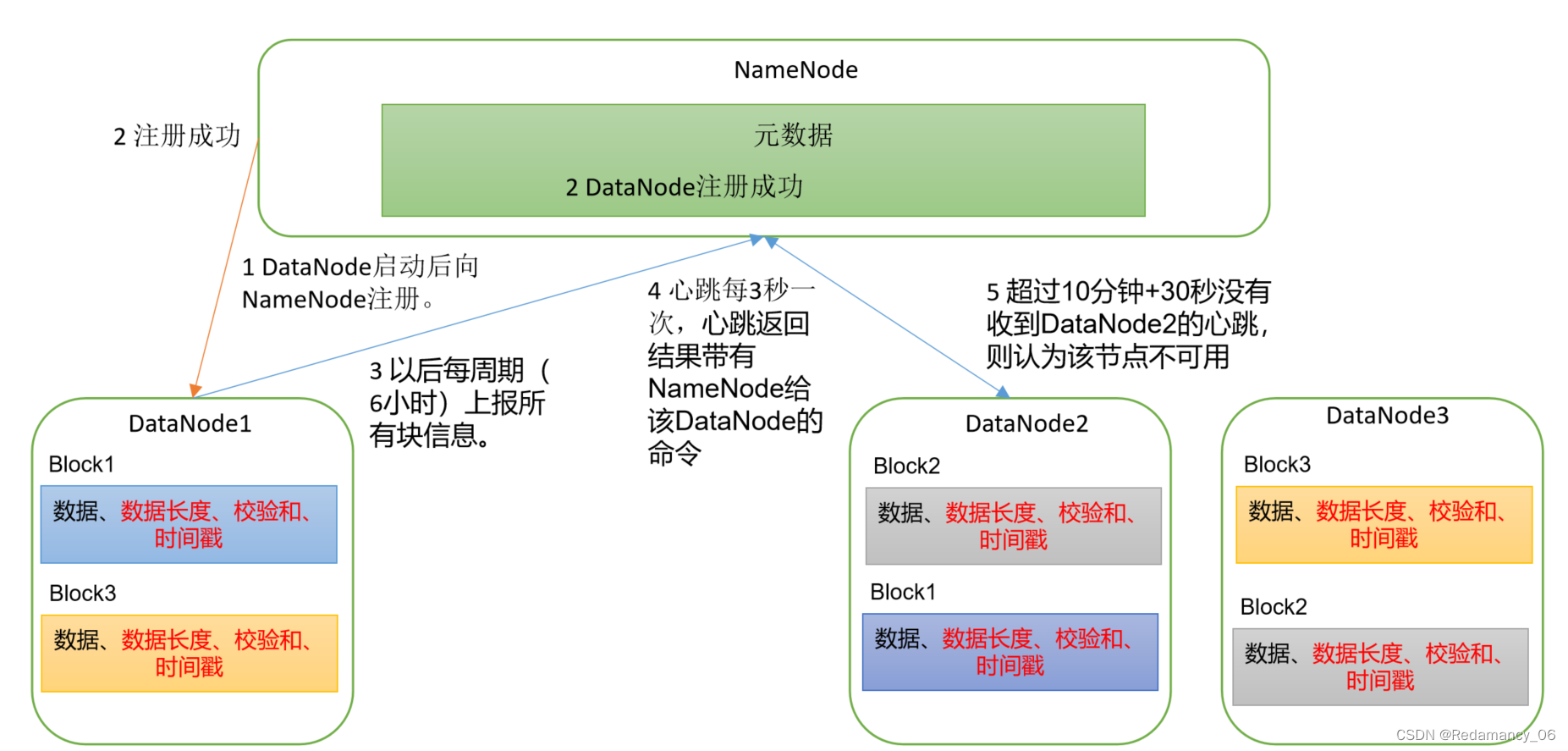 发表了文章
2022-08-28 17:23:45
发表了文章
2022-08-28 17:23:45
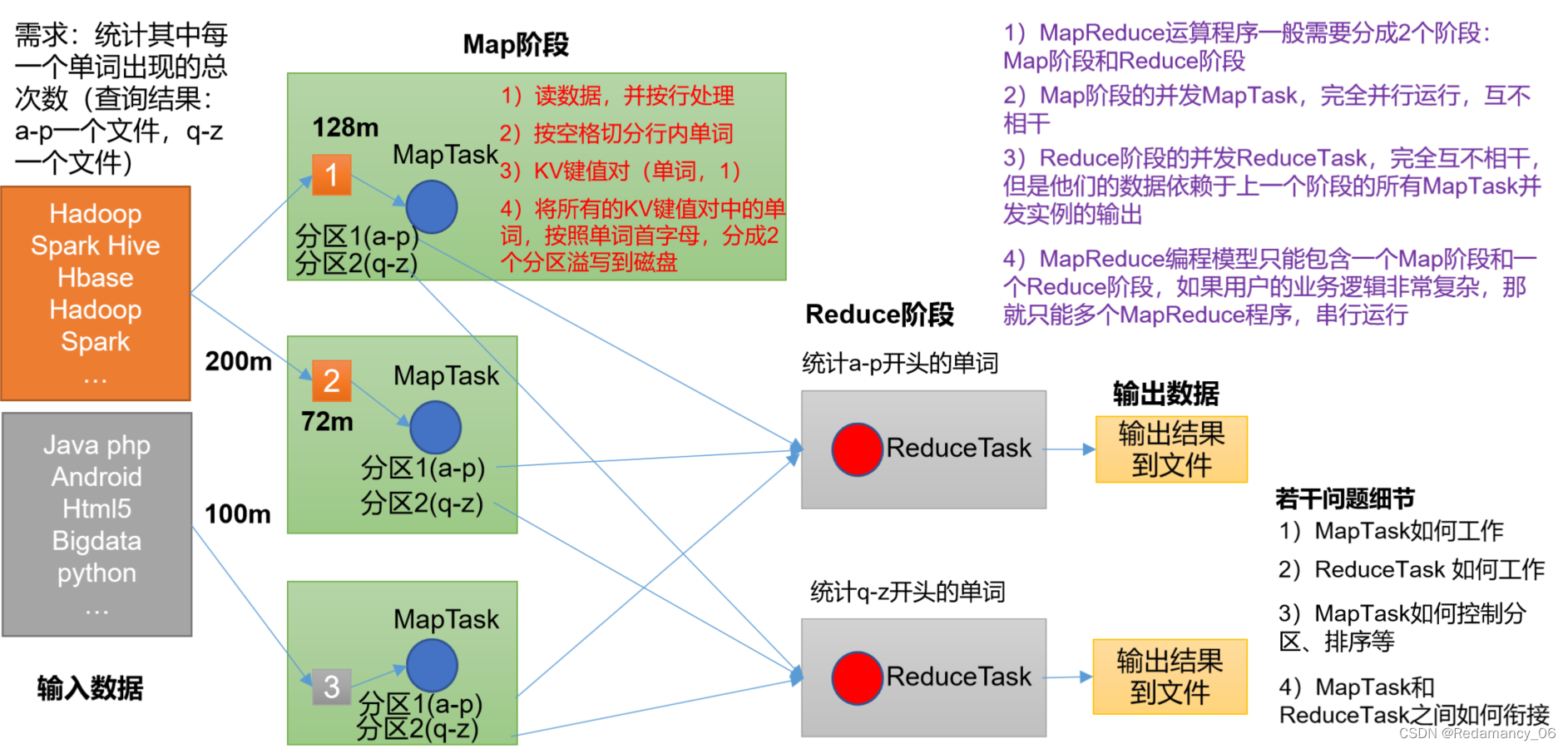 发表了文章
2022-08-28 17:22:56
发表了文章
2022-08-28 17:22:56
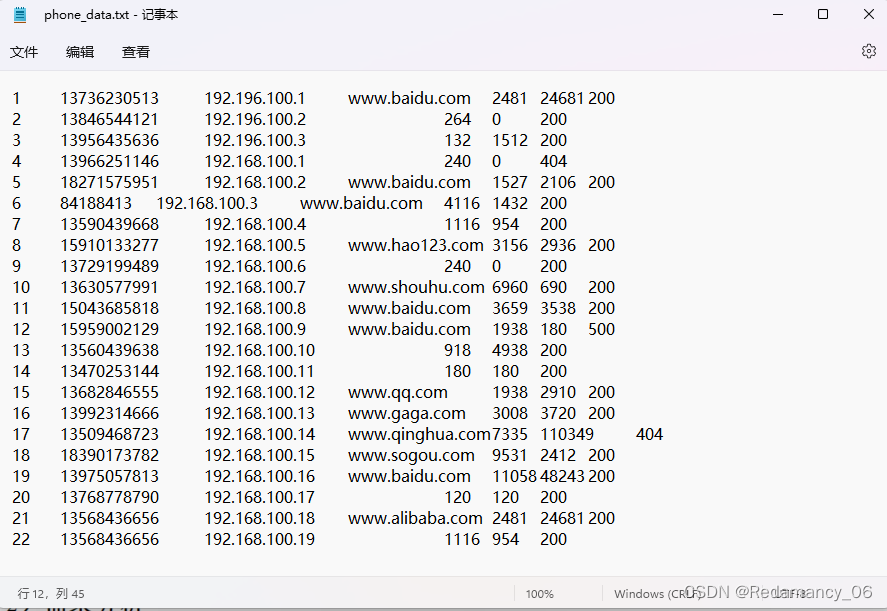 发表了文章
2022-08-28 17:21:05
发表了文章
2022-08-28 17:21:05
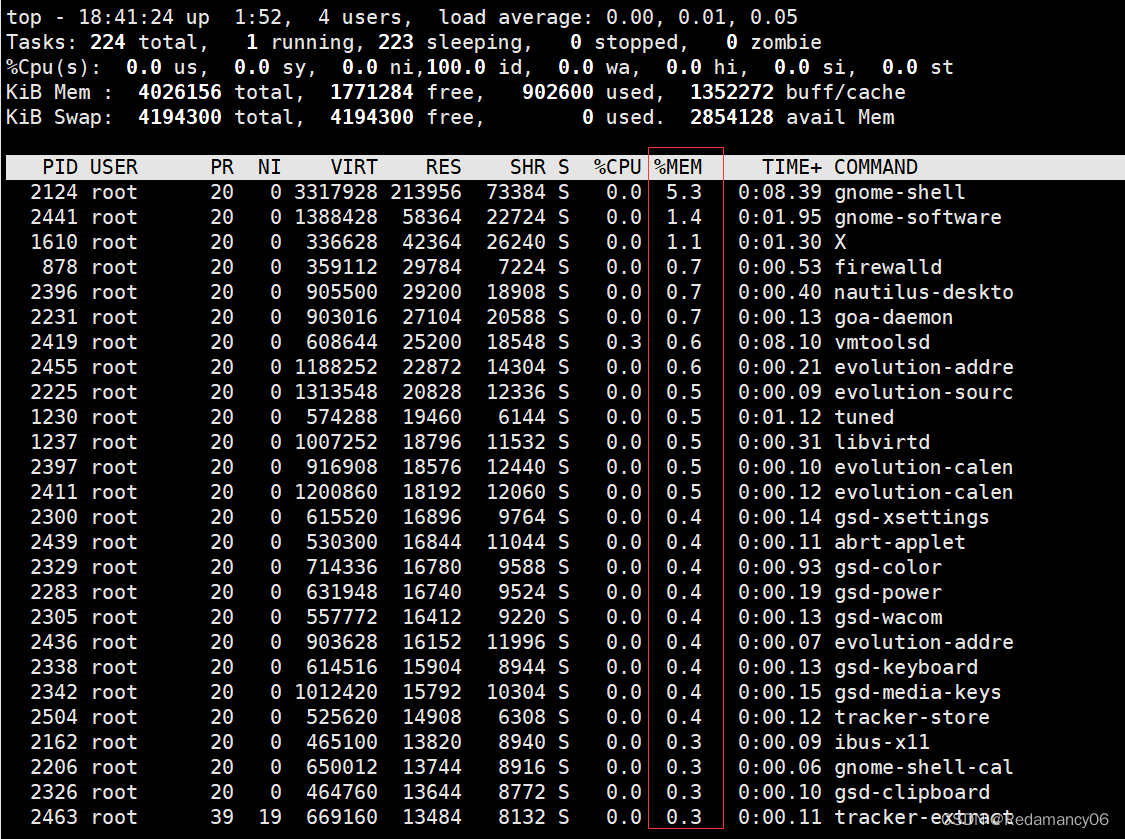 发表了文章
2022-08-28 17:12:27
发表了文章
2022-08-28 17:12:27
 发表了文章
2022-08-28 17:04:56
发表了文章
2022-08-28 17:04:56
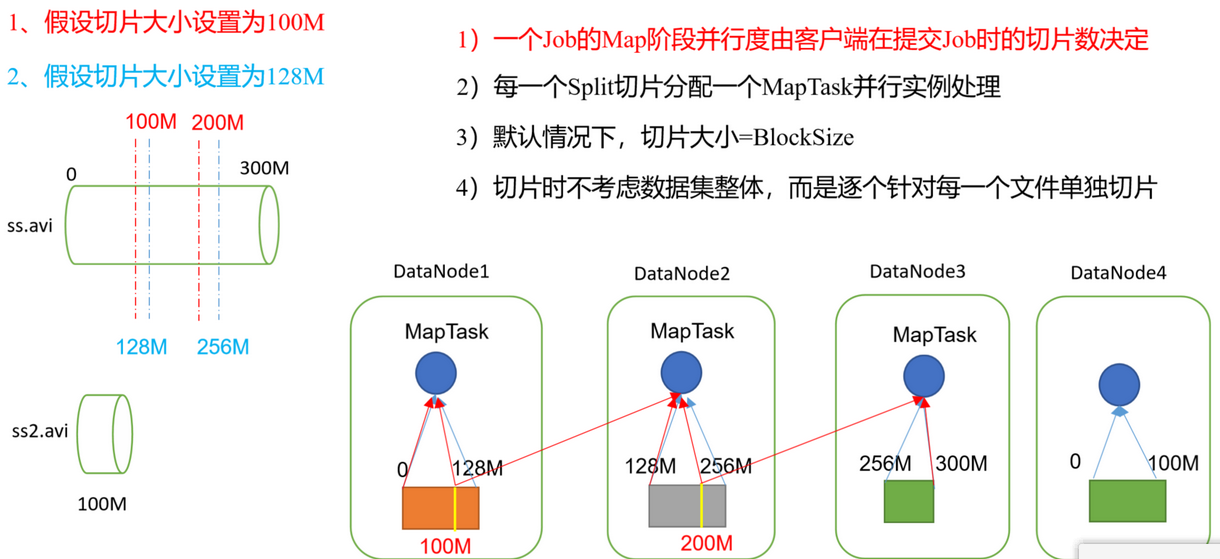 发表了文章
2022-08-28 16:32:14
发表了文章
2022-08-27 16:15:33
发表了文章
2022-08-28 16:32:14
发表了文章
2022-08-27 16:15:33
 发表了文章
2022-08-26 22:26:04
发表了文章
2022-08-26 22:26:04
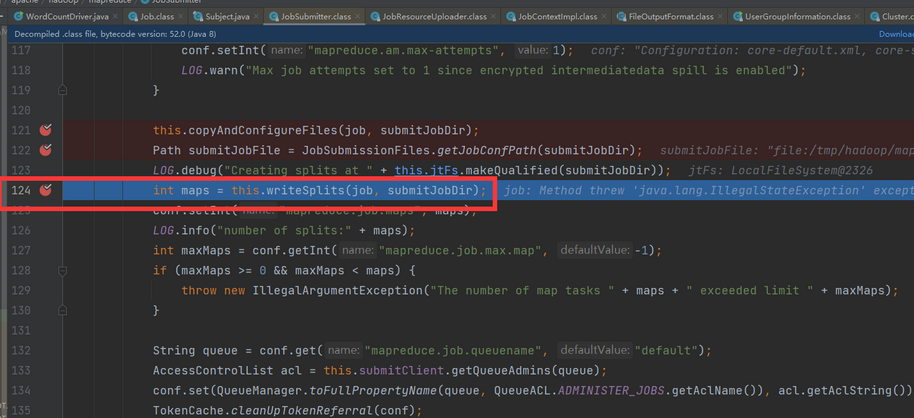 发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28
发表了文章
2022-08-28







