

一枚因为年纪太大而需要经常炒陈饭的人

能力说明:
了解Python语言的基本特性、编程环境的搭建、语法基础、算法基础等,了解Python的基本数据结构,对Python的网络编程与Web开发技术具备初步的知识,了解常用开发框架的基本特性,以及Python爬虫的基础知识。
暂时未有相关云产品技术能力~
阿里云技能认证
详细说明2023年04月
 回答了问题
2023-04-23 20:04:48
回答了问题
2023-04-23 20:04:48
 发表了文章
2023-04-23 19:55:21
发表了文章
2023-04-23 19:55:21
2023年03月
发表了文章
2023-03-28 01:18:47
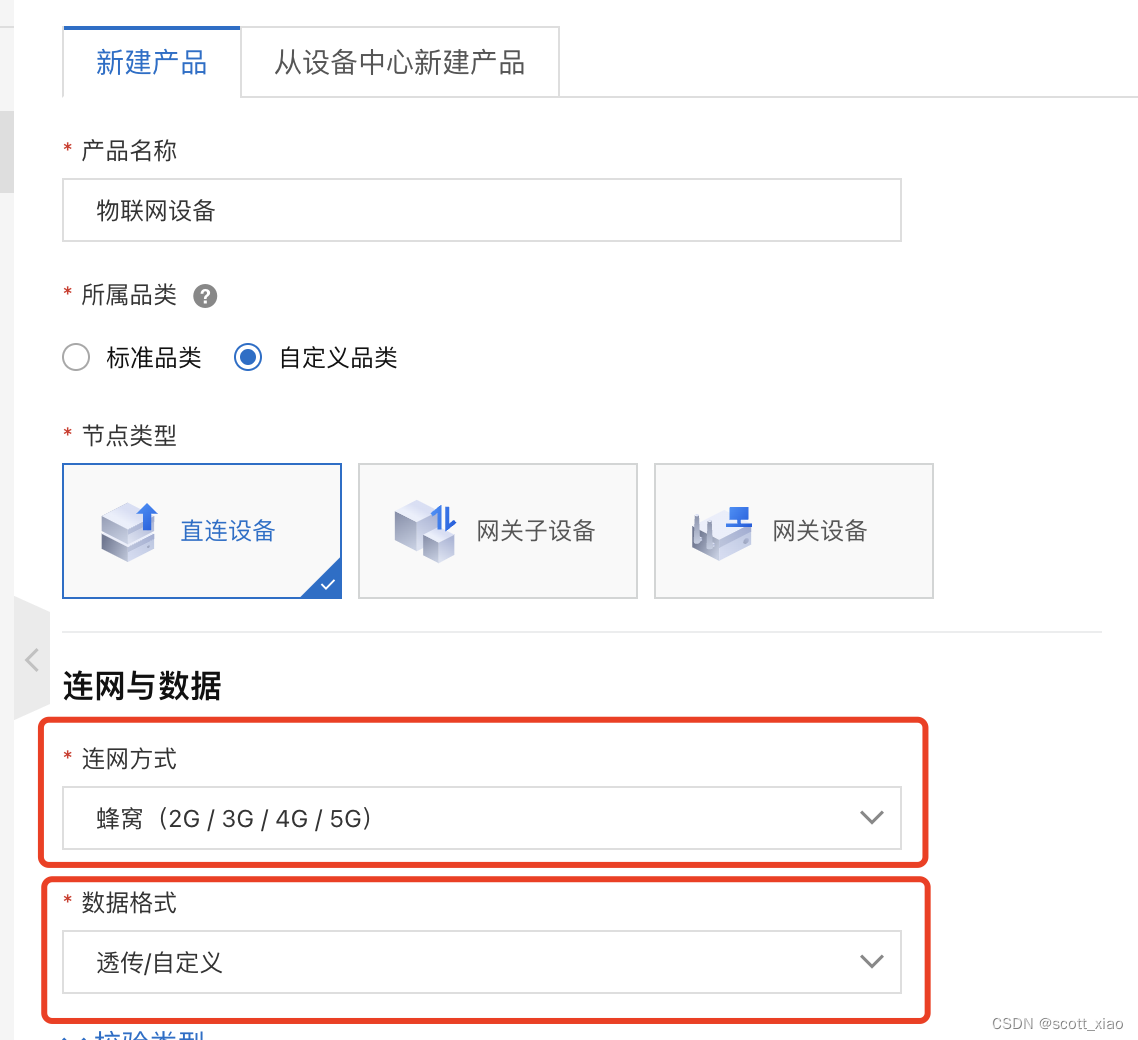
2022年01月
发表了文章
2022-01-14 18:58:52
发表了文章
2022-01-13 14:42:22
发表了文章
2022-01-13 14:13:37
 发表了文章
2022-01-13 10:53:27
发表了文章
2022-01-13 10:53:27
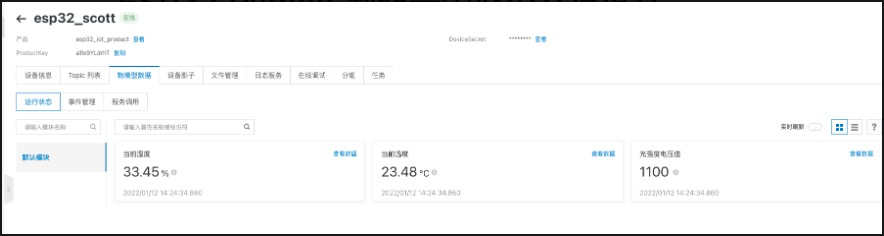 发表了文章
2022-01-13 10:45:35
发表了文章
2022-01-13 10:45:35
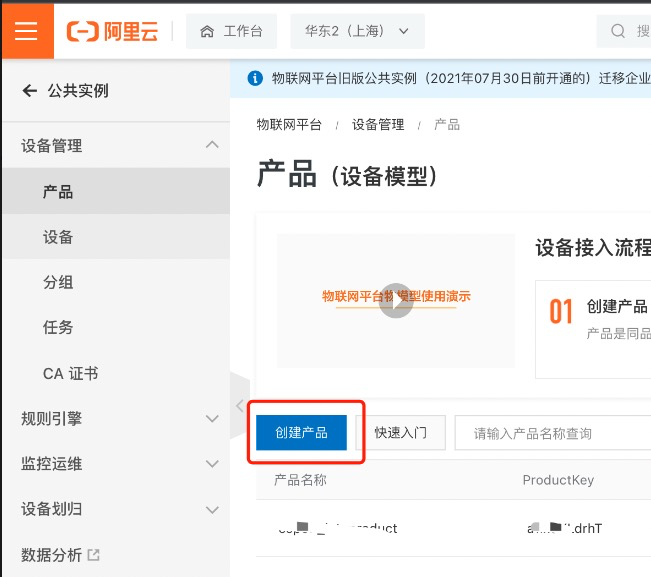 发表了文章
2022-01-13 10:35:16
发表了文章
2022-01-13 10:35:16

2021年11月
发表了文章
2021-11-11 01:18:04
 发表了文章
2021-11-09 23:28:13
发表了文章
2021-11-09 12:07:36
发表了文章
2021-11-09 01:08:42
发表了文章
2021-11-09 23:28:13
发表了文章
2021-11-09 12:07:36
发表了文章
2021-11-09 01:08:42
 发表了文章
2021-11-09 01:03:38
发表了文章
2021-11-09 01:03:38

2019年08月
发表了文章
2019-08-27 13:42:12
发表了文章
2023-04-23
发表了文章
2023-03-28
发表了文章
2022-01-14
发表了文章
2022-01-14
发表了文章
2022-01-13
发表了文章
2022-01-13
发表了文章
2022-01-13
发表了文章
2022-01-13
发表了文章
2022-01-13
发表了文章
2021-11-11
发表了文章
2021-11-09
发表了文章
2021-11-09
发表了文章
2021-11-09
发表了文章
2021-11-09
发表了文章
2019-08-27
发表了文章
2019-02-11
发表了文章
2018-03-13
发表了文章
2018-01-31
发表了文章
2018-01-09
发表了文章
2017-12-21
 回答了问题
2023-04-23
回答了问题
2022-11-29
回答了问题
2018-09-21
回答了问题
2023-04-23
回答了问题
2022-11-29
回答了问题
2018-09-21
