
暂无个人介绍
kafka版本 kafka_2.12-2.2.0.tgz百度网盘链接:https://pan.baidu.com/s/1LAfXpdVg9IKZNGe8OgBgcQ 提取码:sb71 zookeeper配置 vi /usr/local/kafka/config/zookeeper.properties 配置内容:dataDir=/usr/local/kafka/my_dir/zoo
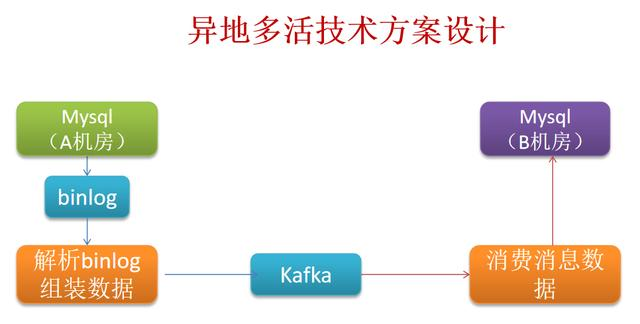 1、解析binlog可以参照使用开源的中间件。 2、Kafka实例demo参见前面Kafka原理-低版本高级api篇。 参照资料: https://www.infoq.c
//定义解析Kakfa message的UDTF CREATE FUNCTION myParse AS 'com.xxxxxx.MyKafkaUDTF'; CREATE FUNCTION myUdf AS 'com.xxxxxxx.MyWaterMarkUDTF'; //注意:kafka源表DDL字段必须与以下例子一致 create table my_input (
//定义解析Kakfa message的UDTF CREATE FUNCTION myParse AS 'com.xxxxxx.MyKafkaUDTF'; CREATE FUNCTION myUdf AS 'com.xxxxxxx.MyWaterMarkUDTF'; //注意:kafka源表DDL字段必须与以下例子一致 create table my_input (
下载Kafka的release包 http://kafka.apache.org/downloads kafka/config/zookeeper.properties配置文件注意 # 注意此处的dataDir和dataLogDir都需要配置(否则可能会出现znode节点写入错误问题)dataDir=/Users/zhangsan/Documents/zookeeper-3.4.8/data
问题描述: 文本分类计算:假设文章类别分为多个类别,每个类别都有自己的关键词信息。如何给新的文本归类?如何修正每个类别的文章信息? 解决思路: 1、文本切词(IKAnalyzer开源):借助于开源切词工具对文本做切词(注:如果项目用到了ES,需要排包,否则,有lucene的jar包冲突)。 <dependency> <groupId>com.janeluo
爬取网站,采用流程节点,用来处理摘要计算、关键字计算、相似度计算、热度计算。数据经过流程计算以后,落库,建立倒排索引。搜索根据关键词到倒排索引表可以快速搜索。 实现步骤 1.基础工作:收集一些网址,作为爬虫的入口。种子url表结构: { “_id” : ObjectId(“c54c4352310b3c”), “urlId” : “io563784uiodf7e96bb9i
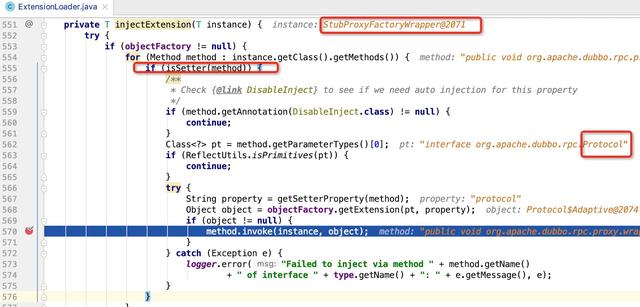
 说说看,你觉得这个在多线程并发的情况下会有问题吗?  ExtensionLoader +时间部分(年月日时分)+序列号(redis获取自增),由于考虑到分布式环境下不同机房的时间钟可能不一致,所以,统一取redis的key orderId超时时间。 redis超时了以后,新增redis的key。
阿波罗接入场景Demo: [https://github.com/ctripcorp/apollo-use-cases](https://github.com/ctripcorp/apollo-use-cases) 踩坑注意: 1、dubbo接入场景pom依赖jar包存在冲突,zk节点新增找不到class 解决方法:注释掉zookeeper依赖 <!--<dependency
zookeeper01配置文件内容: 文件目录:zookeeper01/conf/zoo.cfg tickTime=2000initLimit=10syncLimit=5dataDir=/Users/zhangsan/Documents/zookeeper01/datadataLogDir=/Users/zhangsan/Documents/zookeeper01/logs clientPo
进入dubbo的provider目录 创建dockerfile文件,文件内容如下: FROM openjdk:8-jre-alpineMAINTAINER luoliangENV DUBBO_IP_TO_REGISTRY 30.208.41.156ENV DUBBO_PORT_TO_REGISTRY 10085ADD target/spider-user-service-provider-1.
随着系统不断的运行,当数据库的数据开始超过千万、上亿时,mysql数据库将承受更大的压力。数据是企业生存的根本,数据库的健康状况将直接决了定企业的竞争力。 解决思路 为了更好的缓解数据库压力,使得系统更高效的运行,落地的解决方案有:1、分库(也叫垂直拆分,即:每个模块对应一个单独的数据库)。2、分表(也叫水平拆分,即:一张表的数据拆分存储到多张表里)。 引入的新问题 1、数
jdk安装https://www.cnblogs.com/yjlch1016/p/8900841.html 下载mysql版本5.6建议到mysql官方下载:https://dev.mysql.com/downloads/mysql/5.6.html#downloads我的百度网盘也可下载:https://pan.baidu.com/s/1etS7z8CsRlyb_FlLSErxYA 提取码:f
数据源在spring加载启动完成之后,需要根据不同的业务场景做动态的切换。 解决思路 1、借助spring提供的抽象类AbstractRoutingDataSource,通过继承抽象类,并覆盖determineCurrentLookupKey方法。 2、增加Aspect环绕服务,在before里面设置好数据源本地线程变量、after之后清理掉数据源本地线程变量。 3、每次获
旧版本高级Api封装: package xxxxxx; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; import java.util.Properties; public class KafkaProducerTest implements Runnable {
随着项目不断的迭代、拆分,项目之间的jar包依赖关系复杂度也是不断的变大,看不懂的编译报错,头大的启动问题都在不断的折磨着我们。 解决jar包管理思路 在这里谈谈我的感受和方法,主要概括为: 1、通过顶层统一的父pom来管理spring的jar包版本号,确保spring的core、context、transaction、web等的版本统一。spring多版本的交叉使用,会引入一些
 提交了问题
2015-12-15
提交了问题
2015-12-15
 发表了文章
2020-02-27
发表了文章
2020-01-17
发表了文章
2020-01-10
发表了文章
2020-01-10
发表了文章
2020-01-10
发表了文章
2020-01-10
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-02-27
发表了文章
2020-01-17
发表了文章
2020-01-10
发表了文章
2020-01-10
发表了文章
2020-01-10
发表了文章
2020-01-10
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-08
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06
发表了文章
2020-01-06


