mush2017

已加入开发者社区1809天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人
粉丝
ltco35lwptxwu
ltco35lwptxwu
游客xwrtegn4umhbm
游客xwrtegn4umhbm
游客kqsikwkpalzii
游客kqsikwkpalzii
游客zyn2vmondifd4
游客zyn2vmondifd4
游客osl3kt3phjkma
游客osl3kt3phjkma
3lr5mdhscc72c
3lr5mdhscc72c
游客tvwsjkukfa54e
游客tvwsjkukfa54e
b7kymnaihfet2
b7kymnaihfet2
c24nsevhmtd7c
c24nsevhmtd7c
1953172209262351
1953172209262351
游客5qsah4n7lqurm
游客5qsah4n7lqurm
游客ffqv27rmejv5i
游客ffqv27rmejv5i
技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2022年01月
-
01.15 20:29:23
 发表了文章
2022-01-15 20:29:23
发表了文章
2022-01-15 20:29:23
20 个笑肚疼的代码片段
20 个笑肚疼的代码片段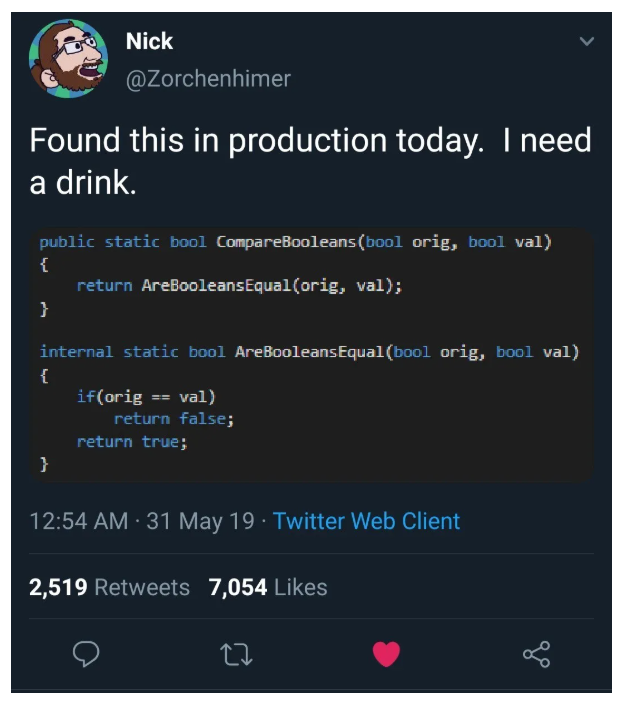
-
01.15 20:20:20发表了文章
2022-01-15 20:20:20
如何保护 Spring Boot 配置文件中的敏感信息
如何保护 Spring Boot 配置文件中的敏感信息 -
01.15 20:18:53发表了文章
2022-01-15 20:18:53
20 个实例玩转 Java 8 Stream
20 个实例玩转 Java 8 Stream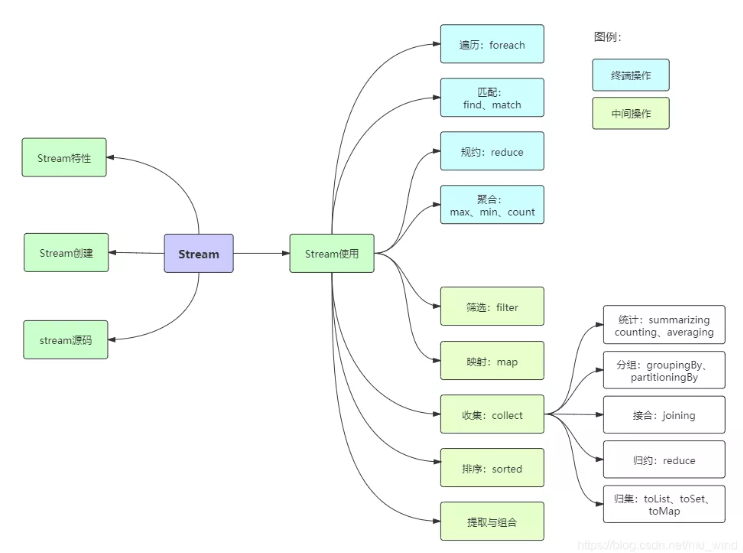
-
01.15 20:13:08发表了文章
2022-01-15 20:13:08
一个由“ YYYY-MM-dd ”引发的惨案 !
一个由“ YYYY-MM-dd ”引发的惨案 !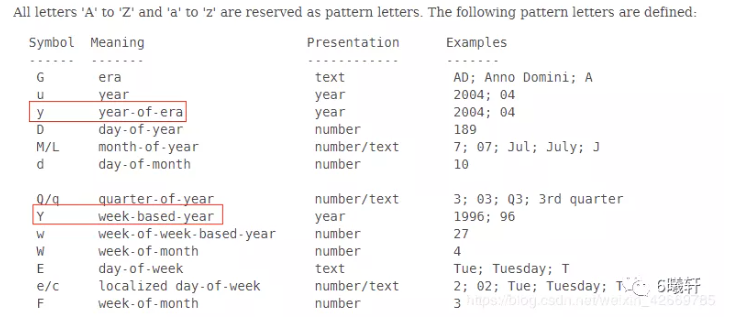
-
01.15 20:12:03发表了文章
2022-01-15 20:12:03
推荐一个 Java 接口快速开发框架
推荐一个 Java 接口快速开发框架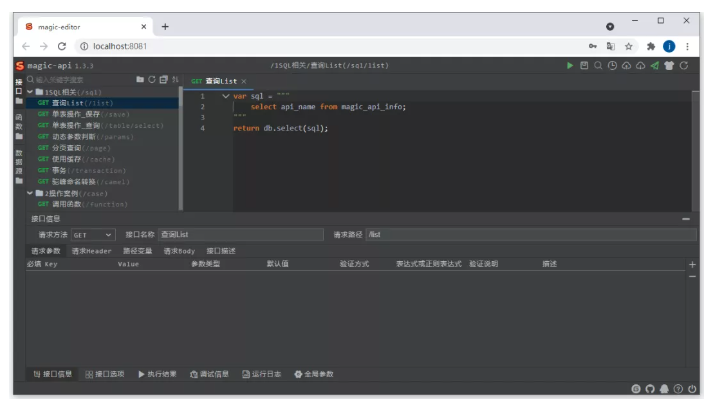
-
01.15 20:09:54发表了文章
2022-01-15 20:09:54
RedisJson 横空出世,性能碾压ES和Mongo!
RedisJson 横空出世,性能碾压ES和Mongo!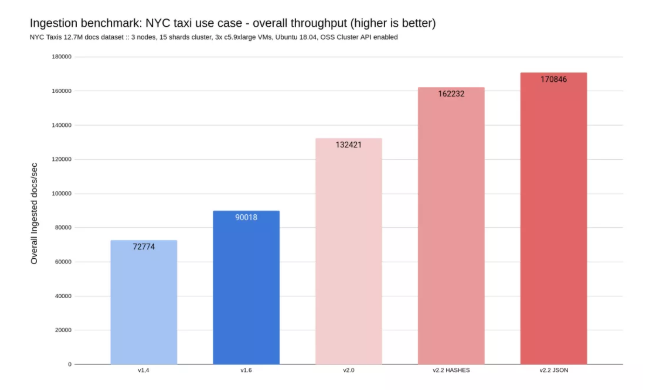
-
01.15 20:05:52发表了文章
2022-01-15 20:05:52
Java 程序员必须掌握的 10 款开源工具!
Java 程序员必须掌握的 10 款开源工具!
-
01.15 20:02:48发表了文章
2022-01-15 20:02:48
IDEA高效使用教程,一劳永逸!
IDEA高效使用教程,一劳永逸!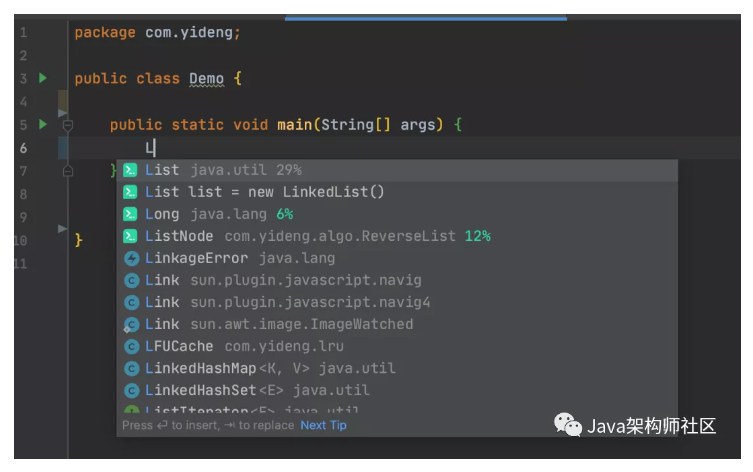
-
01.15 19:56:00发表了文章
2022-01-15 19:56:00
推荐一个分布式JVM监控工具,实惠好用,开源(附源码)!
推荐一个分布式JVM监控工具,实惠好用,开源(附源码)!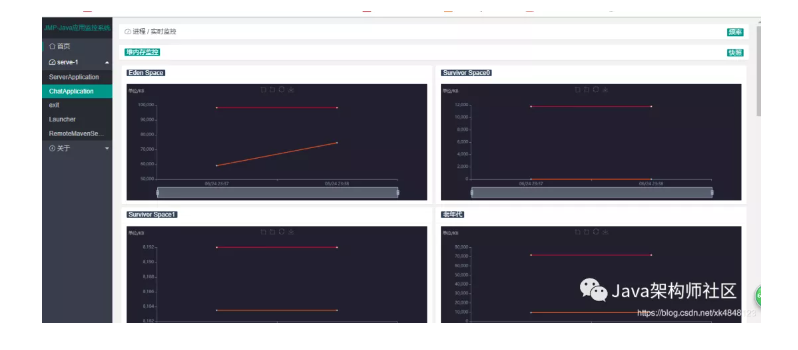
-
01.15 19:52:15发表了文章
2022-01-15 19:52:15
推荐一款 IDEA 插件,多人远程编程 ! 爽
推荐一款 IDEA 插件,多人远程编程 ! 爽
-
01.15 19:48:00发表了文章
2022-01-15 19:48:00
瞬间几千次的重复提交,我用 SpringBoot+Redis 扛住了!
瞬间几千次的重复提交,我用 SpringBoot+Redis 扛住了!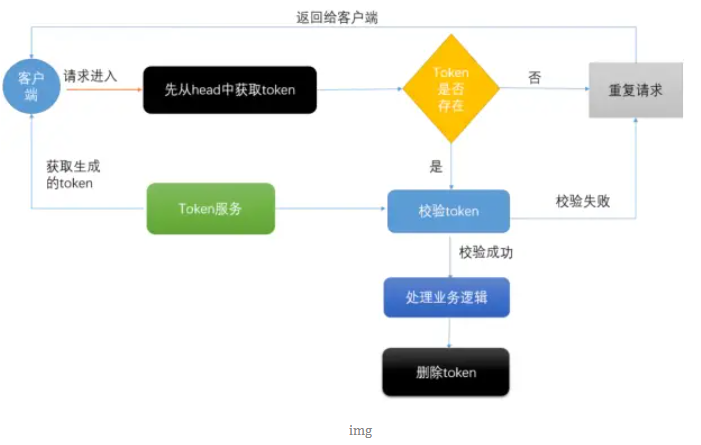
-
01.15 19:43:52发表了文章
2022-01-15 19:43:52
大文件上传:秒传、断点续传、分片上传
大文件上传:秒传、断点续传、分片上传 -
01.15 19:42:22发表了文章
2022-01-15 19:42:22
蛋了,Logback也炸了。。。
蛋了,Logback也炸了。。。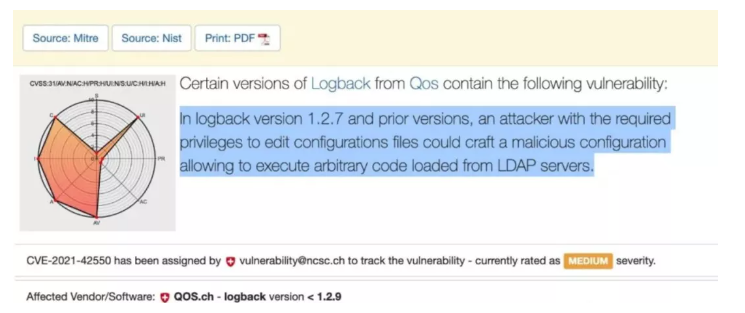
-
01.15 19:40:22发表了文章
2022-01-15 19:40:22
一键生成Springboot & Vue项目! 【毕设神器】
一键生成Springboot & Vue项目! 【毕设神器】
-
01.15 19:34:42发表了文章
2022-01-15 19:34:42
基于 SpringBoot + MyBatis-Plus 的公众号管理系统
基于 SpringBoot + MyBatis-Plus 的公众号管理系统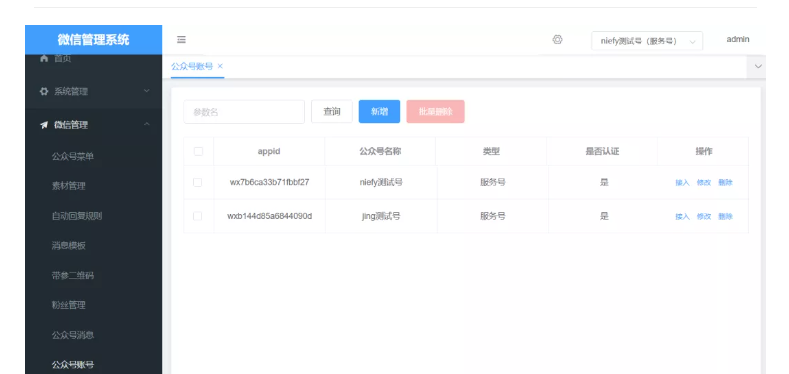
-
01.15 19:33:27发表了文章
2022-01-15 19:33:27
Java 18 就要来了,新功能很多!
Java 18 就要来了,新功能很多! -
01.15 19:32:44发表了文章
2022-01-15 19:32:44
Redis 缓存使用技巧和设计方案
Redis 缓存使用技巧和设计方案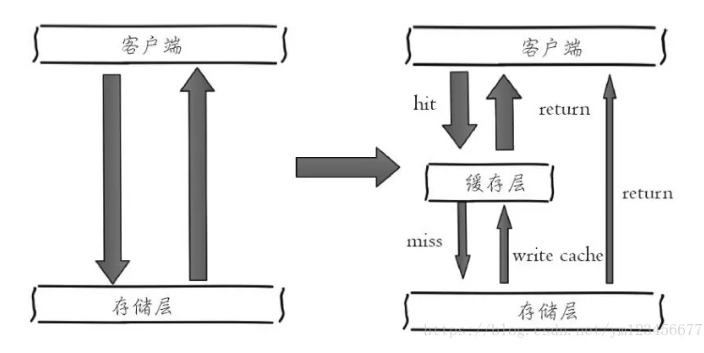
-
01.15 19:28:54发表了文章
2022-01-15 19:28:54
GitHub 上标星 13.4K 的远程软件!太强大了
GitHub 上标星 13.4K 的远程软件!太强大了
-
01.15 19:26:18发表了文章
2022-01-15 19:26:18
IDEA 这个小技巧真的太实用了。。
IDEA 这个小技巧真的太实用了。。
-
01.15 19:23:26发表了文章
2022-01-15 19:23:26
Intellij IDEA 神级插件!效率提升 10 倍!
Intellij IDEA 神级插件!效率提升 10 倍!
-
01.15 19:16:42发表了文章
2022-01-15 19:16:42
创业公司搭建自己的技术架构
创业公司搭建自己的技术架构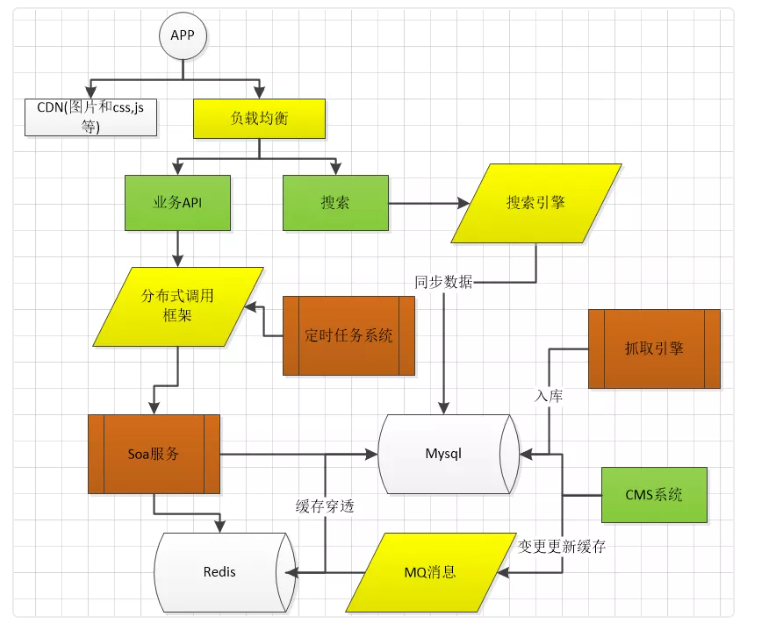
-
01.15 19:15:46发表了文章
2022-01-15 19:15:46
每次这样写 Update 语句,怕是离开除不远了 !
每次这样写 Update 语句,怕是离开除不远了 !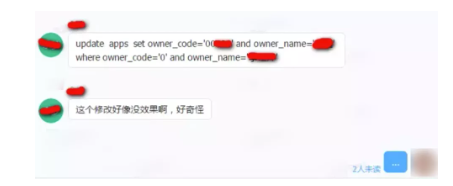
-
01.15 19:11:40发表了文章
2022-01-15 19:11:40
颜值牛逼惨了的swagger-ui
颜值牛逼惨了的swagger-ui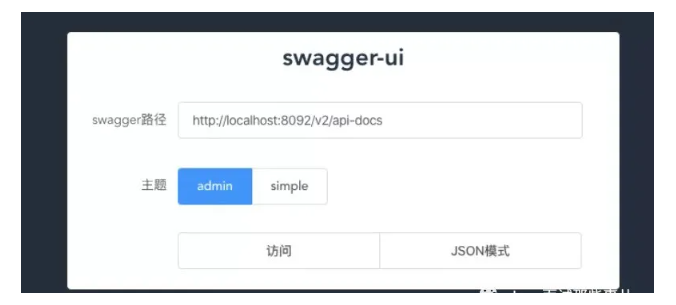
-
01.15 19:05:52发表了文章
2022-01-15 19:05:52
还在用 POI?试试 EasyExcel,轻松导出 100W 数据,不卡死,好用到爆!
还在用 POI?试试 EasyExcel,轻松导出 100W 数据,不卡死,好用到爆! -
01.15 19:00:48发表了文章
2022-01-15 19:00:48
讲透单点登录原理与简单实现
讲透单点登录原理与简单实现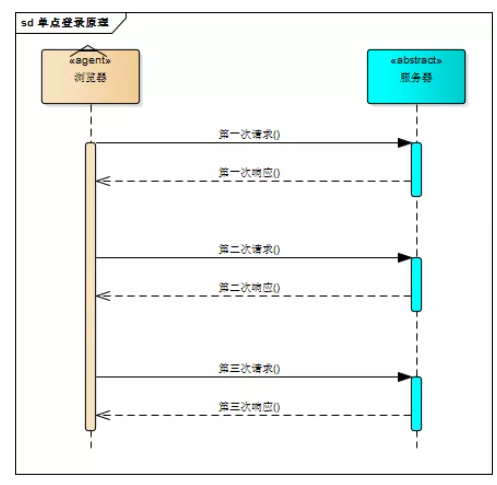
-
01.15 18:18:39发表了文章
2022-01-15 18:18:39
推荐这几个酷到爆的IDEA 主题!帅
推荐这几个酷到爆的IDEA 主题!帅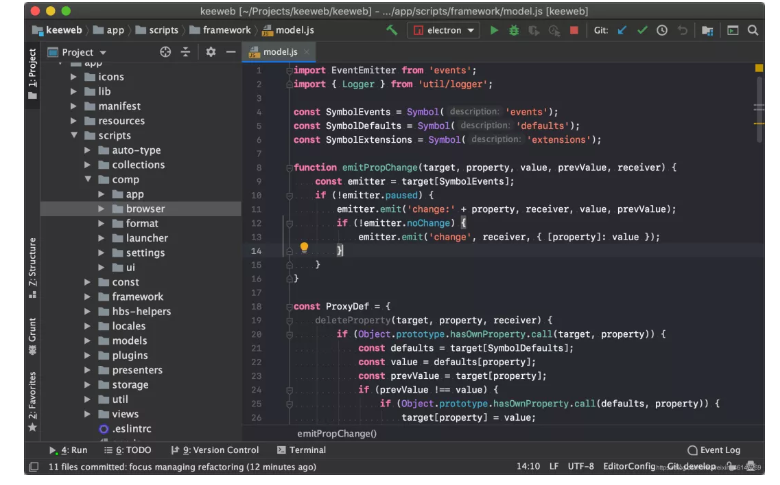
-
01.15 18:15:57发表了文章
2022-01-15 18:15:57
常见内网穿透工具,收好了!
常见内网穿透工具,收好了!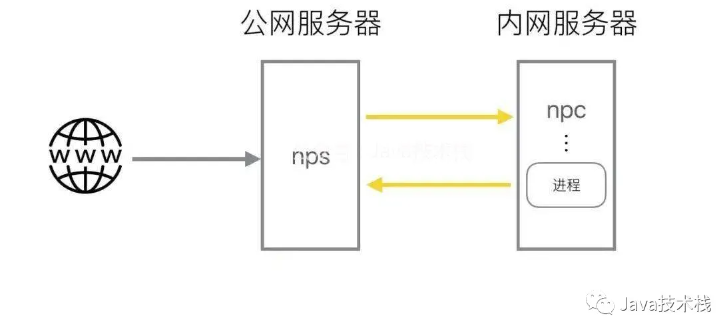
-
01.15 18:11:41发表了文章
2022-01-15 18:11:41
突发!Apache Log4j2 报核弹级漏洞。。赶紧修复!!附解决方法
突发!Apache Log4j2 报核弹级漏洞。。赶紧修复!!附解决方法 -
01.15 18:10:08发表了文章
2022-01-15 18:10:08
12 个非常适合做外包项目的开源后台管理系统
12 个非常适合做外包项目的开源后台管理系统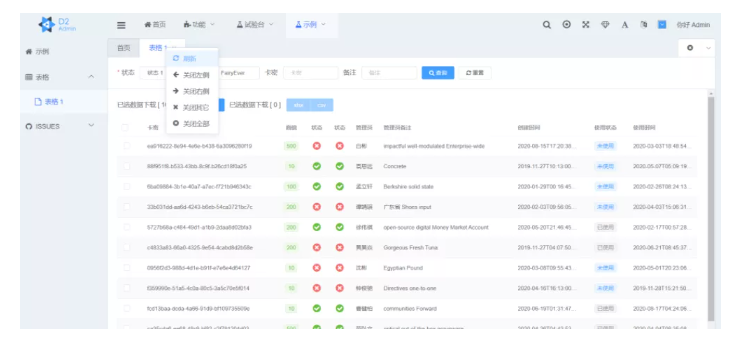
-
01.15 18:07:23发表了文章
2022-01-15 18:07:23
IntelliJ IDEA 详细配置图解,用了这些可能别人叫你秀儿
IntelliJ IDEA 详细配置图解,用了这些可能别人叫你秀儿
-
01.15 17:57:52发表了文章
2022-01-15 17:57:52
Kafka 3.0重磅发布,弃用 Java 8 的支持!
Kafka 3.0重磅发布,弃用 Java 8 的支持!
-
01.15 17:56:22发表了文章
2022-01-15 17:56:22
升级到 MySQL 8.0,付出了惨痛的代价。。
升级到 MySQL 8.0,付出了惨痛的代价。。 -
01.15 17:55:30发表了文章
2022-01-15 17:55:30
Mybatis-Plus 支持分库分表了?-官方神器发布!
Mybatis-Plus 支持分库分表了?-官方神器发布! -
01.15 17:53:58发表了文章
2022-01-15 17:53:58
NetBeans、Eclipse 和 IDEA,哪个才是最优秀的Java IDE?
NetBeans、Eclipse 和 IDEA,哪个才是最优秀的Java IDE?
-
01.15 17:49:26发表了文章
2022-01-15 17:49:26
图解 Spring 循环依赖,写得太好了!
图解 Spring 循环依赖,写得太好了!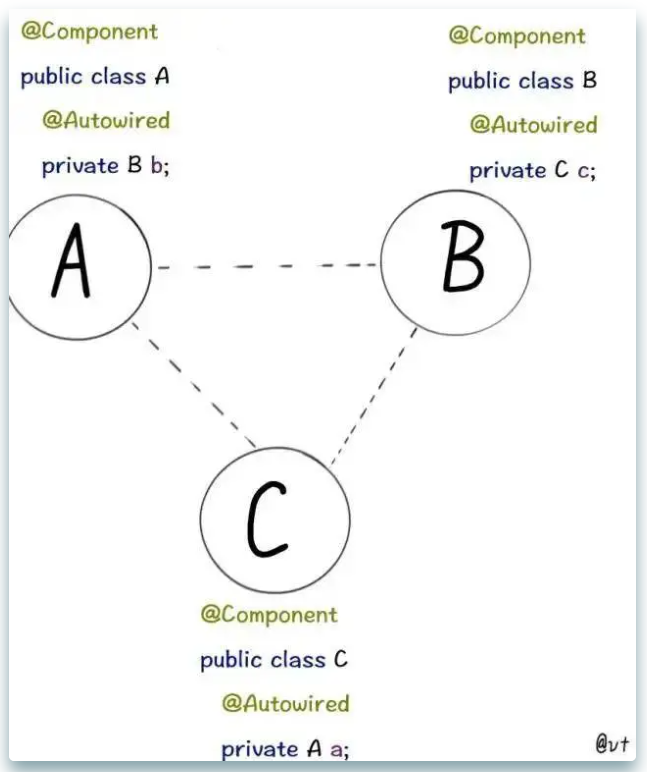
-
01.15 17:41:20发表了文章
2022-01-15 17:41:20
SpringBoot 居然有 44 种应用启动器
SpringBoot 居然有 44 种应用启动器 -
01.15 17:40:01发表了文章
2022-01-15 17:40:01
Spring 为啥默认把 bean 设计成单例的?
Spring 为啥默认把 bean 设计成单例的?
-
01.15 17:37:55发表了文章
2022-01-15 17:37:55
这10个Redis使用技巧,提升90%工作效率(建议收藏)
这10个Redis使用技巧,提升90%工作效率(建议收藏) -
01.15 17:35:38发表了文章
2022-01-15 17:35:38
最牛逼的 Java 日志框架,性能无敌,横扫所有对手.....
最牛逼的 Java 日志框架,性能无敌,横扫所有对手.....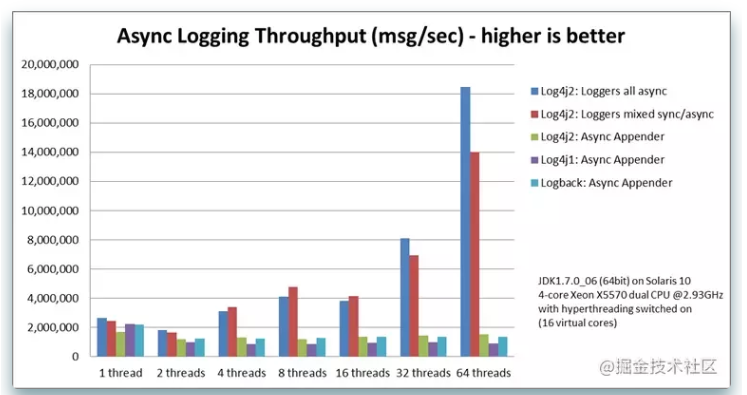
-
01.15 17:33:11发表了文章
2022-01-15 17:33:11
MySQL 8.0 可以操作 JSON 了,牛逼。。。
MySQL 8.0 可以操作 JSON 了,牛逼。。。 -
01.15 17:29:57发表了文章
2022-01-15 17:29:57
什么是分布式系统,如何学习分布式系统?
什么是分布式系统,如何学习分布式系统?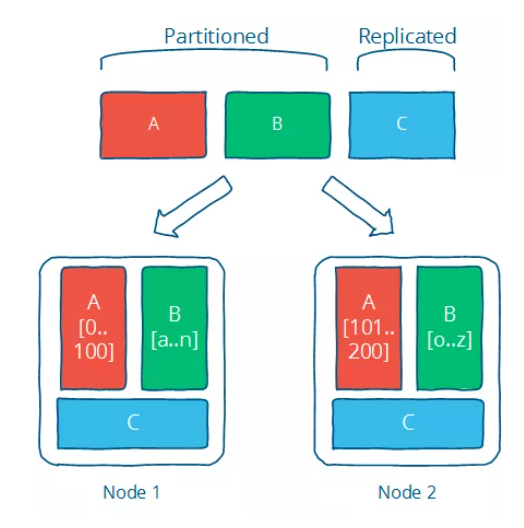
-
01.15 17:26:55发表了文章
2022-01-15 17:26:55
阿里内部“Spring Cloud Alibaba项目文档”正式发布
阿里内部“Spring Cloud Alibaba项目文档”正式发布
-
01.15 17:22:48发表了文章
2022-01-15 17:22:48
面试必需要明白的 Redis 分布式锁实现原理!
面试必需要明白的 Redis 分布式锁实现原理!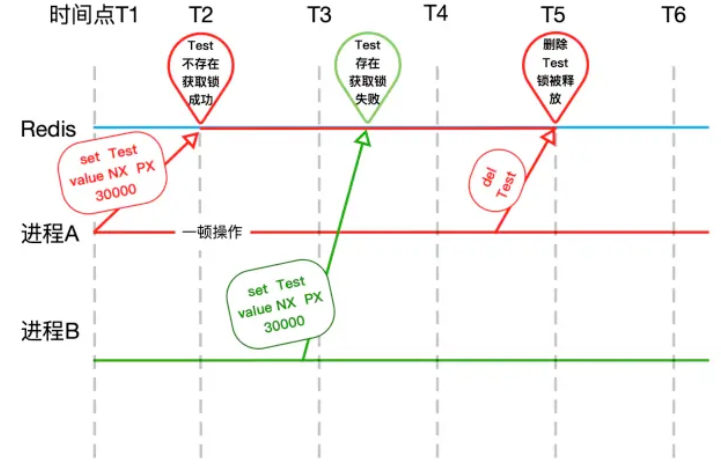
-
01.15 17:16:49发表了文章
2022-01-15 17:16:49
这 4 款 MySQL 调优工具 yyds
这 4 款 MySQL 调优工具 yyds
-
01.15 17:13:16发表了文章
2022-01-15 17:13:16
这28款Chrome高效率插件,你用过哪个?
这28款Chrome高效率插件,你用过哪个?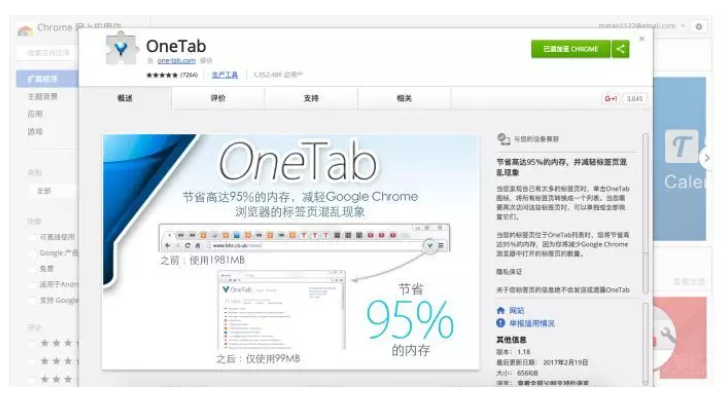
-
01.15 17:04:11发表了文章
2022-01-15 17:04:11
最棒 Spring Boot 干货总结(超详细,建议收藏)
最棒 Spring Boot 干货总结(超详细,建议收藏)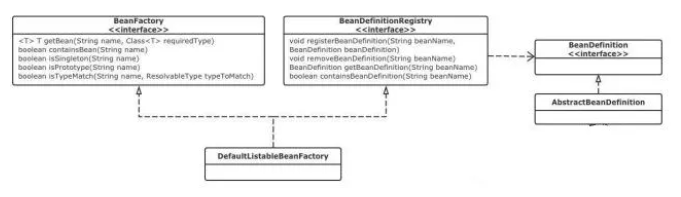
-
01.15 16:58:11发表了文章
2022-01-15 16:58:11
看完这篇还不会SQL优化,算我输。。。
看完这篇还不会SQL优化,算我输。。。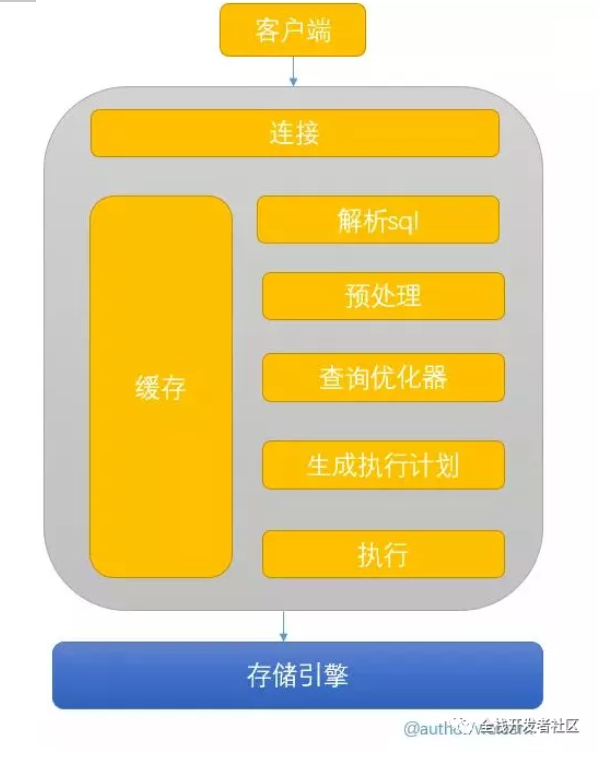
-
01.15 16:55:45发表了文章
2022-01-15 16:55:45
干掉 XML Mapper,新出的 Fluent Mybatis 真香!
干掉 XML Mapper,新出的 Fluent Mybatis 真香!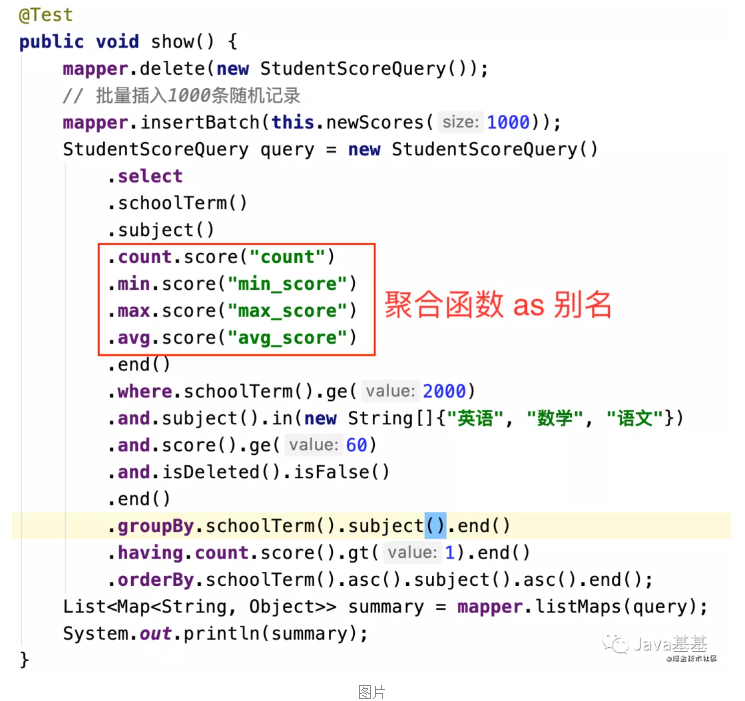
-
01.15 16:54:06发表了文章
2022-01-15 16:54:06
isEmpty 和 isBlank 的用法区别,你都知道吗?
isEmpty 和 isBlank 的用法区别,你都知道吗?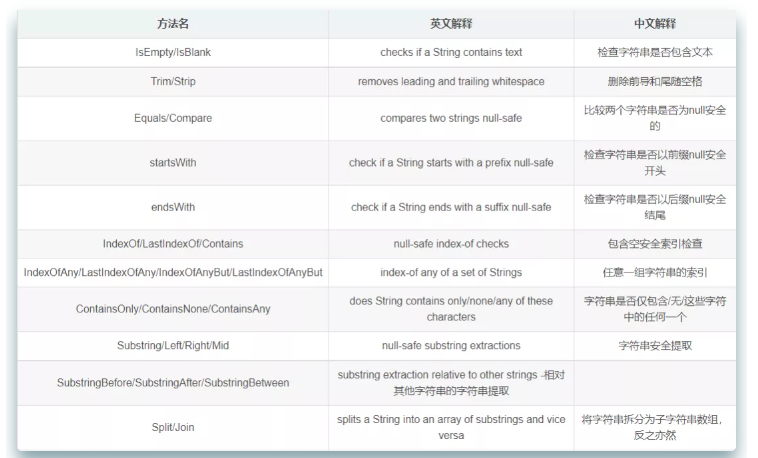
-
发表了文章
2022-01-15
20 个笑肚疼的代码片段
-
发表了文章
2022-01-15
如何保护 Spring Boot 配置文件中的敏感信息
-
发表了文章
2022-01-15
20 个实例玩转 Java 8 Stream
-
发表了文章
2022-01-15
20 个实例玩转 Java 8 Stream
-
发表了文章
2022-01-15
一个由“ YYYY-MM-dd ”引发的惨案 !
-
发表了文章
2022-01-15
推荐一个 Java 接口快速开发框架
-
发表了文章
2022-01-15
RedisJson 横空出世,性能碾压ES和Mongo!
-
发表了文章
2022-01-15
Java 程序员必须掌握的 10 款开源工具!
-
发表了文章
2022-01-15
IDEA高效使用教程,一劳永逸!
-
发表了文章
2022-01-15
推荐一个分布式JVM监控工具,实惠好用,开源(附源码)!
-
发表了文章
2022-01-15
推荐一款 IDEA 插件,多人远程编程 ! 爽
-
发表了文章
2022-01-15
瞬间几千次的重复提交,我用 SpringBoot+Redis 扛住了!
-
发表了文章
2022-01-15
大文件上传:秒传、断点续传、分片上传
-
发表了文章
2022-01-15
蛋了,Logback也炸了。。。
-
发表了文章
2022-01-15
一键生成Springboot & Vue项目! 【毕设神器】
-
发表了文章
2022-01-15
基于 SpringBoot + MyBatis-Plus 的公众号管理系统
-
发表了文章
2022-01-15
Java 18 就要来了,新功能很多!
-
发表了文章
2022-01-15
Redis 缓存使用技巧和设计方案
-
发表了文章
2022-01-15
GitHub 上标星 13.4K 的远程软件!太强大了
-
发表了文章
2022-01-15
IDEA 这个小技巧真的太实用了。。
滑动查看更多
暂无更多信息
暂无更多信息