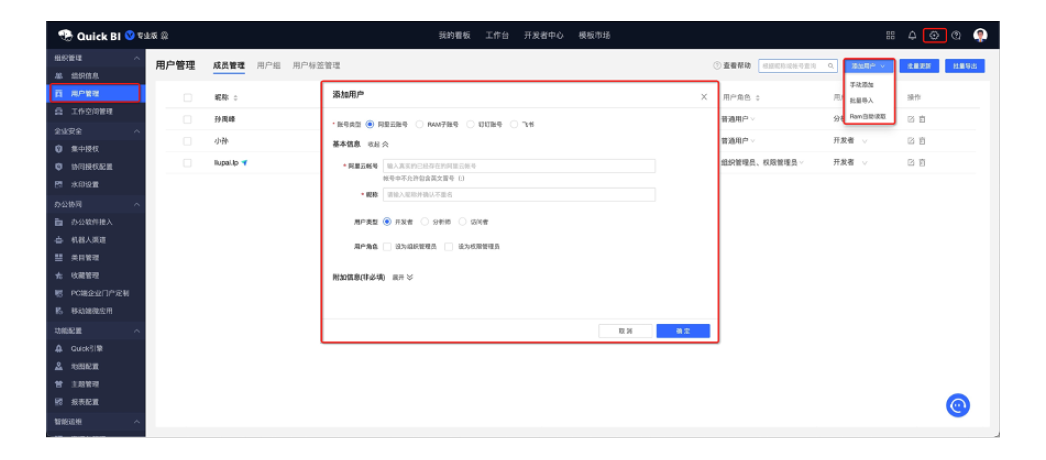
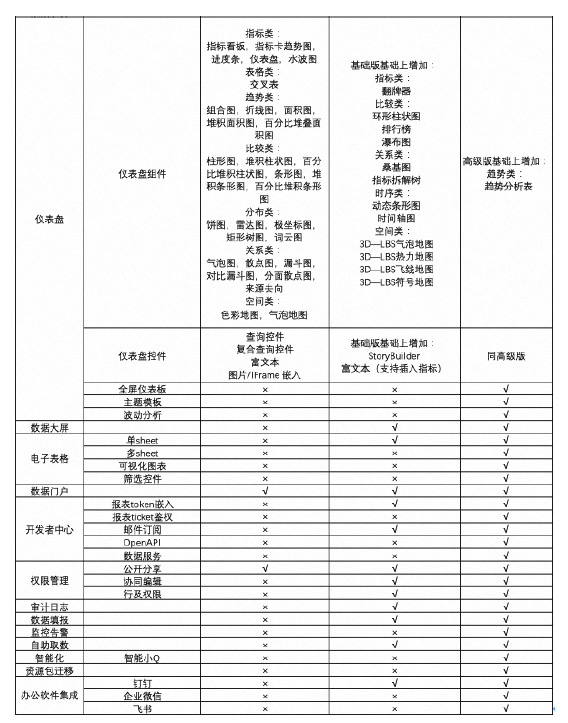
当Flink的任务出现checkpoint失败的时候,一般不会导致任务直接失败,但是checkpoint的失败会导致用户异常重启的时候无法从最近的checkpoint记录来恢复,会导致任务只能从最初的时间点或者是savepoint来进行恢复,可能会导致下游数据的重复,以及数均延迟增大,所以正常的checkpoint增量生成是flink任务健康度的体现,如下图是一个checkpoint生成失败的情况。
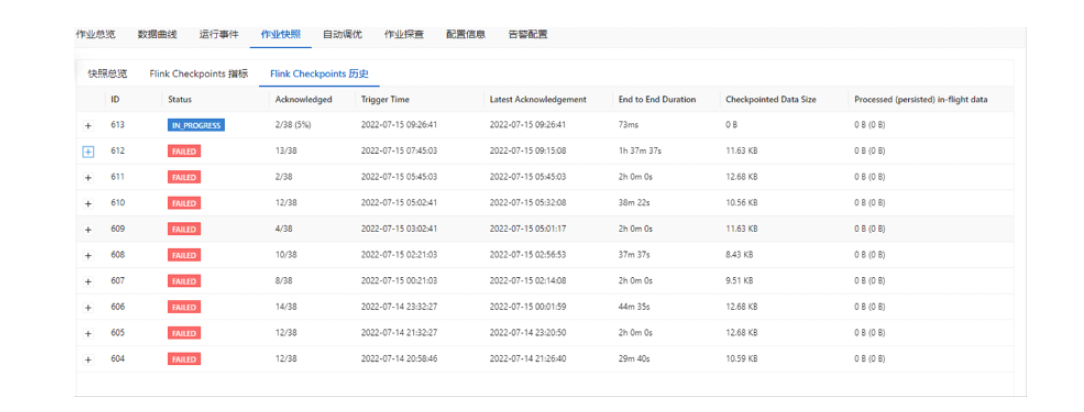
由上图可以看到,当前该任务是一直存在生成checkpoint失败的情况,Checkpoint 失败大致分为两种情况:Checkpoint Decline 和 Checkpoint Expire,此种情况经过分析后是 Checkpoint Expire的情况。
(1) Checkpoint Expire导致的Checkpoint失败
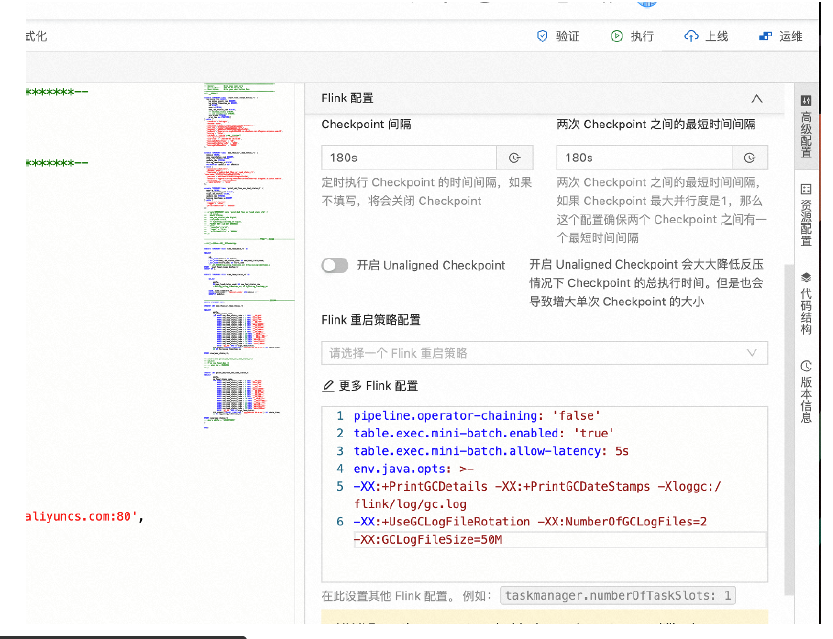
如果 Checkpoint 做的非常慢,超过了 timeout 还没有完成,则整个 Checkpoint 也会失败。当一个 Checkpoint 由于超时而失败是,会在 jobmanager.log 中看到如下的日志,同时也可以通过作业参数execution.checkpointing.interval 设置做Checkpoint的间隔时间。具体的JM日志可以发现如下
Checkpoint 1 of job 78d268e6fbc19411185f7e4868a44178 expired before completing.
表示 Chekpoint 1 由于超时而失败,这个时候可以可以看这个日志后面是否有类似下
面的日志:
Received late message for now expired checkpoint attempt 1 from 0b60f08bf3793875b59f8d9bc74ce2e1 of job 78d268e6fbc194111c
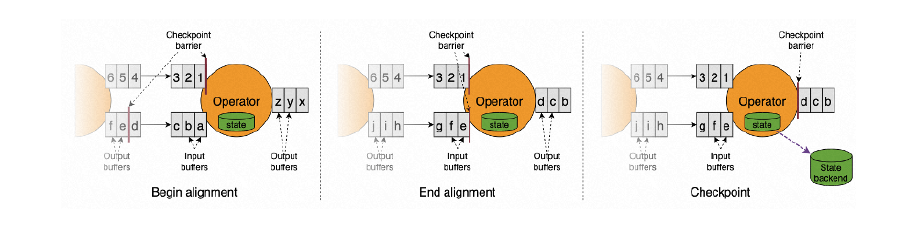
如果任务开启了debug日志,我们按照下面的日志把 TM 端的 snapshot 分为三个阶段,开始做 snapshot 前,同步阶段,异步阶段:
DEBUGStarting checkpoint (604) CHECKPOINT on task taskNameWithSubtasks
(4/4)
这个日志表示 TM 端 barrier 对齐后,准备开始做 Checkpoint。
DEBUG2019-08-06 13:43:02,613 DEBUG org.apache.flink.runtime.state.AbstractSnapshotStrategy - DefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation {fileSystem=org.apache.flink.core.fs.SafetyNetWrapperFileSystem@70442baf, checkpointDirectory=xxxxxxxx, sharedStateDirectory=xxxxxxxx, taskOwnedStateDirectory=xxxxxx, metadataFilePath=xxxxxx, reference=(default), fileStateSizeThreshold=1024}, synchronous part) in thread Thread[Async calls on Source: xxxxxx_source -> Filter (27/70),5,Flink Task Threads] took 0 ms.
上面的日志表示当前这个 backend 的同步阶段完成,共使用了 0 ms。
DEBUGDefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation {fileSystem=org.apache.flink.core.fs.SafetyNet- WrapperFileSystem@7908affe, checkpointDirectory=xxxxxx, sharedStateDirectory=xxxxx, taskOwnedStateDirectory=xxxxx, metadataFilePath= xxxxxx, reference=(default), fileStateSizeThreshold=1024}, asynchronous part) in thread Thread[pool-48-thread-14,5,Flink Task Threads] took 369 m
上面的日志表示异步阶段完成,异步阶段使用了 369 ms。
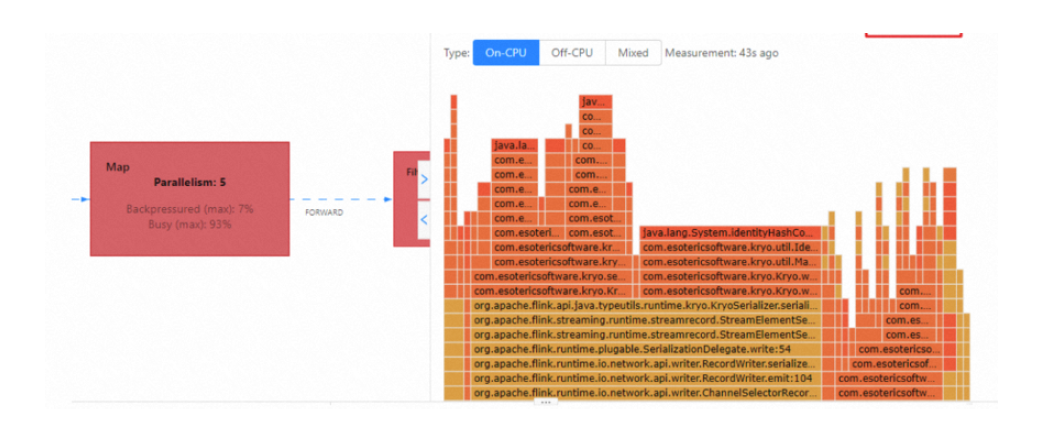
在现有的日志情况下,我们通过上面三个日志,定位 snapshot 是开始晚,同步阶段做的慢,还是异步阶段做的慢,然后再按照情况继续进一步排查flink任务情况,比如是否任务是否出现反压,任务数据量如何生生成的checkpoint大小等情况。"
以上内容摘自《企业级云原生白皮书项目实战》电子书,点击https://developer.aliyun.com/ebook/download/7774可下载完整版