您团队提出的基于麦克风阵列的多通道说话人区分系统是如何工作的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
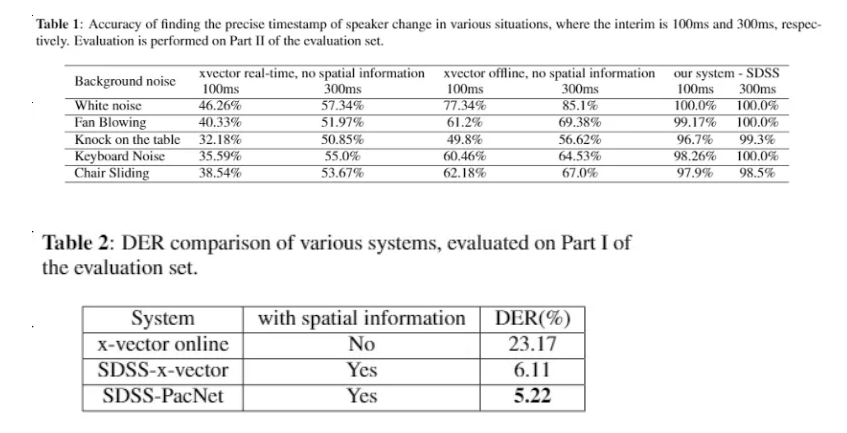
我们提出的基于麦克风阵列的多通道说话人区分系统,首先利用麦克风阵列获取SRP-PHAT空间相位信息进行空间声源定位。同时,结合神经网络的VAD模块、Overlap检测模块和说话人segmentation模块,最终通过embedding+空间信息+时间信息的AHC聚类算法,实现对每个说话人的精准定位和追踪,从而显著提升会议场景下的说话人区分性能。