DataWorks现象就是我实时同步了18张表
这18张表一天内更新的数据量可能也就10W左右
我尝试过多种资源配置,使用的是新版本资源组按量付费,从2C 到 6C,每个任务都会挂掉
资源少的提交上去就会挂,资源多的跑一段时间就会挂
同等binlog同步我在其他云平台消耗的资源大概就是1C左右,这块麻烦排查一下,这个资源消耗有点过于夸张了,我重新复现一下异常
我使用的是硅谷节点,新版资源组,同步方式为实时同步?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
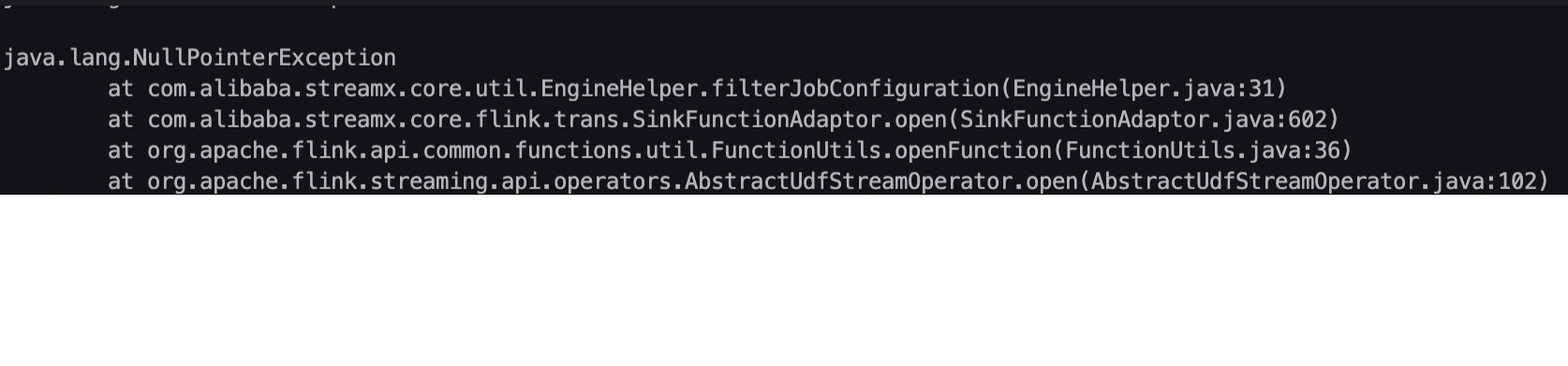
检查同步任务日志:查看任务执行日志,确定是哪个环节出现问题,比如数据读取、写入或者是数据转换。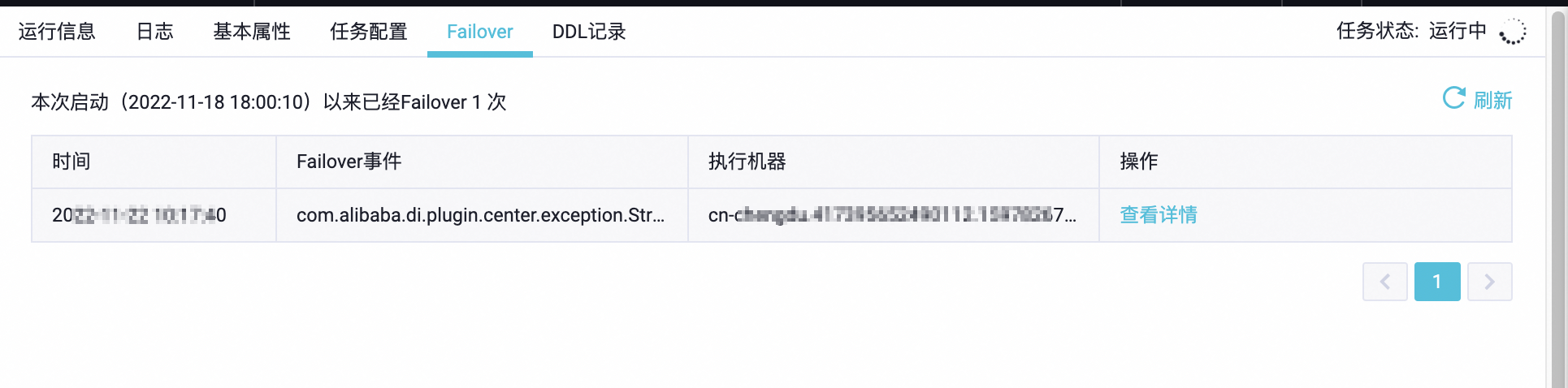
根据您描述的情况,您在DataWorks上遇到了实时同步18张表时资源消耗异常的问题,即使尝试了从2C到6C的资源配置,任务仍然会失败。考虑到您提到在其他云平台上相似的binlog同步任务仅需约1C的资源,这里提供一些排查方向和建议,希望能帮助您定位问题所在:
检查同步任务配置:
分析数据倾斜问题:
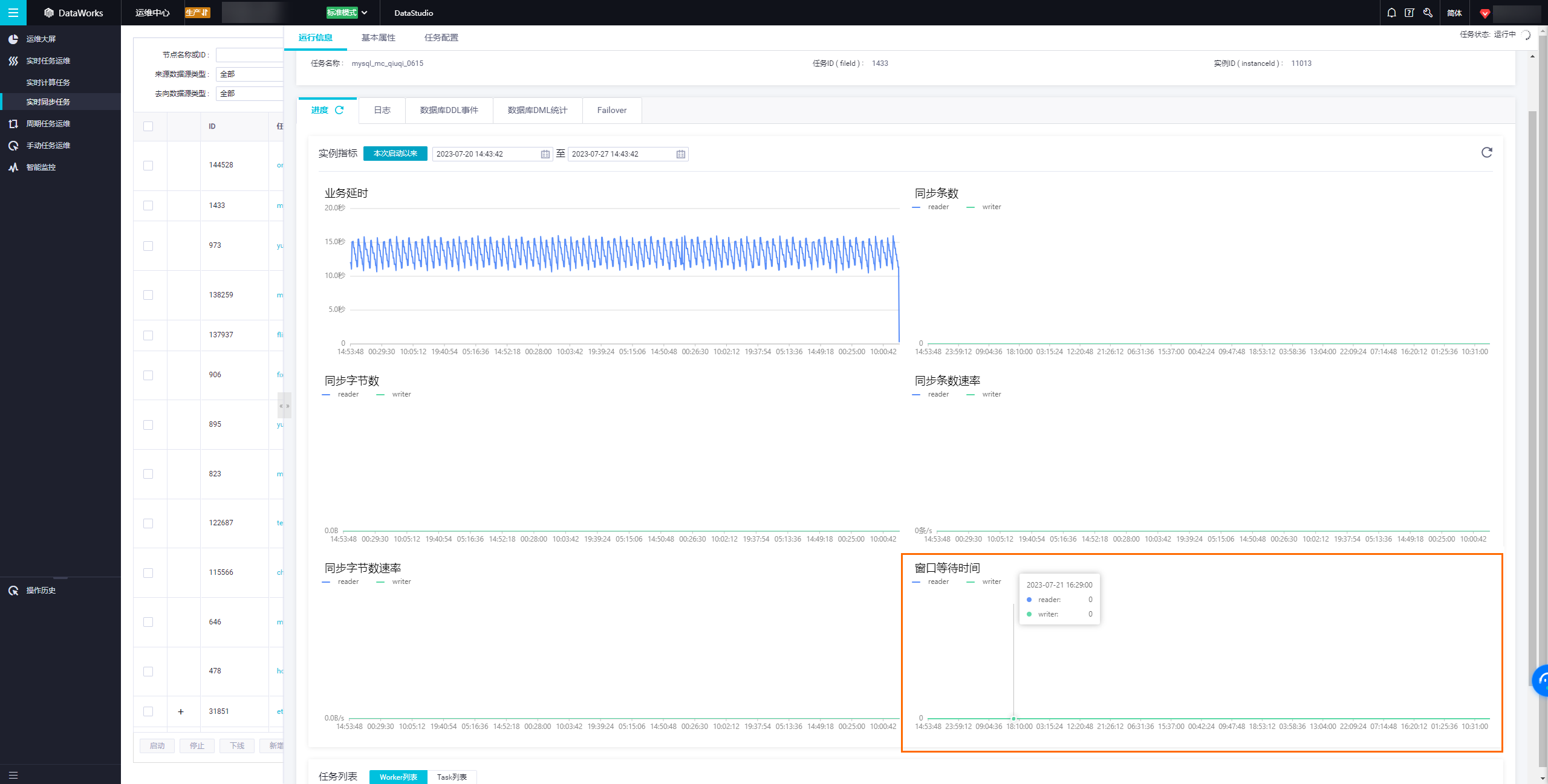
数据倾斜可能导致某些任务资源紧张。尽管您的总体数据量不大,但如果更新集中在少数几张表或分区上,也可能引发资源瓶颈。通过运行信息页签监控不同Reader线程的负载,确认是否存在数据倾斜。
审查同步策略与频率:
网络与地域因素:
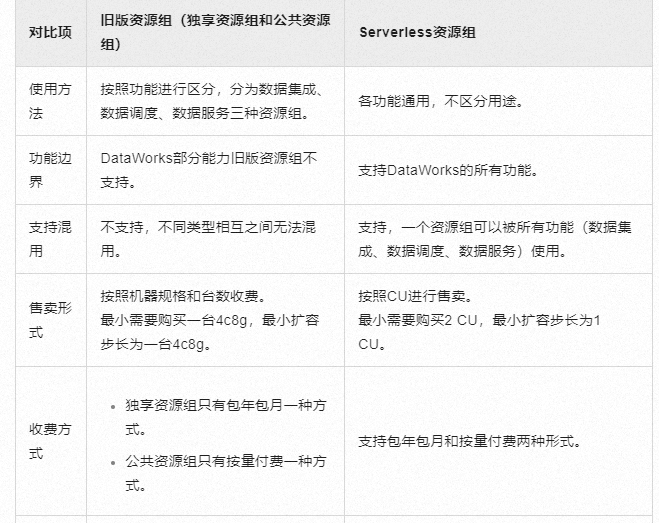
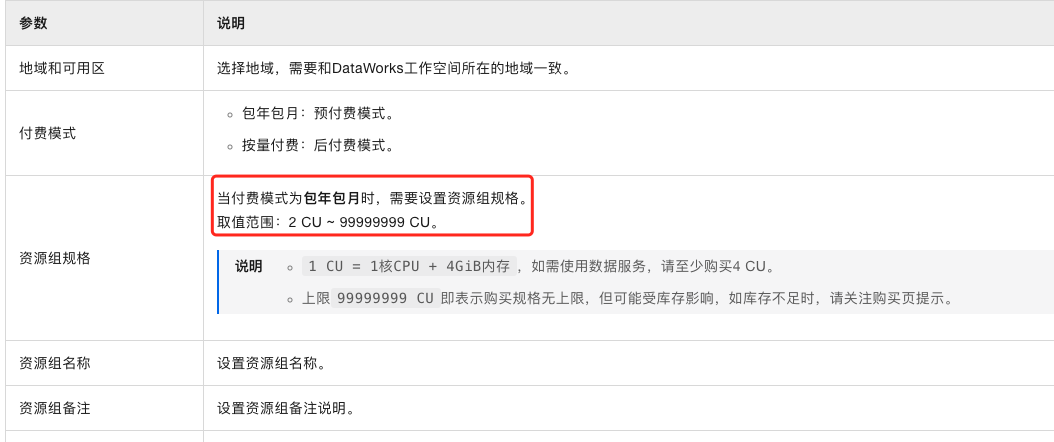
资源组选择与计费模式:
内存配置不合理。确保任务内存设置与数据处理需求相匹配,避免因内存不足(如OutOfMemoryError)导致任务失败。可以通过任务的基本配置界面调整内存大小。
检查实时同步任务的运行信息,确认是否有数据倾斜现象,即某些Reader线程处理的数据量远大于其他线程。如果是这种情况,需要从源头解决数据分布不均的问题。
在DataWorks中实时同步18张表,即使这些表一天内更新的数据量只有大约10万条,也可能会遇到资源消耗大、任务挂起或报错(如error code 500)等问题。针对这种情况,以下是一些建议的解决步骤和策略:
面对DataWorks实时同步18张表且每天更新的数据量仅约10W左右,可以采取一些优化措施来提高同步效率并降低资源消耗。
在DataWorks中进行实时数据同步时,如果每日更新量相对较小,可以通过优化同步任务的配置和运行环境,减少资源占用并提高同步效率。以下将提供一些具体的优化策略:
优化数据同步频率
调整同步策略:根据实际业务需求,考虑是否需要持续实时同步,或者可以采用近实时同步(近实时同步即延迟一定时间后同步),这样可以减少同步任务的执行频率,从而降低资源消耗。
设置合理的同步间隔:对于更新频率不高的数据,可以适当延长同步间隔时间,例如从每分钟同步调整为每小时同步,以减少同步任务的执行次数。
优化数据同步链路
选择合适的数据源:确保所选数据源与DataWorks兼容性良好,减少中间环节可能带来的性能损耗。例如,直接从MySQL或PolarDB等原生支持DataWorks的数据源进行同步,而非通过第三方工具转换后再同步。
网络环境优化:尽量使用内网同步,避免公网带来的网络不稳定性及安全性问题。内网同步可以减少网络延迟,提高同步速度和稳定性。
优化同步任务配置
合理设置并发数:根据源端和目标端数据库的性能,适当调整读取和写入并发数。并发数过高可能会给源端数据库带来不必要的压力,过低则会导致同步延迟。
过滤不必要的数据:在同步任务配置中,通过添加过滤条件排除不必要同步的数据,只同步真正需要更新的部分,这样可以大大减少同步任务的处理量。
优化目标端写入策略
数据分组和分片:根据目标端数据库的特点,合理设置数据分片和分组策略,避免单点压力过大,提升写入效率。
自动分区和手动分区:对于大数据量表,可以采用自动分区技术,将不同范围的数据存储在不同的分区中,提高查询和同步的效率。同时,也可以尝试手动分区,根据业务逻辑将数据分类存储。
监控和调优同步任务
监控同步任务:定期查看同步任务的运行状态和性能指标,如延迟时间、失败次数等。发现异常立即处理,避免长时间累积影响数据质量和同步效率。
JVM参数调优:根据同步任务的具体执行情况,适当调整JVM参数,如堆大小、GC策略等,提高任务执行的稳定性和效率。
资源组规格调整
选择合适资源组:根据同步任务的实际负载情况,选择合适规格的独享数据集成资源组。过低规格的资源组可能导致同步任务执行缓慢,过高则会造成资源浪费。
动态调整资源组规格:随着数据量的增长或减少,及时调整资源组规格,确保同步任务始终在最优的资源环境下运行。
脏数据处理
定义脏数据阈值:当不允许脏数据产生时,同步任务执行过程中一旦产生脏数据,任务将失败退出;而允许脏数据并设置其阈值时,同步任务将忽略脏数据并正常执行。
脏数据报警:设定脏数据报警规则,当脏数据量超过预设阈值时,及时通知相关人员进行处理,避免影响整体同步任务。
附加字段优化
自定义附加字段:在同步任务配置时,可以根据业务需求为目标表添加附加字段,并为这些字段赋值常量或变量。合理的附加字段设计可以简化后续数据处理工作。
优化字段映射:在源表和目标表之间进行字段映射时,尽量保持一一对应关系,避免一个源字段对应多个目标字段,减少数据转换的复杂性。
总的来说,DataWorks实时同步少量数据时,通过优化同步频率、链路、任务配置以及目标端写入策略,并持续监控与调优同步任务,可以有效提高同步效率并降低资源消耗。结合具体的业务需求和实际数据特点进行个性化配置和优化,是保障数据同步高效稳定运行的关键。
优化数据同步策略:可以尝试优化数据同步策略,例如增加缓存、分批处理、异步执行等策略,以减少数据同步的时间和资源消耗。
调整资源配置:可以尝试调整资源配置,例如增加CPU、内存等资源,以提高数据同步的效率和稳定性。
检查数据源和目标表的性能:检查数据源和目标表的性能,确保它们能够支持大规模数据的同步和处理。如果数据源或目标表的性能不足,可能导致数据同步失败或资源消耗过大。
在实时同步大量表时遇到资源不足或异常挂起的情况。根据您的描述有可能的原因和排查建议:
资源限制:检查您的DataWorks项目是否有资源配额限制,尤其是对于实时同步任务。
确认是否已经达到了硅谷节点的新版资源组的配额上限。
任务配置:确保您的同步任务配置正确,包括同步类型(全量/增量)、过滤条件等。
检查是否有特殊的表结构或者字段名包含特殊字符等问题,这可能会导致解析错误。
性能优化:尝试调整同步任务的并发度,减少同时运行的任务数量。对于每张表,检查是否有索引可以优化查询性能。如果可能的话,尝试将大表拆分为更小的表或者分区表来减少单个任务处理的数据量。
监控与日志:查看DataWorks的任务日志,寻找具体的错误信息或警告。监控任务的CPU和内存使用情况,了解资源使用峰值。
您在DataWorks中遇到的问题似乎是由于实时同步任务消耗过多资源而导致任务失败。考虑到您提到的情况,这里有几点建议和排查步骤,希望能够帮助您解决问题:
通过上述步骤,您应该能够更好地定位问题所在,并采取相应的措施来解决实时同步任务中的资源消耗问题。如果需要进一步的帮助,请随时提供更多信息。
虽然每天更新的数据量只有10W左右,但是如果表中的数据量较大,同步过程中可能会产生大量的临时数据,导致资源消耗增加。可以尝试优化表结构,减少不必要的字段,以降低同步过程中的数据量。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。