
flinkcdc datastream模式想实现同时读取oracle多个表并写入到iceberg中,这个应该怎么实现呢 ?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Apache Flink 结合 Flink CDC Connector 可以实现从多个数据库表中读取数据变更,并将这些变更实时写入到 Iceberg 数据湖中。以下是使用 Flink DataStream API 实现这一需求的步骤:
首先,确保你的 Flink 项目中包含了以下依赖:
<!-- Flink CDC Connector -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-oracle-cdc</artifactId>
<version>你的flink-cdc版本</version>
</dependency>
<!-- Flink Iceberg Connector -->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-flink</artifactId>
<version>你的iceberg版本</version>
</dependency>
使用 Flink CDC Connector 从 Oracle 数据库中读取数据。你需要为每个表创建一个 OracleSource。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import com.ververica.cdc.connectors.oracle.OracleSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置 Oracle CDC Source
Map<String, String> properties = new HashMap<>();
properties.put("scan.startup.mode", "initial"); // 或者其他模式
properties.put("snapshot.mode", "initial"); // 或者其他模式
// 读取多个表
String[] tableNames = {"table1", "table2", "table3"};
List<DataStreamSource<String>> sources = new ArrayList<>();
for (String tableName : tableNames) {
OracleSource<String> oracleSource = OracleSource.<String>builder()
.hostname("your-oracle-host")
.port(1521)
.database("your-database")
.schemaList("your-schema")
.tableList("your-schema." + tableName)
.username("your-username")
.password("your-password")
.deserializer(new JsonDebeziumDeserializationSchema()) // 将数据转换为 JSON 格式
.debeziumProperties(properties)
.build();
DataStreamSource<String> streamSource = env.fromSource(oracleSource, WatermarkStrategy.noWatermarks(), "Oracle CDC Source for " + tableName);
sources.add(streamSource);
}
将所有表的数据流合并为一个数据流。
DataStream<String> unionStream = sources.get(0);
for (int i = 1; i < sources.size(); i++) {
unionStream = unionStream.union(sources.get(i));
}
将合并后的数据流写入 Iceberg。
import org.apache.iceberg.flink.sink.IcebergSink;
// 定义 Iceberg 表的属性
Map<String, String> icebergProperties = new HashMap<>();
icebergProperties.put("write.format", "parquet");
// 写入 Iceberg
unionStream.addSink(new IcebergSink<>( icebergProperties, icebergTable, icebergSchema));
最后,执行 Flink 作业。
env.execute("Flink CDC to Iceberg Job");
请注意,这里的代码仅为示例,可能需要根据你的具体情况进行调整。比如,实际表名、连接信息、Iceberg 表的 schema 定义等。另外,确保 Iceberg 表已经创建好,并且其 schema 与 Oracle 数据库表的 schema 匹配。
在实际操作中,还需要处理事务、一致性、错误处理等复杂情况,并确保配置的 CDC 参数适合你的业务需求。此外,建议在生产环境中进行充分的测试,以确保系统的稳定性和数据的准确性。
Flink CDC DataStream API 允许你从不同的数据库表中读取数据流,并可以写入到各种sink中,包括 Apache Iceberg。以下是实现从Oracle数据库读取多个表并将数据写入到Iceberg表的基本步骤:
添加依赖:确保你的项目中包含了Flink CDC Connector和Iceberg Connector的依赖。
配置源表:定义你想要读取的Oracle表。你可以使用TableSchema来定义表的结构。
创建Flink CDC Source:使用StreamExecutionEnvironment创建一个Flink CDC Source,指定源表和相关配置。
转换数据:根据需要转换读取的数据流。这一步是可选的,取决于你是否需要对数据进行过滤或转换。
创建Iceberg Sink:配置并创建一个Iceberg Sink,指定目标Iceberg表的配置。
写入数据:使用addSink方法将数据流写入到Iceberg。
要在 Flink CDC 中使用 DataStream API 将多个表的数据捕获并写入到 Iceberg 中,你需要遵循以下几个步骤:
步骤 1: 安装必要的依赖
确保你的项目中包含了 Flink CDC 和 Iceberg 的相关依赖。对于 Flink CDC,你需要添加 Debezium connector 的依赖。对于 Iceberg,你需要添加 Iceberg 的 Flink connector 依赖。
在 Maven 的 pom.xml 文件中,你可以添加如下依赖: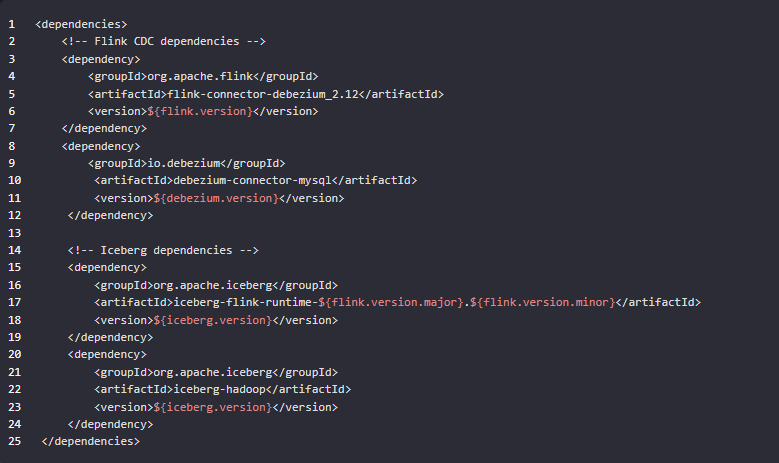
请替换 ${flink.version}、${debezium.version} 和 ${iceberg.version} 为实际的版本号。
正确设置版本号
flink.version: 你应该使用你正在运行的 Flink 版本号。
debezium.version: 选择与你的 Flink 版本兼容的 Debezium 版本。
iceberg.version: 选择与你的 Flink 版本兼容的 Iceberg 版本。
步骤 2: 配置 Flink CDC
创建一个 Flink 环境,并配置 Debezium connector 以捕获 MySQL 数据库的变更事件。这里是一个基本的配置示例: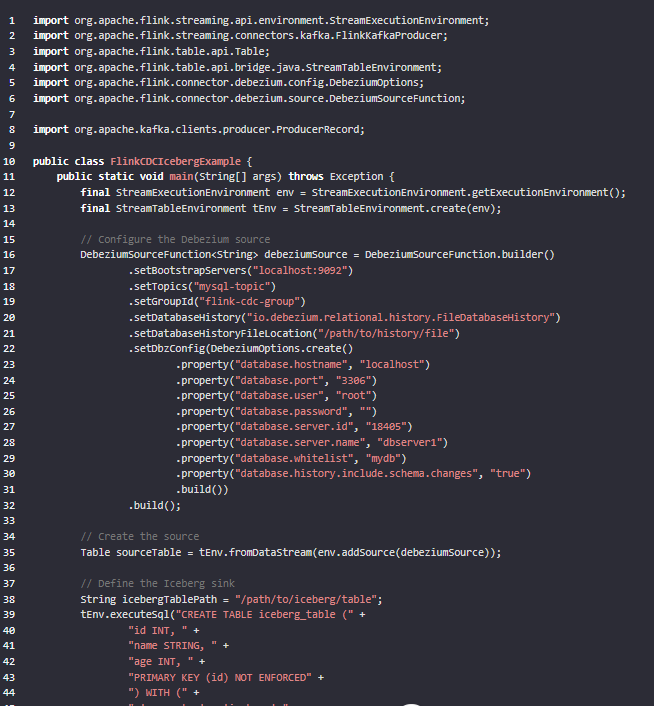
使用Flink CDC DataStream模式从Oracle读取多个表并写入Iceberg,您需要配置多个Flink连接器源和 sink。以下是一步一步的概述:
配置Oracle Source:
对每个Oracle表创建一个独立的Source任务,使用FlinkJdbcInputFormat或使用专门的cdc库如debezium,根据具体需求。
数据整合:
使用DataStream操作(如union)将来自不同表的数据流合并。
配置Iceberg Sink:
创建一个Iceberg sink,配置catalog-name、catalog-database等参数,用于写入数据。
使用Flink CDC从Oracle读取多个表并写入Iceberg,您可以分别配置多个CREATE TABLE语句,每个对应一个Oracle表。请确保在connector中使用jdbc,并设置正确的数据库连接参数。例如:
对于每个Oracle表table1和table2:
然后您可以使用INSERT INTO语句或者DataStream API将数据写入Iceberg表。
使用Flink CDC从Oracle读取多个表并写入Iceberg,您需要分别配置每个表的连接器。以下是一个大致的步骤:
安装并使用flink-connector-jdbc和flink-connector-iceberg。
对每个Oracle表创建一个DataStream源,配置OracleDatabaseTableSource。
配置Iceberg的TableSink,用于写入数据。使用DataStream操作(如unionAll)将多个表的数据流合并。将合并后的流写入Iceberg表。具体代码示例:
确保在配置Oracle数据库连接时提供正确的凭证和表名,以及在配置Iceberg时提供OSS相关参数。参考官方文档和阿里云实时计算Flink版文档。
要使用Flink CDC DataStream模式将多个表的数据并行写入到Iceberg中,这样搞:
设置环境与依赖: 确保您的项目中包含了Flink CDC Connector以及与Iceberg集成的相关依赖。这通常涉及到在项目的构建文件(如Maven的pom.xml)中添加相应的依赖项。
配置Flink CDC Source: 对于每一个需要捕获变更的表,您需要配置一个Flink CDC Source。这包括指定数据库连接信息、数据库名、表名以及捕获的变更类型(如插入、更新、删除)。
数据处理与转换(可选): 根据需求,您可能需要对从Flink CDC Source读取的数据进行一些预处理或转换,比如数据清洗、类型转换等。
配置Iceberg Sink: 为每个表配置一个Iceberg Sink,指定Iceberg表的路径、catalog信息以及其他必要的配置,如文件系统的访问凭证等。确保sink配置与您的Iceberg存储环境相匹配。
并行处理与连接Source与Sink: 在Flink程序中,使用DataStream API将各个表的Source与对应的Sink连接起来。可以通过keyBy、broadcast或其他Flink提供的数据流操作来实现数据的并行处理与路由,确保每个表的数据正确地写入到其对应的Iceberg表中。
启动执行: 配置好整个数据流图之后,提交Flink作业到集群上执行。请确保使用的Flink版本支持AUTO OPTIMIZE功能
,以便后续可能进行的性能优化。
参考文档: https://blog.csdn.net/yy8623977/article/details/124298670
创建一个 Flink DataStream 来读取该表的数据。可以使用 OracleSource 来定义数据源,并设置相应的数据库连接属性和表名
Properties properties1 = new Properties();
properties1.setProperty("connector", "oracle-cdc");
properties1.setProperty("hostname", "your_oracle_host");
properties1.setProperty("port", "your_oracle_port");
properties1.setProperty("username", "your_oracle_username");
properties1.setProperty("password", "your_oracle_password");
properties1.setProperty("database-name", "your_oracle_dbname");
properties1.setProperty("schema-name", "your_schema");
properties1.setProperty("table-name", "your_table1");
SourceFunction<String> source1 = OracleSource.<String>builder()
.setProperties(properties1)
.build();
DataStream<String> stream1 = env.addSource(source1);
// 类似地,为其他 Oracle 表创建 Source
使用 union 方法来实现
DataStream<Tuple2<String, String>> combinedStream = stream1.map(value -> Tuple2.of("table1", value))
.union(stream2.map(value -> Tuple2.of("table2", value)));
1、对于每个Oracle表,创建一个 Flink DataStream 来读取该表的数据。
// 示例:为第一个 Oracle 表创建 Source
Properties properties1 = new Properties();
properties1.setProperty("connector", "oracle-cdc");
properties1.setProperty("hostname", "your_oracle_host");
properties1.setProperty("port", "your_oracle_port");
properties1.setProperty("username", "your_oracle_username");
properties1.setProperty("password", "your_oracle_password");
properties1.setProperty("database-name", "your_oracle_dbname");
properties1.setProperty("schema-name", "your_schema");
properties1.setProperty("table-name", "your_table1");
SourceFunction<String> source1 = OracleSource.<String>builder()
.setProperties(properties1)
.build();
DataStream<String> stream1 = env.addSource(source1);
// 类似地,为其他 Oracle 表创建 Source
2、合并 DataStream
DataStream<Tuple2<String, String>> combinedStream = stream1.map(value -> Tuple2.of("table1", value))
.union(stream2.map(value -> Tuple2.of("table2", value)));
3、写入iceberg中。
// 假设你已经有了 Iceberg 表的 Catalog 和 Identifier
Catalog catalog = ...; // 初始化你的 Iceberg Catalog
Identifier identifier = Identifier.of(...); // 指定要写入的 Iceberg 表
IcebergSink.Builder<Tuple2<String, String>> sinkBuilder = IcebergSink.forRow(combinedStream)
.catalog(catalog)
.table(identifier)
// 配置其他必要的 Sink 属性,如分区、格式等
.build();
combinedStream.addSink(sinkBuilder);
——参考链接。
要在Flink CDC DataStream模式下实现同时读取Oracle多个表并写入到Iceberg中,您可以遵循以下步骤进行配置和实现:
合并多个源与sink:
示例代码结构概述(非直接可运行代码,仅为逻辑示意):
```java
// 假设tablesToRead是一个包含所有待读取Oracle表名的集合
for (String tableName : tablesToRead) {
// 配置并创建Oracle CDC Source
OracleCDCSource oracleSource = OracleCDCSource.builder()
.hostname("your_host")
.port(1521)
.database("your_database")
.username("your_username")
.password("your_password")
.tableList(tableName)
// 其他必要配置
.build();
// 创建环境并添加Source
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 为每个表创建单独的source数据流
DataStream sourceStream = env.fromSource(oracleSource, WatermarkStrategy.noWatermarks(), "Oracle CDC Source - " + tableName);
// 可以在此处对sourceStream进行转换处理,如映射字段等
// 将所有表的数据流合并
if (mergedStream == null) {
mergedStream = sourceStream;
} else {
mergedStream = mergedStream.union(sourceStream);
}
}
// 配置Iceberg Sink
SinkFunction icebergSink = IcebergSink.builder()
.forRowType(...) // 指定Iceberg表的架构
.withProperty("path", "your_iceberg_table_path") // Iceberg表位置
// 其他Sink配置
.build();
// 将合并后的数据流连接到Iceberg Sink
mergedStream.addSink(icebergSink);
env.execute("Flink CDC to Iceberg");
```
参考链接:https://help.aliyun.com/zh/flink/user-guide/manage-dlf-catalogs
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


