
flink checkpoint 频繁重启 ,能否 失败直接跳过?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
可以进行优化,你先试试
设置Checkpoint超时时间:可以通过env.getCheckpointConfig().setCheckpointTimeout(long time)设置Checkpoint的超时时间,如果Checkpoint在设定的时间内没有完成,就会被认为是失败的。如果默认的超时时间太短,可以适当增加这个值,以避免因超时而失败的问题。
配置重启策略:可以在Flink的配置文件flink-conf.yaml中设置重启策略,或者在应用程序代码中动态指定重启策略。例如,可以使用固定间隔(fixed-delay)重启策略,并设置尝试重启的次数和重启间隔时间。如果Checkpoint失败,Flink会根据配置的重启策略进行重启。
使用Savepoint进行恢复:如果Checkpoint失败,可以使用Savepoint进行恢复。Savepoint是手动触发的,可以作为Checkpoint的补充,用于在作业升级或重启时保持数据的一致性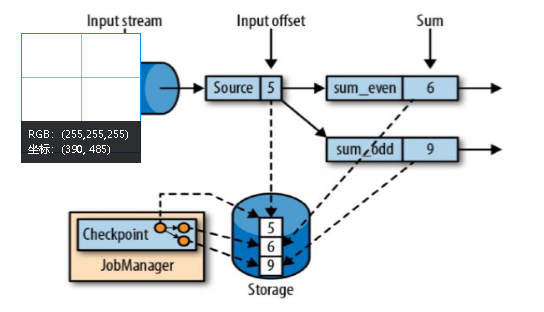
Flink的checkpoint是为了保证数据处理的容错性,当任务失败并重启时,可以从最近的checkpoint点恢复。如果你不希望任务在失败后自动重启,可以设置不同的重启策略。
在Flink中,可以通过设置不同的重启策略来控制任务失败时的行为。例如,你可以设置RestartStrategies.noRestart()来指示系统在任务失败时不重启作业。
以下是设置不重启策略的示例代码:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置不重启策略
env.setRestartStrategy(RestartStrategies.noRestart());
// 你的Flink程序代码
// ...
如果你想要在失败时跳过checkpoint并直接重新开始,而不是使用checkpoint进行恢复,这种方式不是由Flink提供的,你可能需要自己实现相关的逻辑。
在实现自定义逻辑时,可以考虑监听任务失败的事件,并在这些事件发生时更新一个外部的标志或状态,然后在程序中检查这个标志以决定是否跳过checkpoint。但是,这种方法并不是推荐的做法,因为它会丢失已经通过checkpoint保存的状态,并且不符合Flink设计的容错理念。
Flink的Checkpoint配置允许设置容忍的失败次数,但不支持直接跳过失败的Checkpoint。如果频繁失败,建议检查网络、State大小、资源分配或调整Checkpoint参数,如间隔时间、并行度等。
可以设置重启策略为固定延迟重启,并且设置重启尝试的次数。例如,以下配置表示如果 Checkpoint 失败,Flink 会尝试重启,但最多重启 3 次,每次重启之间延迟 10 秒:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
设置故障率限制:
execution.checkpointing.tolerable-failed-checkpoints: 3
禁用重启
restart-strategy.fixed-delay.attempts: 0
调整 Checkpoint 间隔
execution.checkpointing.interval: 1 min
Flink 实现了多种重启策略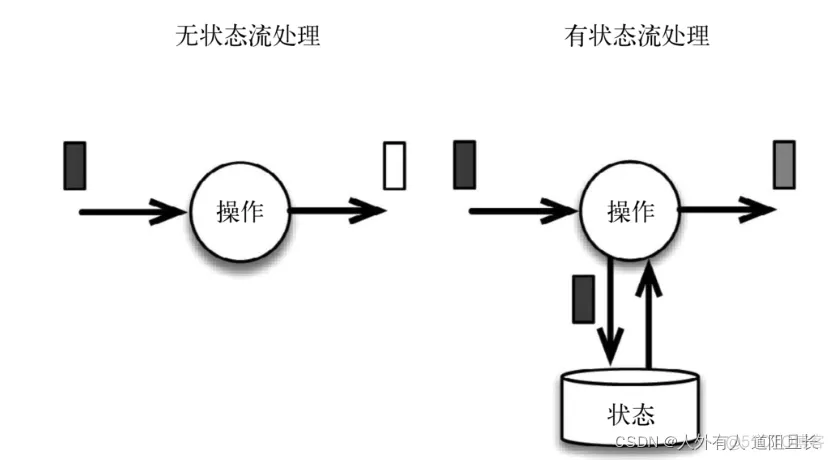
固定延迟重启策略(Fixed Delay Restart Strategy)
故障率重启策略(Failure Rate Restart Strategy)
没有重启策略(No Restart Strategy)
Fallback重启策略(Fallback Restart Strategy)
反思&扩展
Flink支持不同的重启策略,以在故障发生时控制作业如何重启
默认的重启策略:如果没有启用 checkpointing,则使用无重启 (no restart) 策略。如果启用了 checkpointing,但没有配置重启策略,则使用固定间隔 (fixed-delay) 策略
如果在工作提交时指定了一个重启策略,该策略会覆盖集群的默认策略默认的重启策略可以通过 Flink 的配置文件 flink-conf.yaml 指定。配置参数 restart-strategy 定义了哪个策略被使用。
常用的重启:
策略固定间隔 (Fixed delay)
失败率 (Failure rate)
无重启 (No restart)
原文链接:https://blog.csdn.net/jjclove/article/details/127406737
Flink的Checkpoint机制在遇到失败时,默认行为并不会直接跳过,因为这是确保数据一致性和容错性的关键过程。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



