
DataWorks在进行跨项目克隆的时候 遇到这个报错 这个ID是系统自动生成的 测试环境没有 要怎么办?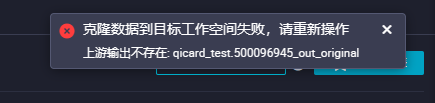
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
严格按照操作步骤执行:进入DataWorks的DataStudio页面,选择需要克隆的业务流程,然后点击右上角的“跨项目克隆”按钮。逐项确认每个步骤是否正确完成,包括设置计算引擎映射、添加待克隆节点等。
利用日志分析问题:如果上述步骤无误但仍然报错,查看操作日志以获取更详细的错误信息。日志可能会提供具体的错误原因和解决方案。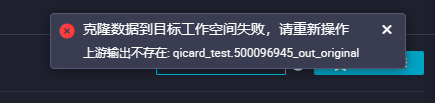
确保工作空间模式兼容:跨项目克隆支持从简单模式工作空间克隆至另一简单模式工作空间,以及从简单模式克隆至标准模式工作空间。确认源工作空间和目标工作空间的模式是否符合这些要求。
在DataWorks进行跨项目克隆时遇到报错,可以尝试以下方法解决:
检查源项目和目标项目的权限设置。确保当前用户具有足够的权限来访问源项目和目标项目。
检查源项目和目标项目的状态。确保源项目和目标项目都是处于正常状态,没有被锁定或删除。
检查源项目和目标项目的配置。确保源项目和目标项目的配置信息正确无误,例如数据源、表结构等。
检查网络连接。确保网络连接稳定,没有被防火墙或其他网络设备阻止。
如果以上方法都无法解决问题,可以尝试联系阿里云技术支持寻求帮助。
在DataWorks中进行跨项目克隆时遇到报错是一个相对常见的问题,这通常涉及到依赖关系、计算引擎映射或工作空间配置等问题。下面将详细分析可能的原因并提供解决方案:
检查依赖任务的输出
确保所有上游节点已成功克隆:根据DataWorks的跨项目克隆机制,如果某个任务依赖于上游节点的输出,那么这些上游节点必须已经成功克隆到目标工作空间中。确认这些上游节点是否已经存在于目标工作空间,并且它们的输出名称与源工作空间中的一致。
提交并发布所有相关节点:在DataWorks中,依赖关系解析是基于已提交和发布的节点进行的。如果某个上游节点的输出被删除但未提交,其他节点可能仍然会引用这个已删除的输出,导致克隆失败。确保所有涉及的节点都已经正确提交和发布。
设置正确的计算引擎映射
调整计算引擎映射关系:当源工作空间与目标工作空间存在多个计算引擎时,需要明确设置当前工作空间与目标工作空间之间的计算引擎映射关系。如果映射关系不正确,可能导致克隆过程中出现错误。
跳过引擎实例为空的节点:如果某些节点所属的引擎类型在目标工作空间中不存在,可以通过勾选“跳过引擎实例为空的节点”来避免这些节点在克隆过程中引发错误。
检查工作空间配置
确保工作空间模式兼容:跨项目克隆支持从简单模式工作空间克隆至另一简单模式工作空间,以及从简单模式克隆至标准模式工作空间。确认源工作空间和目标工作空间的模式是否符合这些要求。
同地域限制:目前DataWorks的跨项目克隆不支持跨地域操作,源项目与目标项目必须处于同一地域内。如果尝试跨地域克隆,将会导致错误。
处理克隆冲突
解决路径冲突:跨项目克隆默认为新增操作,即在新路径下创建节点及相关的文件夹和业务流程。如果目标路径下已存在名称相同的节点、文件夹或业务流程,新增内容会覆盖原有内容。确认是否有冲突的路径或名称,必要时可先调整目标工作空间的结构。
重新审查克隆步骤
严格按照操作步骤执行:进入DataWorks的DataStudio页面,选择需要克隆的业务流程,然后点击右上角的“跨项目克隆”按钮。逐项确认每个步骤是否正确完成,包括设置计算引擎映射、添加待克隆节点等。
利用日志分析问题:如果上述步骤无误但仍然报错,查看操作日志以获取更详细的错误信息。日志可能会提供具体的错误原因和解决方案。
手动创建缺失的实体
检查并创建缺失的数据表或资源:如果错误提示中提到特定的数据表或资源不存在,可能需要手动在目标工作空间中创建这些表或资源。确保它们的命名和结构与源工作空间中的一致。
使用API或SDK自动化处理
编写自动化脚本:对于复杂的克隆需求或频繁的跨项目操作,可以考虑使用DataWorks提供的API或SDK来自动化执行一些步骤,如创建实体、检查依赖关系等。这可以减少人工操作带来的错误风险。
重新尝试克隆操作
重试克隆过程:在排查并解决上述问题后,重新进行跨项目克隆操作。有时候,简单的重试操作可以解决暂时性的故障或网络问题。
此外,在处理以上技术性问题的同时,还需要注意以下几点:
备份与恢复:在进行任何重要配置更改前,建议备份当前的配置和重要数据,以防修改后出现其他问题可以快速恢复。
性能考虑:跨项目克隆可能涉及大量数据的迁移,确保在执行过程中系统性能充足,特别是在高并发场景下。
权限检查:确认执行克隆操作的账户具有足够的权限,包括源工作空间和目标工作空间的相关权限。
总的来说,通过上述多个方面的优化措施,通常能够有效解决DataWorks跨项目克隆过程中遇到的报错问题。结合具体的操作步骤和错误提示,逐一排查和调整这些设置,是确保克隆操作顺利进行的关键。
当您在DataWorks进行跨项目克隆时,如果遇到报错提到的"qicard_test.500096945_out_original"这样的输出ID不存在,这可能是因为克隆过程中依赖的任务输出在目标工作空间中没有找到对应。您需要检查源项目中的任务输出,确保它们在目标项目中已正确克隆。如果源任务输出没有被成功克隆,可能需要手动创建或修复这个输出。请尝试以下步骤:
确认源项目中的任务是否正确生成了"qicard_test.500096945_out_original"。
检查克隆过程中是否出现了错误或异常,可能需要重新克隆。
如果手动创建,需保证输出命名和格式与源项目一致。
确认依赖关系设置正确,避免因缺失输出导致的依赖问题。
检查qicard_test.500096945_out_original这个表或节点是否存在于源项目中。
如果在的话,那有可能是依赖有问题,确保所有依赖的上游节点都已正确执行并生成了输出。,另外可以再多重试
当你在DataWorks中尝试进行跨项目的克隆操作并遇到与某个ID相关的错误时,这通常意味着源项目中的某些实体(如表、任务等)引用了一个特定的ID,而目标环境中缺少这个ID或者该ID对应的实体。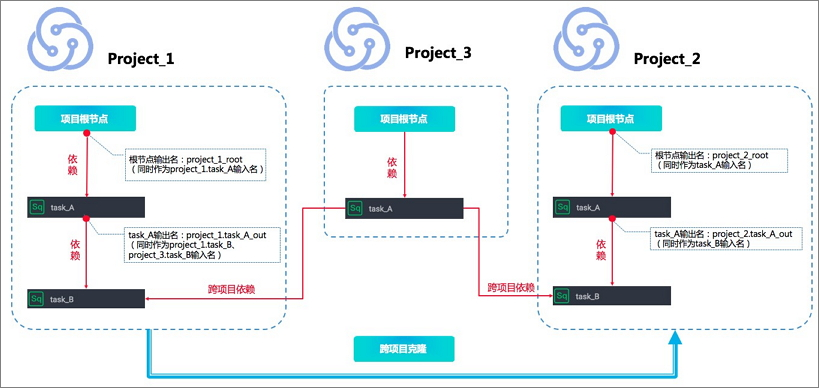
要解决这个问题,你可以按照以下步骤来排查和处理:
确认错误信息:
检查源项目与目标项目的配置差异:
手动创建缺失的实体:
使用DataWorks API或SDK:
调整克隆脚本或流程:
这通常意味着在克隆过程中,目标工作空间中缺少了某些必要的上游节点输出。要解决这个问题,您可以尝试以下步骤:
检查上游节点:确保所有相关的上游节点都存在于目标工作空间中,并且它们的输出名称与克隆过程中所需的名称相匹配。如果上游节点不存在或者输出名称不一致,那么克隆过程将会失败。
提交和发布节点:在DataWorks中,依赖关系解析是基于已经提交和发布的节点信息来进行搜索的。如果某个节点的输出名称被删除了,但是没有提交至调度系统,那么在其他节点上仍然可能搜索到这个已删除的输出名称。因此,确保所有涉及的节点都已经正确提交和发布了。
应该是在尝试跨项目克隆过程中,目标工作空间无法找到或识别源工作空间中指定的上游任务输出。可以确认在源工作空间中,任务qicard_test的输出500096945_out_original确实存在。检查任务配置,确保输出名称正确无误,并且该任务已成功运行至少一次,产生了预期的输出。
上游项目的配置不正确吧。
跨项目依赖任务克隆
project_1中的任务task_B依赖了project_3中的任务task_A,在将project_1. task_B克隆为project_2.task_B之后,依赖关系将一同克隆,即project_2.task_B仍然依赖project_3.task_A。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/overview-42?spm=a2c4g.11186623.0.i156
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


