热门
在视觉智能平台中请问动作行为检测完,想用姿态关键点做后续辅助逻辑判断,这个只能自己再调用一次人体姿势关键点api吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
没有,是需要连续调用两个接口的。此回答整理来自钉群“阿里云视觉智能开放平台咨询1群”。
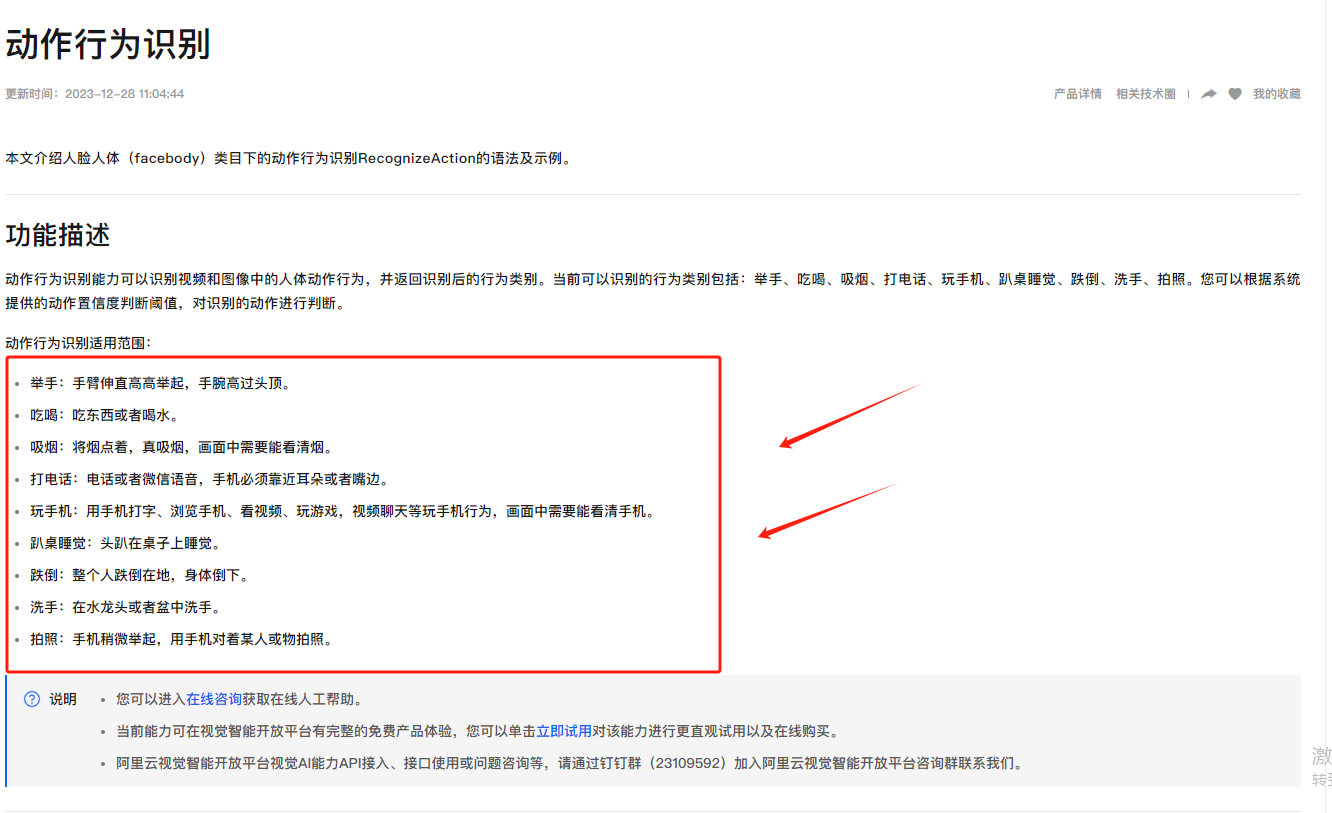
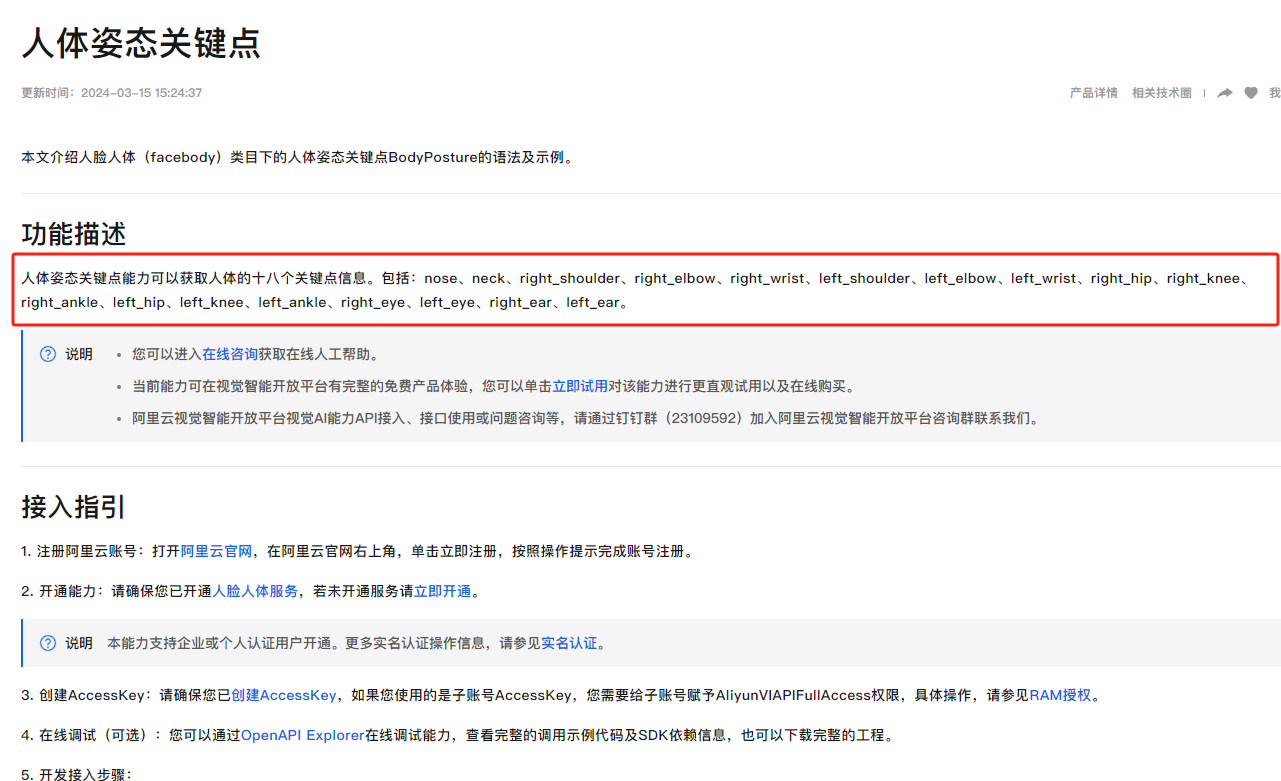
您好,是的。视觉智能开放平台的动作行为识别能力可以识别视频和图像中的人体动作行为,并返回识别后的行为类别参考文档:文档如果进行动作行为识别后向进行人体姿态关键点识别的话,那么您需要调用一次人体姿态关键点的API接口,人体姿态关键点能力可以获取人体的十八个关键点信息参考文档:文档
为开发者提供高易用、普惠的视觉API服务,帮助企业快速建立视觉智能技术应用能力的综合性视觉AI能力平台。适用于数字营销、互联网娱乐、安防、手机应用、泛金融身份认证等行业。