
"在PAI上predict,input表的记录数,和output embedding记录数不一致,这可能是什么问题?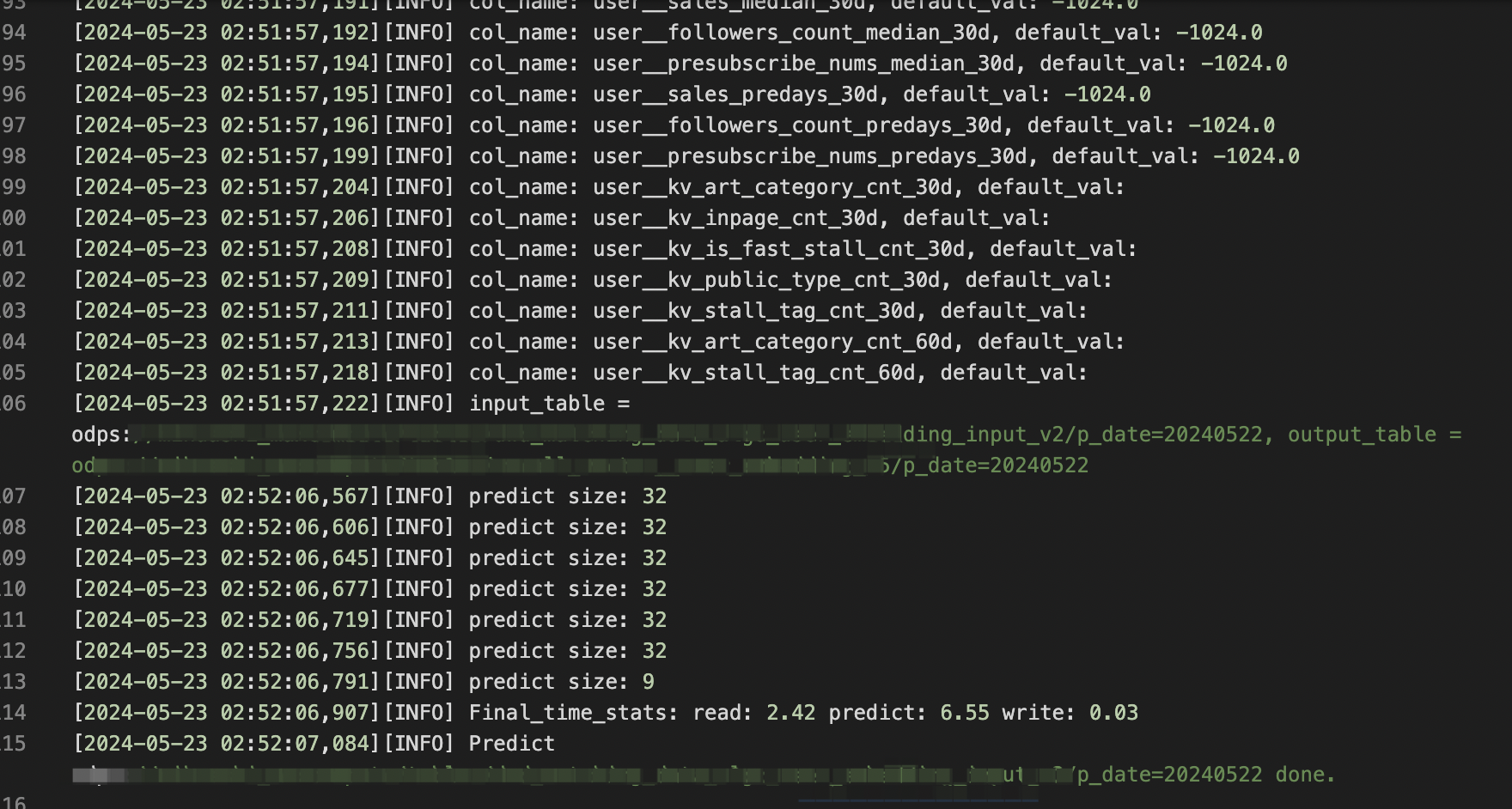
正常情况是完成一个 batch
打印一个这样的日志
progress: batch_num=2000 sample_num=64000
[2024-05-23 02:52:41,349][INFO] time_stats: read: 16.29 predict: 37.69 write: 6.24
这个worker最后只有那些"
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-Dcluster='{
\"worker\" : {
\"count\" : 10,
\"cpu\" : 300,
\"memory\" : 12000
}
}'
再跑一次看看,看不出来问题,发一下logview看看,不应该有这个问题才对[2024-05-23 02:52:06,567][INFO] predict size: 32
[2024-05-23 02:52:06,606][INFO] predict size: 32
[2024-05-23 02:52:06,645][INFO] predict size: 32
[2024-05-23 02:52:06,677][INFO] predict size: 32
[2024-05-23 02:52:06,719][INFO] predict size: 32
[2024-05-23 02:52:06,756][INFO] predict size: 32
[2024-05-23 02:52:06,791][INFO] predict size: 9
[2024-05-23 02:52:06,907][INFO] Final_time_stats: read: 2.42 predict: 6.55 write: 0.03
work1 分到的数据很少。看起来没有问题啊。
看起来是这里的try catch出现异常跳过了,是不是预测数据有错误的特征类型导致的,建议再检查下预测数据https://github.com/alibaba/EasyRec/blob/master/easy_rec/python/inference/predictor.py#L511 ,此回答整理自钉群“【EasyRec】推荐算法交流群”
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。
