哪位大佬有flink k8s operator的监控告警模板吗?求分享~
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink Kubernetes Operator 是一个用于在 Kubernetes 上部署和管理 Apache Flink 集群的工具。监控和告警是确保 Flink 集群稳定运行的关键部分。虽然没有一个标准的监控告警模板适用于所有场景,但你可以根据以下指导原则来创建自己的监控告警模板:
基础监控指标:
JobManager 和 TaskManager 的 CPU 使用率
JobManager 和 TaskManager 的内存使用率
Flink 作业的反压情况
Flink 作业的 checkpoint 情况
Flink 作业的延迟和吞吐量
告警规则:
当 CPU 使用率超过预设阈值时触发告警
当内存使用率超过预设阈值时触发告警
当反压超过预设阈值时触发告警
当 checkpoint 失败或延迟超过预设阈值时触发告警
当作业延迟或吞吐量低于预设阈值时触发告警
告警模板示例:
这里提供一个简单的告警模板示例,你可以根据自己的需求进行调整:
在这个示例中,我们定义了两个告警规则:一个用于监控 JobManager 的 CPU 使用率,另一个用于监控 TaskManager 的内存使用率。这些规则使用 Prometheus 表达式来定义阈值和条件。
集成监控系统:
你需要将这些告警规则集成到你的监控系统中,比如 Prometheus 和 Alertmanager。确保你的监控系统能够收集 Flink 集群的指标,并根据这些规则触发告警。
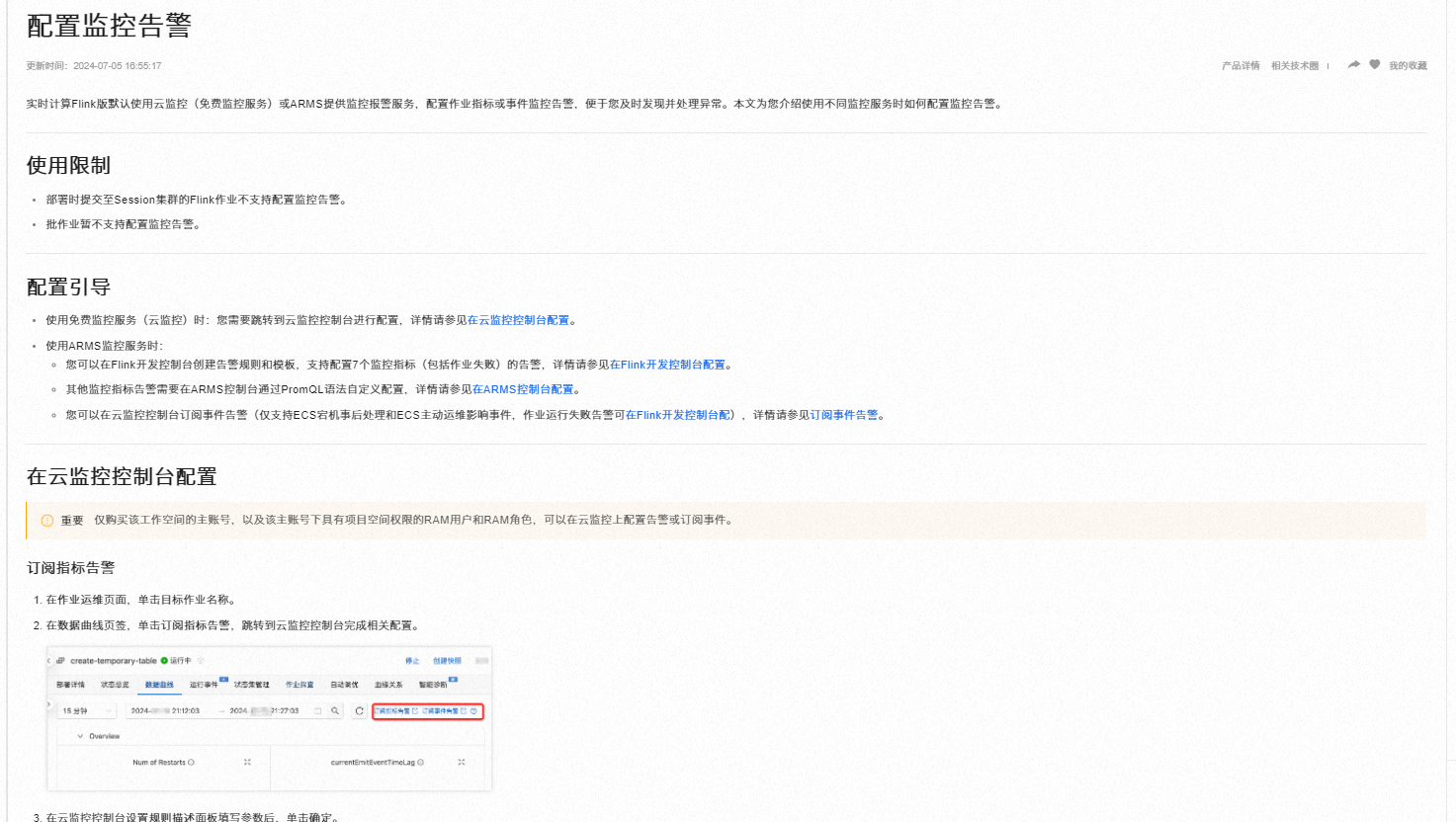
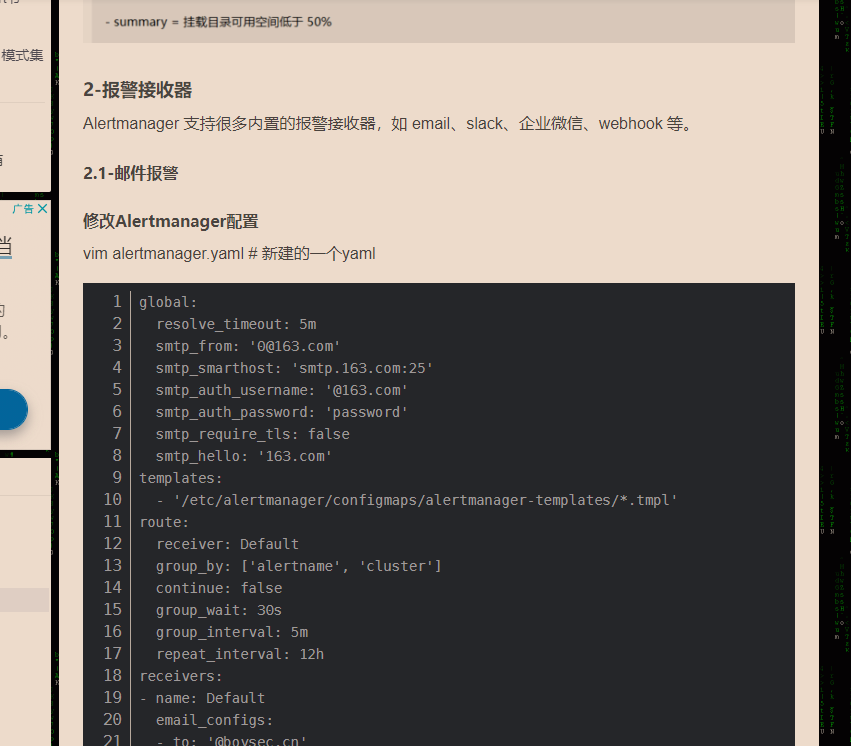
在阿里云平台上配置Flink on Kubernetes(k8s)Operator的监控告警,可以通过以下步骤设置告警模板,尽管直接提及Flink K8s Operator的特定监控告警模板,但可以根据通用的Flink监控配置指导进行调整以适应Kubernetes环境:
虽然没有直接提供Flink K8s Operator的特定监控告警模板,但通过上述步骤和注意事项,您可以根据实际需求在阿里云平台上配置适合Kubernetes环境的Flink应用监控与告警体系。确保充分利用云监控和ARMS的功能,以实现全面且高效的监控管理。
关于Flink K8S Operator的监控告警模板,由于具体的实现可能会因环境、需求以及所使用的监控工具(如Prometheus、Grafana等)的不同而有所差异,因此很难提供一个通用的模板。不过,我可以根据一般性的做法和参考文章中的信息,给出一个大致的框架和步骤,供您参考。
监控告警框架

要在Prometheus中启用operator metrics ,请创建一个包含以下内容的pod-monitor.yaml文件:
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: flink-kubernetes-operator
labels:
release: prometheus
spec:
selector:
matchLabels:
app.kubernetes.io/name: flink-kubernetes-operator
podMetricsEndpoints:
- port: metrics
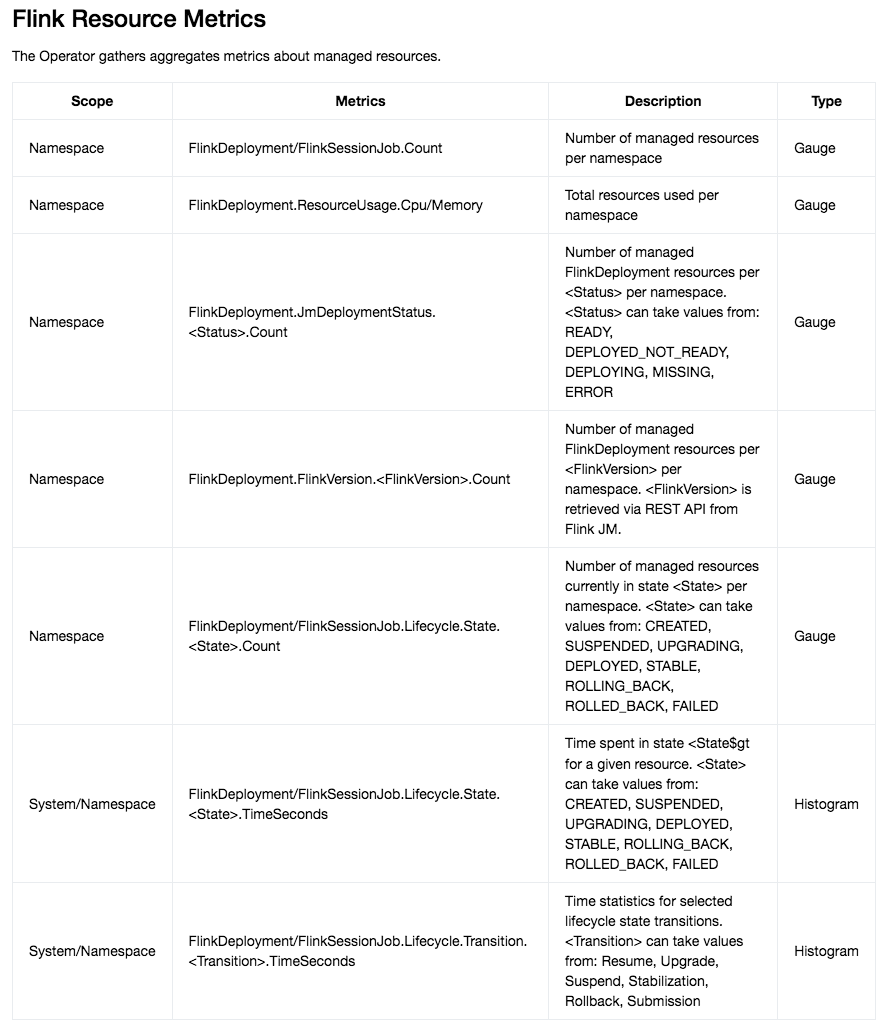
——参考链接。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。