
微服务的粒度到底怎么划分,有什么经验吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这个也是个设计问题,首先是业务必须熟悉,然后可以根据领域模型进行领域划分,拆分可以根据AKF扩展立方体(Scalability Cube)来进行,
这个立方体有三个轴线,每个轴线描述扩展性的一个维度,他们分别是产品、流程和团队:
X轴 —— 代表无差别的克隆服务和数据,工作可以很均匀的分散在不同的服务实例上;
Y轴 —— 关注应用中职责的划分,比如数据类型,交易执行类型的划分;
Z轴 —— 关注服务和数据的优先级划分,如分地域划分。
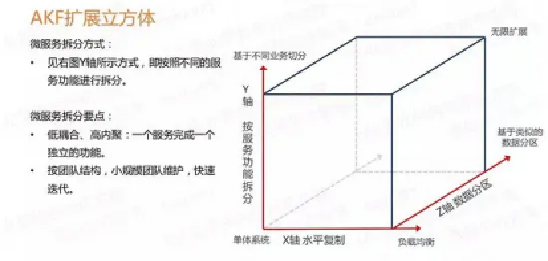
一、三个维度扩展的对比(划分)
通过这三个维度上的扩展,可以快速提高产品的扩展能力,适应不同场景下产品的快速增长。不同维度上的扩展,有着不同的优缺点:
1.X轴扩展
优点:成本最低,实施简单;
缺点:受指令集多少和数据集大小的约束。当单个产品或应用过大时,服务响应变慢,无法通过X轴的水平扩展提高速度;
场景:发展初期,业务复杂度低,需要增加系统容量。
2.Y轴扩展
优点:可以解决指令集和数据集的约束,解决代码复杂度问题,可以实现隔离故障,可以提高响应时间,可以使团队聚焦更利于团队成长;
缺点:成本相对较高;
场景:业务复杂,数据量大,代码耦合度高,团队规模大。
3.Z轴扩展
优点:能解决数据集的约束,降低故障风险,实现渐进交付,可以带来最大的扩展性。
缺点:成本最昂贵,且不一定能解决指令集的问题;
场景:用户指数级快速增长。
二、如何将理论付诸实践?(经验)
1.为扩展分割应用
X轴:从单体系统或服务,水平克隆出许多系统,通过负载均衡平均分配请求;
Y轴 :面向服务分割,基于功能或者服务分割,例如电商网站可以将登陆、搜索、下单等服务进行Y轴的拆分,每一组服务再进行X轴的扩展;
Z轴 :面向查找分割,基于用户、请求或者数据分割,例如可以将不同产品的SKU分到不同的搜索服务,可以将用户哈希到不同的服务等。
2.为扩展分割数据库
X轴:从单库,水平克隆为多个库上读,一个库写,通过数据库的自我复制实现,要允许一定的读写时延;
Y轴 :根据不同的信息类型,分割为不同的数据库,即分库,例如产品库,用户库等;
Z轴 :按照一定算法,进行分片,例如将搜索按照MapReduce的原理进行分片,把SKU的数据按照不同的哈希值进行分片存储,每个分片再进行X轴冗余。
3.为扩展而缓存
在理想情况下,处理大流量最好的方法是通过高速缓存来避免处理它。从架构层面看,我们能控制的主要有以下三个层次的缓存:
对象缓存:对象缓存用来存储应用的对象以供重复使用,一般在系统内部,通过使用应用缓存可以帮助数据库和应用层卸载负载。
应用缓存:应用缓存包括代理缓存和反向代理缓存,一个在用户端,一个在服务端,目标是提高性能或减少资源的使用量。
内容交付网络缓存:CDN的总原则是将内容推送到尽可能接近用户终端的地方,通过不同地区使用不同ISP的网关缓存,达到更快的响应时间和对源服务的更少请求。
4.为扩展而异步
