
DataWorks数据源已经添加成功,给了连接地址,为什么在同步数据的时候反而通过集群去获取内网地址,进行同步数据呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,即使数据源已经添加成功并给出了连接地址,但在同步数据时选择通过集群去获取内网地址进行同步,这一行为背后有多个原因和考量。以下是对这一现象的详细解释:
一、DataWorks平台特性
DataWorks作为阿里云提供的大数据开发治理平台,支持多种数据源和大数据引擎(如MaxCompute、Hologres、EMR、CDP等)。这些引擎和数据源可能分布在不同的网络环境中,包括公网和私网(内网)。为了优化数据传输效率和安全性,DataWorks在设计时就考虑了如何更有效地在不同网络环境间进行数据同步。
二、内网同步的优势
提高数据传输效率:内网(私网)通常比公网具有更高的带宽和更低的延迟,因此通过内网进行数据同步可以显著提高数据传输效率,减少同步时间。
增强数据安全性:内网传输减少了数据在公网上暴露的风险,提高了数据传输的安全性。对于敏感数据或大规模数据集,这一点尤为重要。
降低传输成本:相比公网传输,内网传输通常不需要支付额外的带宽费用,有助于降低企业的运营成本。
三、DataWorks的实现方式
在DataWorks中,当配置数据源并成功添加连接地址后,系统会根据数据源的实际位置和网络环境,智能地选择最优的数据同步路径。如果数据源和DataWorks集群位于同一VPC(虚拟私有云)或可信的网络环境中,系统就会通过内网进行数据同步。这一过程通常是自动完成的,无需用户手动干预。
四、可能的原因
网络策略配置:阿里云或用户可能配置了特定的网络策略,要求或推荐在特定场景下使用内网进行数据同步。
数据同步策略:DataWorks可能根据同步任务的特性(如数据量大小、同步频率等),自动选择最适合的同步路径。
安全性考虑:为了保障数据在传输过程中的安全性,DataWorks可能会优先选择内网同步。
五、结论
综上所述,DataWorks在同步数据时选择通过集群去获取内网地址进行同步,是出于提高数据传输效率、增强数据安全性和降低传输成本等多方面的考虑。这一行为是DataWorks平台智能调度和优化的体现,有助于提升用户的整体使用体验和数据处理效率。
六、建议
如果用户在使用DataWorks进行数据同步时遇到任何问题或疑问,建议查阅阿里云官方文档或联系阿里云技术支持团队以获取更专业的帮助和解决方案。
当您在DataWorks中配置数据源并成功添加后,同步数据时系统应该是使用配置的数据源连接地址。如果在同步时它尝试通过集群获取内网地址,可能是因为配置的网络连接方式或资源组的网络设置问题。请检查您的资源组网络是否与数据源所在网络连通,确保数据源的白名单包含了资源组的交换机网段或EIP。如果使用的是新版资源组,可能需要配置公网NAT网关和EIP。测试连通性以确认问题所在,详情可参考DataWorks控制台的网络设置和数据源连通性测试步骤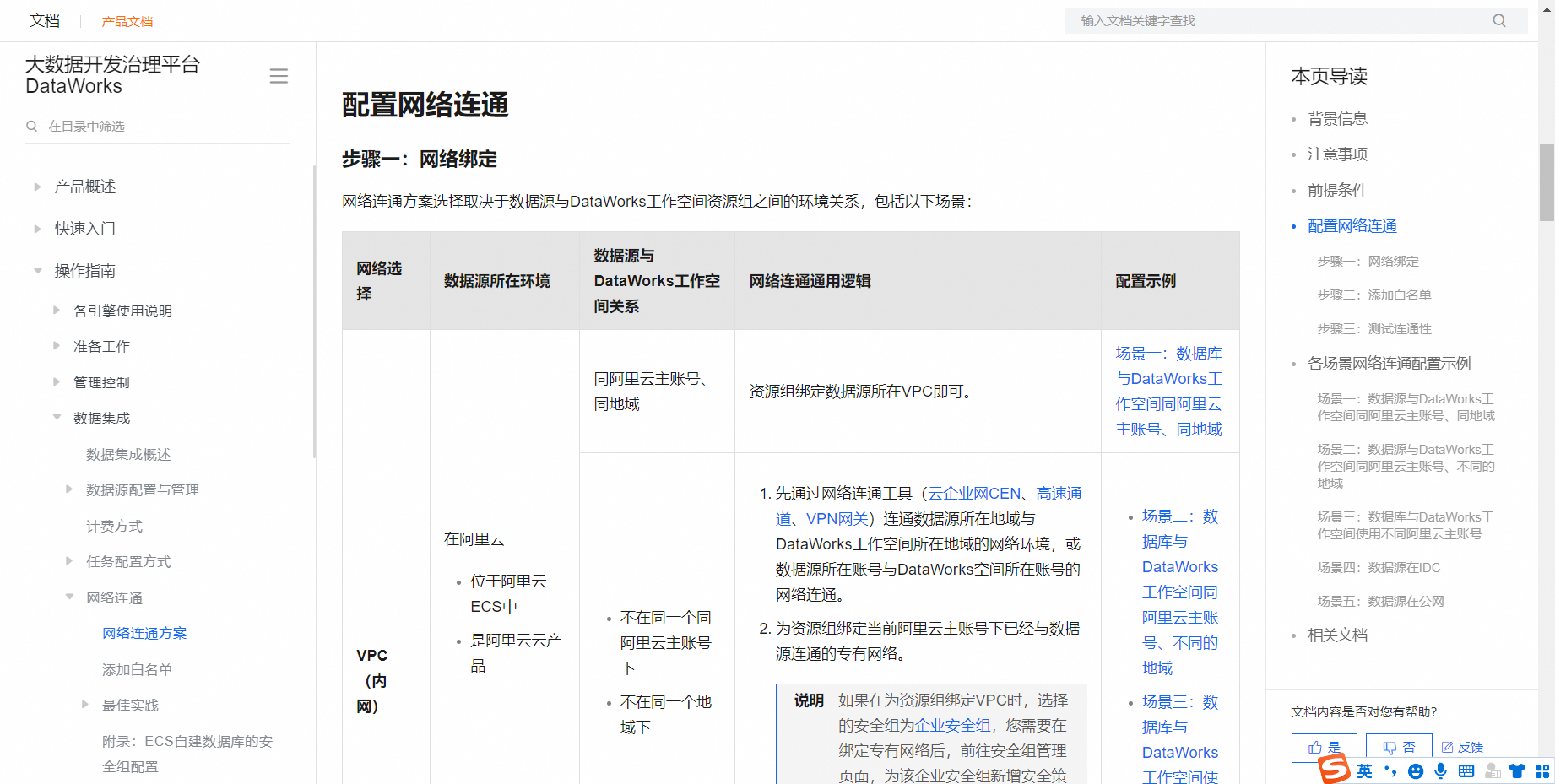
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


