
ToolLLaMa在性能评估方面表现如何?
ToolLLaMa在性能评估方面表现如何?
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
2
条回答
写回答
-
(1)通过率,用于衡量在有限预算内成功执行指令的能力,以及(2)胜率,用于比较两条解路径的质量和有用性。本文证明 ToolEval 与人类评估有很高的相关性,并为工具学习提供了一个强大、可扩展且可靠的评估方式。
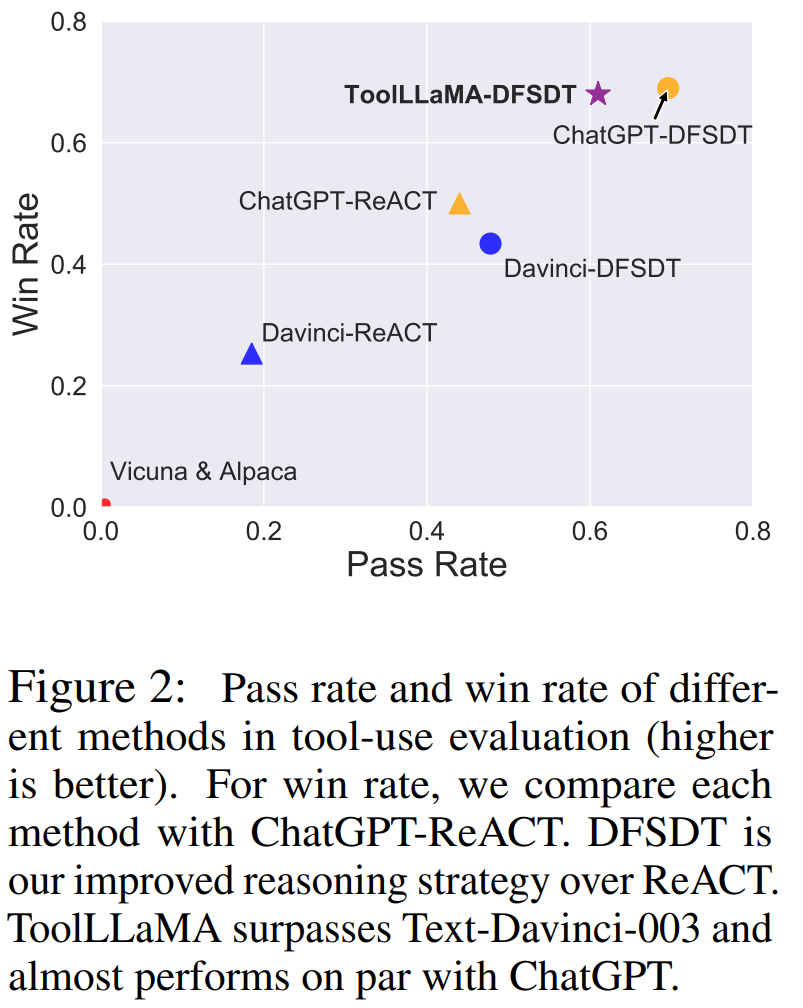
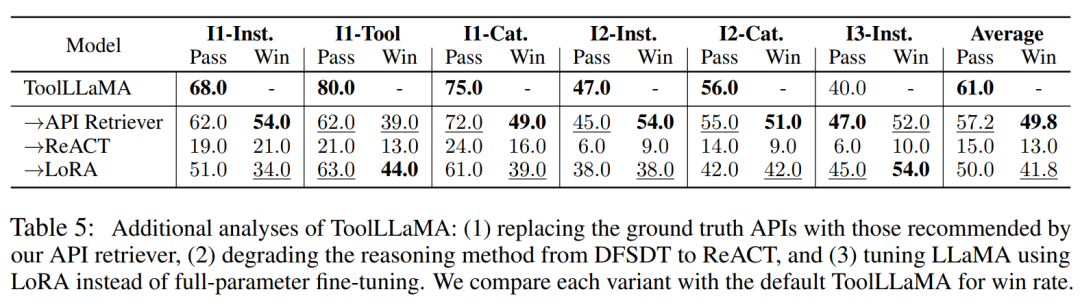
ToolLLaMA 在所有场景中都表现出了竞争力,其通过率略低于 ChatGPT+DFSDT。在获胜率方面,ToolLLaMA 与
ChatGPT+DFSDT 的能力基本相当,在 I2-Cat 设置中甚至超过了后者。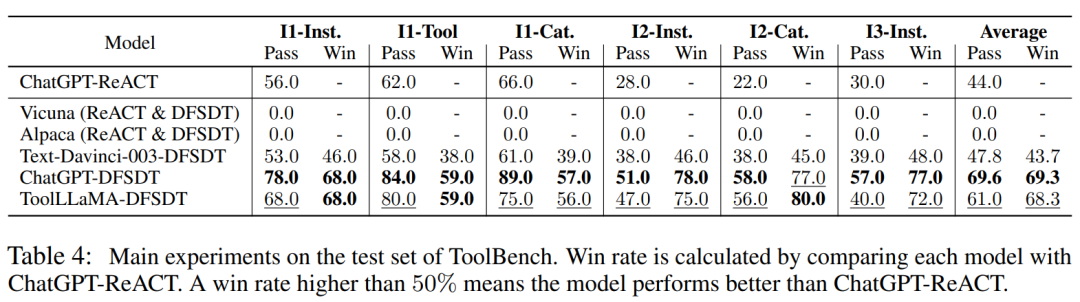
 2024-05-22 15:07:51赞同 1 展开评论
2024-05-22 15:07:51赞同 1 展开评论 -

相关问答