
Flink CDC我也看不出来,我也没有这么大的测试哭,信息太少,只能多加点日志来排查怎么办?
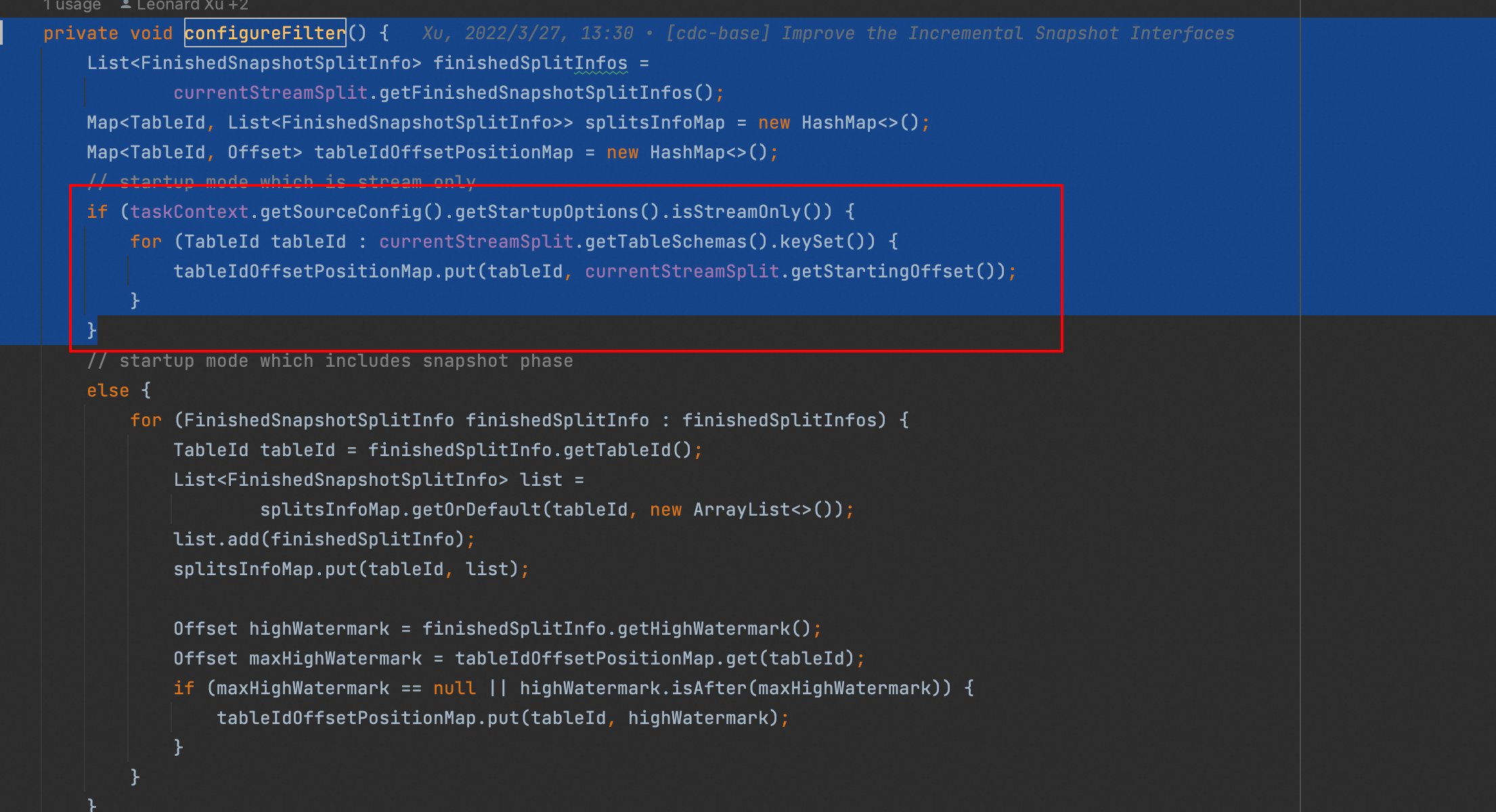
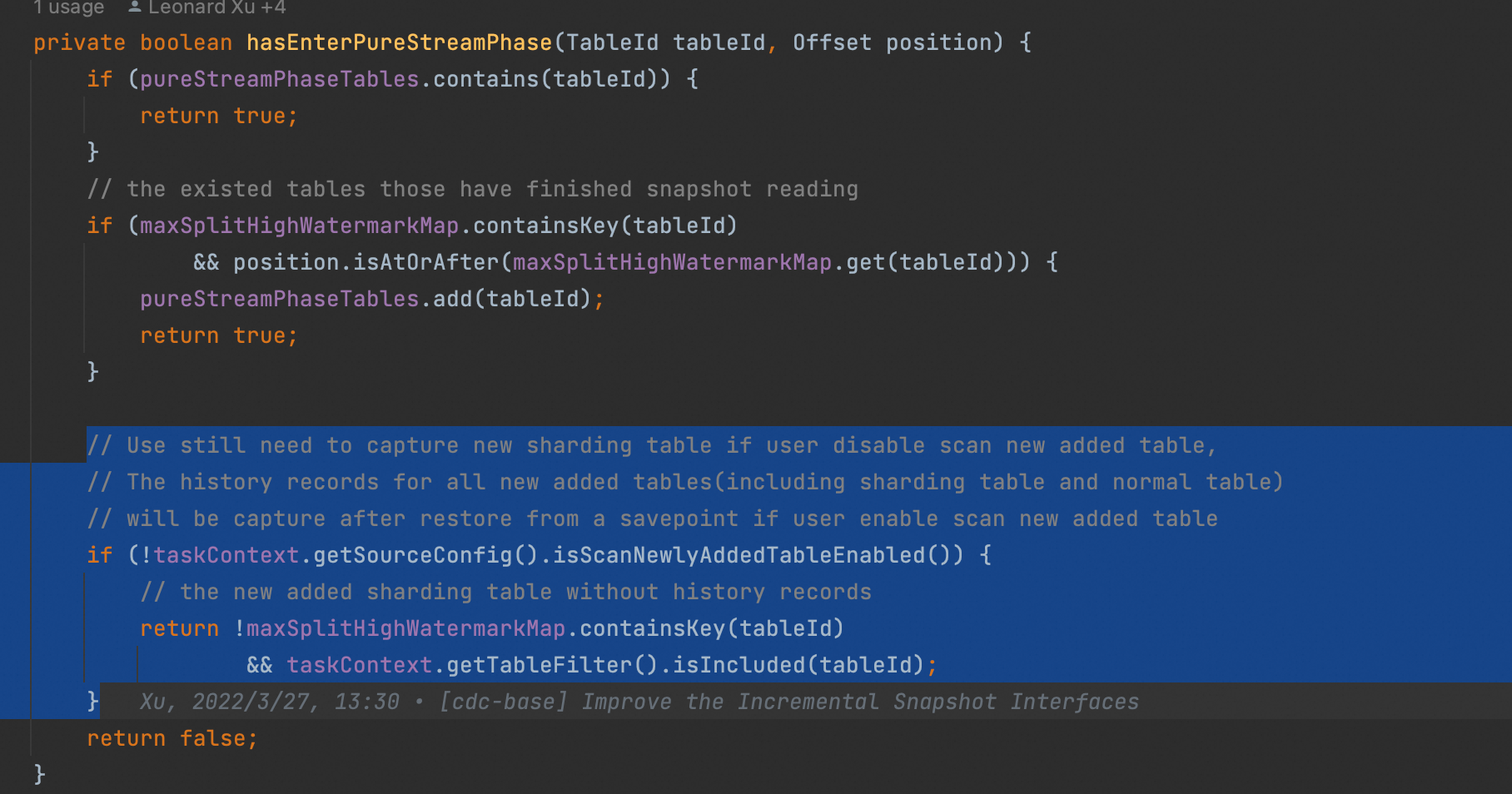
Flink CDC我也看不出来,我也没有这么大的测试哭,信息太少,只能多加点日志来排查。我猜想一种可能?1.先获取schema 2. 加入maxSplitHighWatermarkMap和pureStreamPhaseTables3. 如果上面没有schema查到,采用taskContext.getTableFilter().isIncluded(tableId);判断有没有可能第一步由于schema太多,没获取成功?然后第三步的时候taskContext.getTableFilter().isIncluded(tableId);没匹配上?当数据量少的时候走不到第三步,就读取了?可以在 taskContext.getTableFilter().isIncluded(tableId);加一下日志看看?
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
热门讨论
热门文章
flink的1cu是指1cpu还是1cpu+4g存储?
294
Flink这个未授权访问漏洞有什么解决方案吗?
641
FlinkCDC MySQL 中 scan.startup.mode 用的是什么模式啊?
1963
flink web UI 是不是本身不支持登录认证,必须通过nginx来加登录认证?
651
Caused by: org.apache.kafka.common.errors.TimeoutE
2347
flink1.15启动后无法访问webui的问题有人遇到过吗
9939
flink都是100%占用,请问是什么情况呢?
552
flink怎么能够快速消费kafka数据,需要设置什么参数呢?
408
使用Flink CDC,生产环境要申请的服务器如何评估
862
flink sql 批模式需要咋配置啊?
824
展开全部
流批一体技术简介
49080
数据仓库介绍与实时数仓案例
40464
权威详解 | 阿里新一代实时计算引擎 Blink,每秒支持数十亿次计算
22330
独家专访阿里集团副总裁贾扬清:我为什么选择加入阿里巴巴?
17281
实时计算 Flink SQL 核心功能解密
18713
流计算StreamCompute
18165
阿里云实时计算产品案例&解决方案汇总
25807
接着!!Apache Flink 全领域干货合集(持续更新)
16060
回顾 | Kafka x Flink Meetup 与世界人工智能大会大数据 AI 专场精彩回顾(附PPT下载)
13764
Flink SQL 功能解密系列 —— 流式 TopN 挑战与实现
16056
展开全部




