请教一下Flink,emr-flink 的flinkSQL如何只针对source表单独设置并行度呢?比如kafka source表。
kafka source表如果使用全局并行度的话灵活度会很差,全局并行度比较多的话kafka-topic也没那么多分区。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要在EMR-Flink的Flink SQL中针对source表单独设置并行度,特别是对于Kafka source表,您可以采用以下步骤操作:
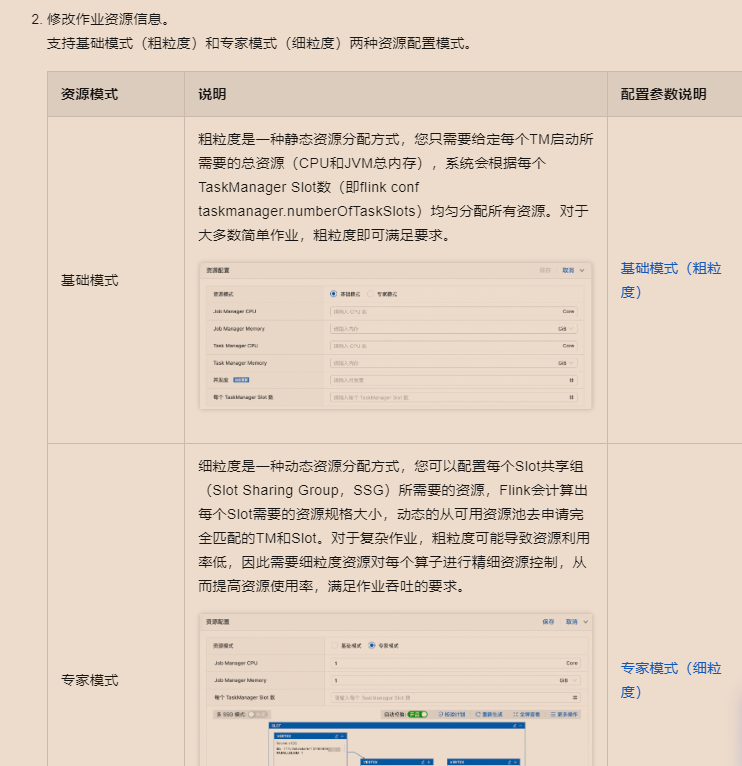
开启多SSG模式:
配置source表的并行度:
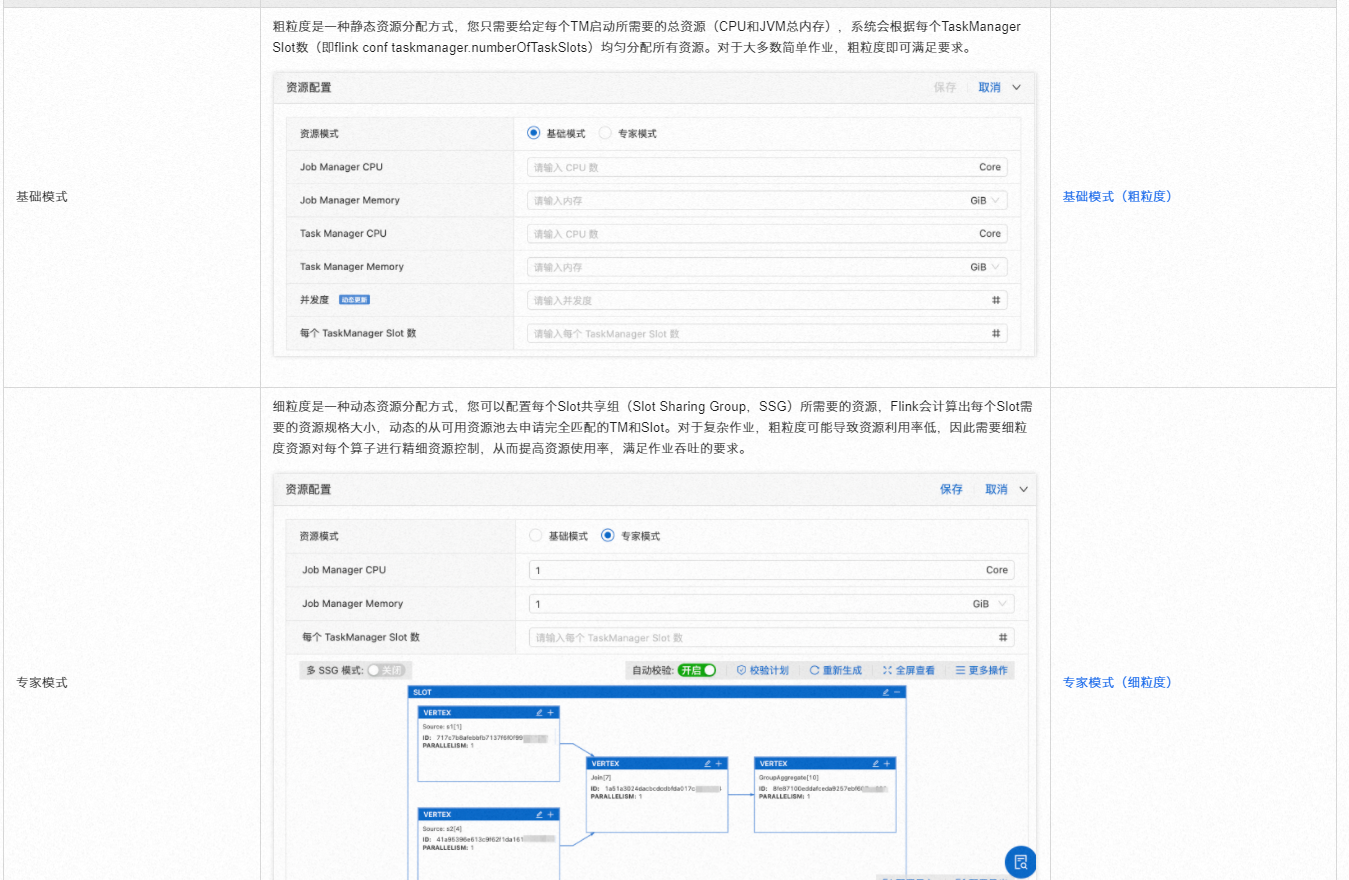
注意事项:
通过上述步骤,您可以在EMR-Flink的Flink SQL作业中为Kafka source表单独设置并行度,以实现更精细化的资源管理和优化作业性能。
相关链接
配置作业资源 专家模式(细粒度) https://help.aliyun.com/zh/flink/user-guide/configure-deployment-resources
Flink的并行度是什么 https://developer.aliyun.com/ask/629934
Flink SQL中Kafka source表设置单独的并行度,您可以在CREATE TABLE语句中使用connector.parallelism属性。以下是一个示例:
设置的并行度应与Kafka Topic的分区数相匹配,因为Flink的并行度通常基于源的分区进行。如果并行度大于Kafka Topic的分区数,可能会导致任务分配不均或数据丢失。根据您的需求,确保并行度设置合理,既能充分利用资源又不会超过Kafka的分区数量。
在 Apache Flink 中,可以通过多种方式来设置并行度。当你使用 Flink SQL 时,可以在 SQL 查询中直接指定 Source 或 Sink 的并行度。对于 EMR-Flink(Elastic MapReduce with Flink),你可以通过 SQL DDL 命令来为特定的表设置并行度。
下面是一个示例,展示如何仅对 source_table 设置并行度:
首先定义一个带有并行度的 Source 表: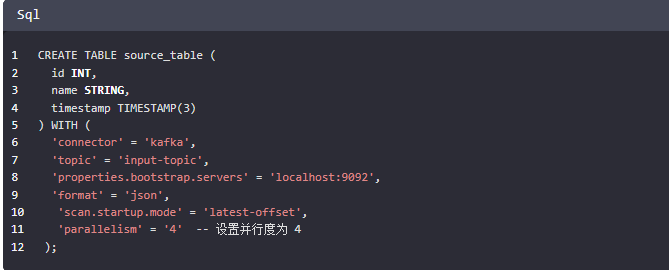
在这个例子中,我们创建了一个名为 source_table 的表,并且通过 'parallelism' 属性指定了并行度为 4。这将使得读取数据的并行度固定为 4。
如果你想要动态地设置并行度,或者想要在已经定义好的表上更改并行度,可以使用如下方法:
使用 SET 语句动态调整并行度:SET 'table.exec.source.parallelism' = '8';然后执行查询或插入操作,这个设置将应用于查询中的所有源表。如果你想只针对某个具体的表设置并行度,你需要在创建表的时候就指定并行度。
请注意,这些设置会覆盖默认的全局并行度配置。如果需要的话,你也可以在 Flink 配置文件中设置全局并行度。
例如,在 flink-conf.yaml 文件中设置全局并行度:parallelism.default: 8
基于 Flink Streaming api,要给 Kafka Source 指定并行度,只需要在 env.addSource() 后面调用 setParallelism() 方法指定并行度就可以,如下:
val kafkaSource = new FlinkKafkaConsumer[ObjectNode](topic, new JsonNodeDeserializationSchema(), Common.getProp)
val stream = env.addSource(kafkaSource)
.setParallelism(12)
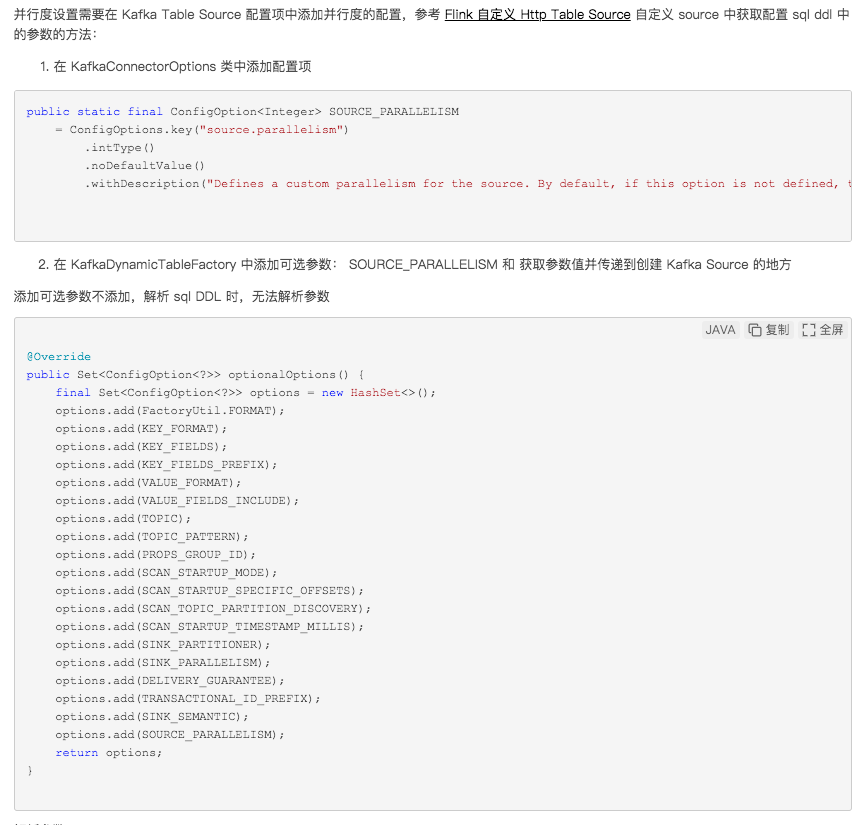
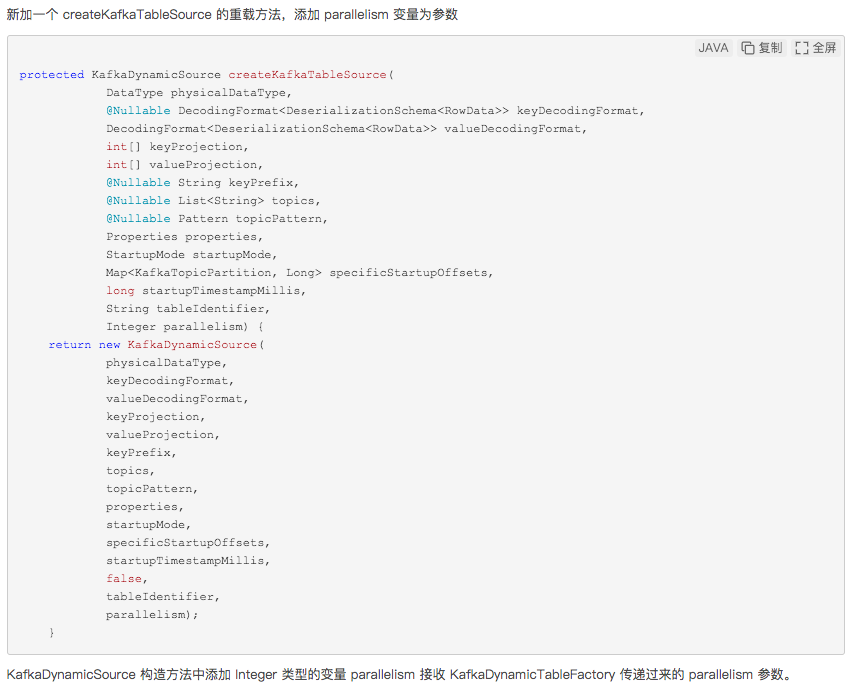
——参考链接。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。