
在按照本地方案推理配置教程中进行模型推理的时候,为啥还需要访问www.modelscope.cn的80端口呢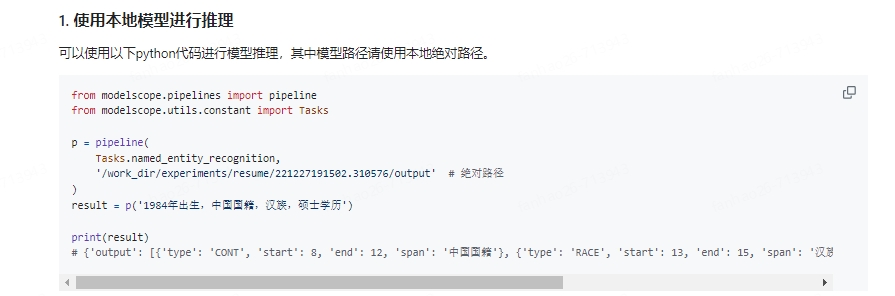
,个人使用的时候是下载了这里的所有文件:https://modelscope.cn/models/iic/nlp_raner_named-entity-recognition_chinese-base-ecom-50cls/files
,然后按照如下配置进行本地模型推理的,请问有什么配置错误了吗?
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
ner_pipeline = pipeline(Tasks.named_entity_recognition, "*/nlp_raner_named-entity-recognition_chinese-base-ecom-50cls")
result = ner_pipeline('eh 摇滚狗涂鸦拔印宽松牛仔裤 情侣款')
print(result)
在您描述的场景中,您尝试通过本地文件进行模型推理,但仍然需要访问 www.modelscope.cn 的 80 端口。这种现象可能与 ModelScope SDK 的工作机制以及您的配置方式有关。以下是详细分析和解决方案:
ModelScope 是一个模型开放平台,其 SDK 在加载模型时,默认会尝试从远程服务器(如 www.modelscope.cn)下载模型文件或元数据。即使您已经手动下载了模型文件并放置在本地路径,SDK 可能仍然会尝试访问远程服务以验证模型的完整性、获取额外的配置信息或更新缓存。
关键点: - SDK 默认行为是优先从远程仓库拉取模型。 - 如果未正确指定本地路径或未禁用远程访问,SDK 会尝试连接到 www.modelscope.cn。
根据您提供的代码片段:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
ner_pipeline = pipeline(Tasks.named_entity_recognition, "*/nlp_raner_named-entity-recognition_chinese-base-ecom-50cls")
result = ner_pipeline('eh 摇滚狗涂鸦拔印宽松牛仔裤 情侣款')
print(result)
"*/nlp_raner_named-entity-recognition_chinese-base-ecom-50cls" 作为模型路径。这里的 * 是通配符,表示当前目录下的某个子目录。如果路径不明确,SDK 可能无法正确找到本地模型文件,从而回退到远程仓库。ner_pipeline = pipeline(Tasks.named_entity_recognition, "/path/to/local/model/nlp_raner_named-entity-recognition_chinese-base-ecom-50cls")
~/.cache/modelscope/ 目录下。如果您之前运行过其他代码,SDK 可能已经缓存了部分远程模型文件,并尝试重新验证这些文件。rm -rf ~/.cache/modelscope/
DASHSCOPE_API_KEY 或其他相关环境变量,SDK 可能会尝试访问远程服务以获取默认配置。为了完全避免访问 www.modelscope.cn,您可以按照以下步骤调整配置:
将模型路径替换为绝对路径,确保 SDK 能够直接加载本地文件。例如:
ner_pipeline = pipeline(
Tasks.named_entity_recognition,
"/absolute/path/to/nlp_raner_named-entity-recognition_chinese-base-ecom-50cls"
)
通过设置环境变量或修改代码,禁用 SDK 的远程访问功能。例如:
import os
os.environ["MODELSCOPE_CACHE"] = "/path/to/local/cache" # 指定本地缓存目录
os.environ["MODELSCOPE_REMOTE"] = "false" # 禁用远程访问
确保您下载的模型文件完整无误,包括以下内容: - config.json - pytorch_model.bin - tokenizer_config.json - vocab.txt 或其他词表文件
如果缺少某些文件,SDK 可能会尝试从远程仓库补全。
您遇到的问题主要是由于 ModelScope SDK 的默认行为导致的。通过明确指定本地模型路径、禁用远程访问以及验证模型文件完整性,可以有效解决该问题。如果仍有疑问,请检查 SDK 日志输出,定位具体的访问请求来源。
