
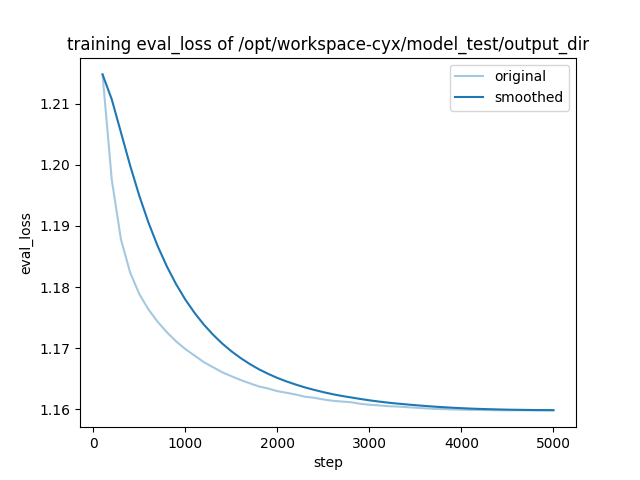
如下是损失图片,验证集损失和训练参数: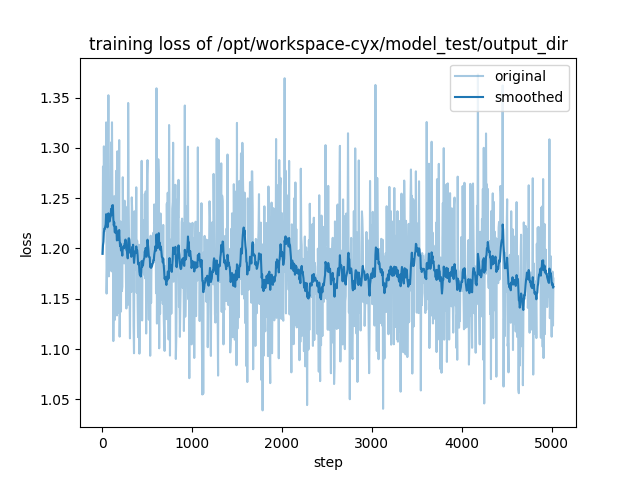
参数:
model_path=/opt/workspace-cyx/model_test/Qwen1.5-14B
train_dataset_dir=alpaca_gpt4_data_en,alpaca_gpt4_data_zh,oaast_sft_zh,oaast_sft
per_device_train_batch_size=4
gradient_accumulation_steps=2
output_dir=/opt/workspace-cyx/model_test/output_dir
accelerate launch --config_file accelerate_config.yaml src/train_bash.py \
--max_samples 1000000 \
--stage sft \
--do_train \
--model_name_or_path ${model_path} \
--dataset ${train_dataset_dir} \
--template qwen \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir ${output_dir} \
--per_device_train_batch_size ${per_device_train_batch_size} \
--gradient_accumulation_steps ${gradient_accumulation_steps} \
--lr_scheduler_type cosine \
--logging_steps 5 \
--save_steps 2000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
--do_eval
--save_steps 100 \
--eval_steps 100 \
--val_size 0.01 \
--evaluation_strategy steps \
Qwen和Qwen1.5的7B和14B都有微调,使用的是llama_factory自带的alpaca_gpt4_data_en,alpaca_gpt4_data_zh,oaast_sft_zh,oaast_sft这四个数据集。
训练历程:
1.我初步想的是不是参模型不适用,但是试了好几个千问的模型,都有不同程度的震荡
2.然后开始修改参数,但是修改batch-size,lora_rank等参数,结果还是相差无几
3.数据集是官方提供的,应该是没有问题,总的指令有几十W条
现在的想法是:
1.这个模型到底是不是有没有收敛,是不是模型训练没有问题,只是Qwen1.5能力很强,对于这些数据集接收能力很强,正常震荡【因为验证集没啥问题】
2.参数/数据集存在问题,但是调过很多次了还是没能解决
不知道大家在微调有没有遇到此类问题,是如何解决的,还希望有大佬为我解惑!
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里云自主研发的千问大模型,凭借万亿级超大规模数据训练和领先的算法框架,实现全模态高效精准的模型服务调用。https://www.aliyun.com/product/tongyi
