
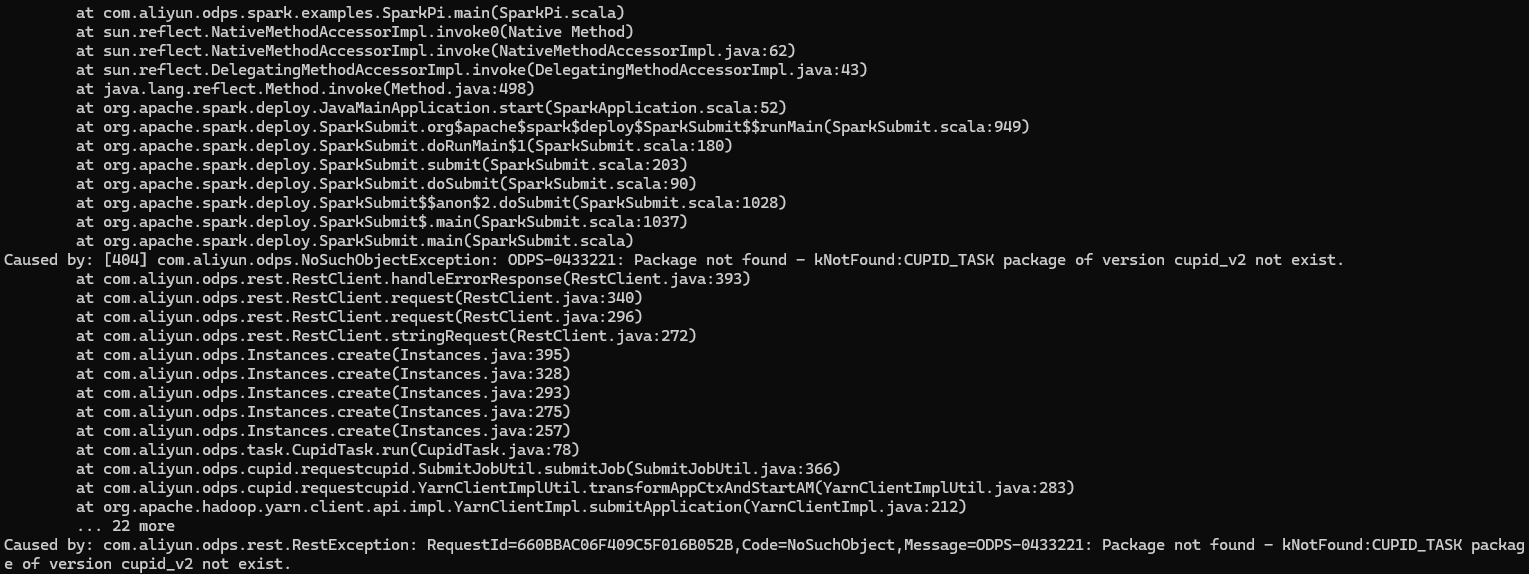
大数据计算MaxCompute在做 maxcomputer-spark 的 sparkPI 冒烟测试的时候 按照文档一步步进行的话出现 package not found 错误. 有谁知道是为什么吗?用的是 spark-3.1.1-odps0.34.1 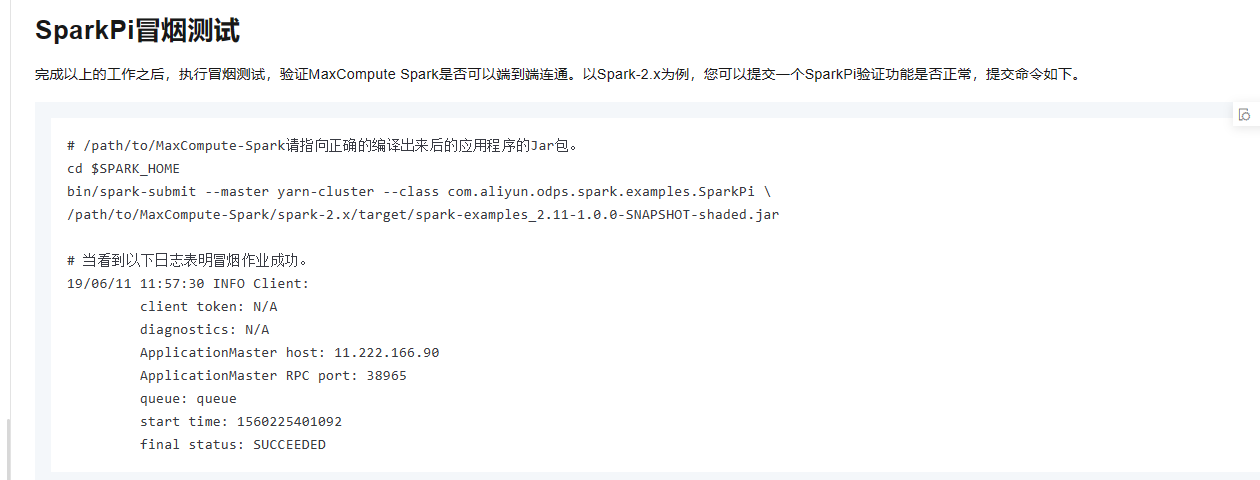
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在进行 MaxCompute-Spark 的 SparkPi 冒烟测试时,如果出现 package not found 错误,可能是由于以下原因导致的。以下是详细的分析和解决方法:
package not found 错误通常表明 Spark 作业所需的依赖未正确加载或未包含在提交的 JAR 包中。pom.xml 文件中添加相关依赖。例如:
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>hadoop-fs-oss</artifactId>
<version>3.3.8-public</version>
</dependency>
pom.xml 配置文件,确保所有必要的依赖均已包含。shade 插件以将所有依赖打包到一个可执行的 JAR 文件中。例如:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
jar tf /path/to/your/spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar
spark-3.1.1-odps0.34.1,可能存在 Spark 版本与 MaxCompute 客户端版本不兼容的情况。odps.conf 中指定相关配置项,例如:
odps.access.id=""
odps.access.key=""
odps.end.point=""
odps.project.name=""
spark.master 或未加载依赖。spark.master 为 local[N],例如:
val spark = SparkSession
.builder()
.appName("SparkPi")
.config("spark.master", "local[4]") // 设置并发数为4
.getOrCreate()
Jars 目录。根据知识库中的说明,需要手动将客户端的 Jars 目录添加至项目工程中。spark-submit \
--class com.aliyun.odps.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
/path/to/your/spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar
com.aliyun.odps.spark.examples.SparkPi 是否存在于 JAR 包中。odps.access.id、odps.access.key 和 odps.end.point。通过以上步骤,您可以逐步排查并解决 package not found 错误。重点在于确保依赖配置正确、JAR 包完整、版本兼容以及提交命令无误。如果问题仍然存在,建议参考官方文档或联系技术支持获取进一步帮助。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

