
使用Flink CDC + debezium 同步 sql Server 数据时,处理schemaChangeEvent时报错,怎么解决?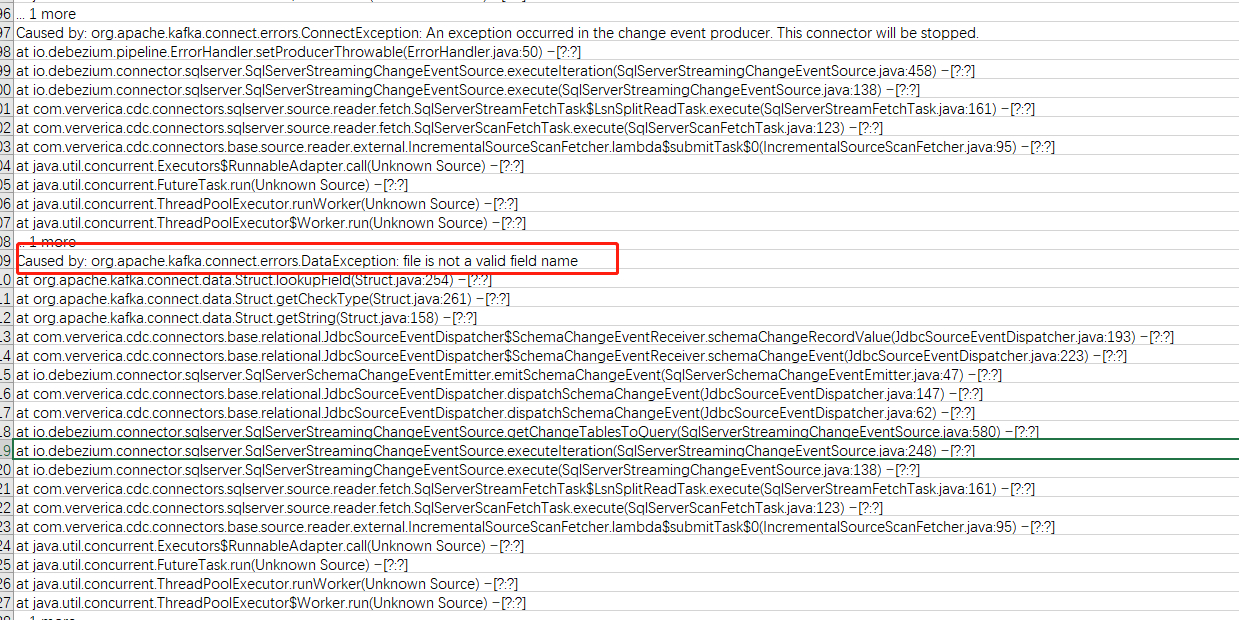
Caused by: org.apache.kafka.connect.errors.DataException: file is not a valid field name 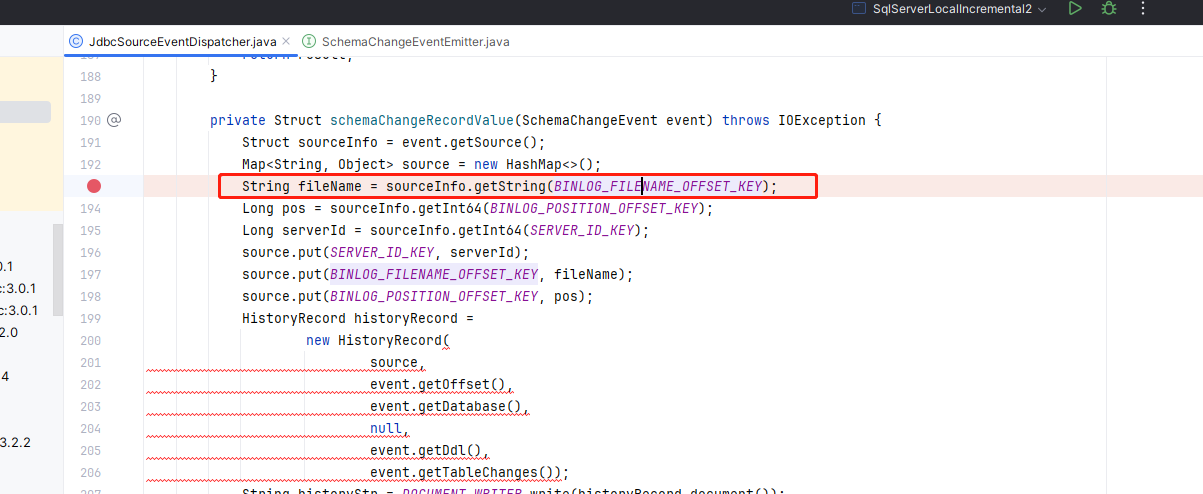
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
https://github.com/apache/flink-cdc/pull/2078/files 可以参考这个来简单改下打 snapshot 包。另外可以把本地降级试一下。此回答整理自钉群“实时计算Flink产品交流群”
在使用Flink CDC结合Debezium同步SQL Server数据时遇到报错,可以采取以下步骤进行解决:
检查数据库权限:确保使用的账号拥有对应数据库的访问权限。如果作业中包含多个数据库的表,需要检查账号是否对所有涉及的数据库都有必要的权限。
验证表名存在性:确认报错中提到的表名是否真实存在于数据库中。如果表名不存在,需要修正为正确的表名。
检查CDC配置:确认CDC的配置是否正确,包括监控的表、数据变更捕获的设置等。CDC(Change Data Capture)是数据库的一项功能,能够监控数据库表的变化,因此需要确保配置正确以捕获所需的数据变更。
审查Debezium和Kafka协同工作:检查Debezium是否正确地与Kafka协同工作。Debezium作为一个变更日志源,需要正确地注册为Flink表,以便将消息作为数据变更来处理。
简化实时链路:考虑通过Flink CDC connectors替换Debezium+Kafka的数据采集模块,实现Flink SQL采集+计算+传输(ETL)的一体化,这样可以减少维护的组件,简化实时链路。
查看日志和错误信息:仔细查看Flink作业的日志和错误信息,这些信息往往能提供关于错误的具体原因和上下文。
寻求社区帮助:如果以上步骤无法解决问题,可以在Flink或Debezium的官方论坛、社区或GitHub仓库中寻求帮助,可能有其他用户遇到过类似的问题并提供了解决方案。
联系技术支持:如果问题依然无法解决,可以考虑联系Flink或Debezium的技术支持团队,他们可能会提供专业的技术协助。
综上所述,解决此类问题通常需要对Flink CDC、Debezium以及SQL Server的权限和配置有一定的了解。在排查问题时,建议从账号权限和表名存在性入手,然后逐步深入到CDC配置和与Kafka的协同工作,最后考虑实时链路的简化。通过这些步骤,通常可以找到导致报错的原因并加以解决。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

