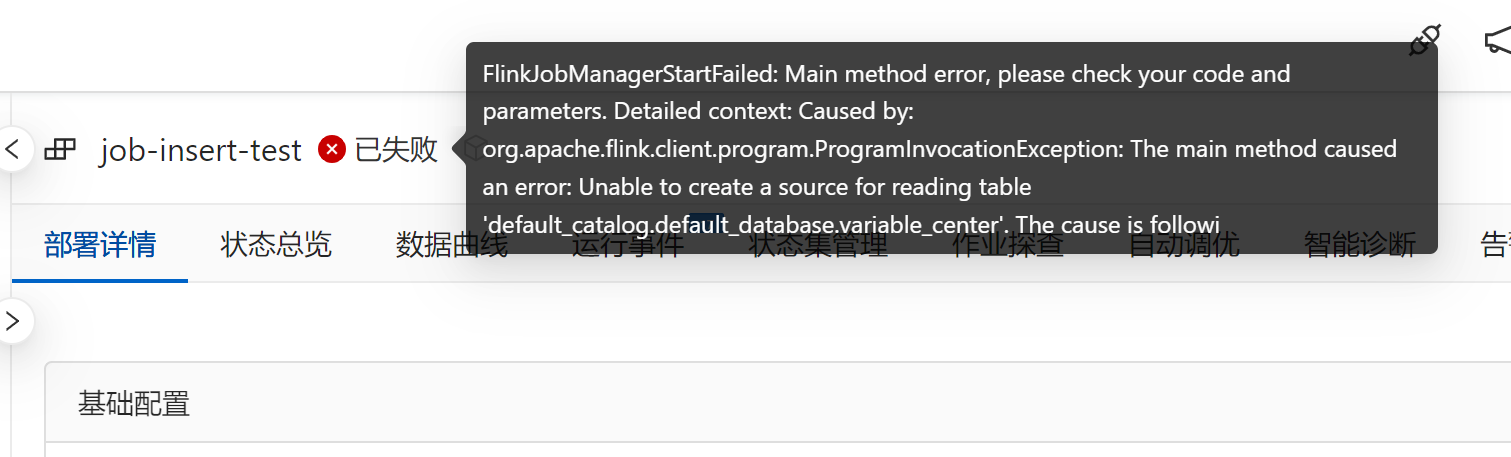
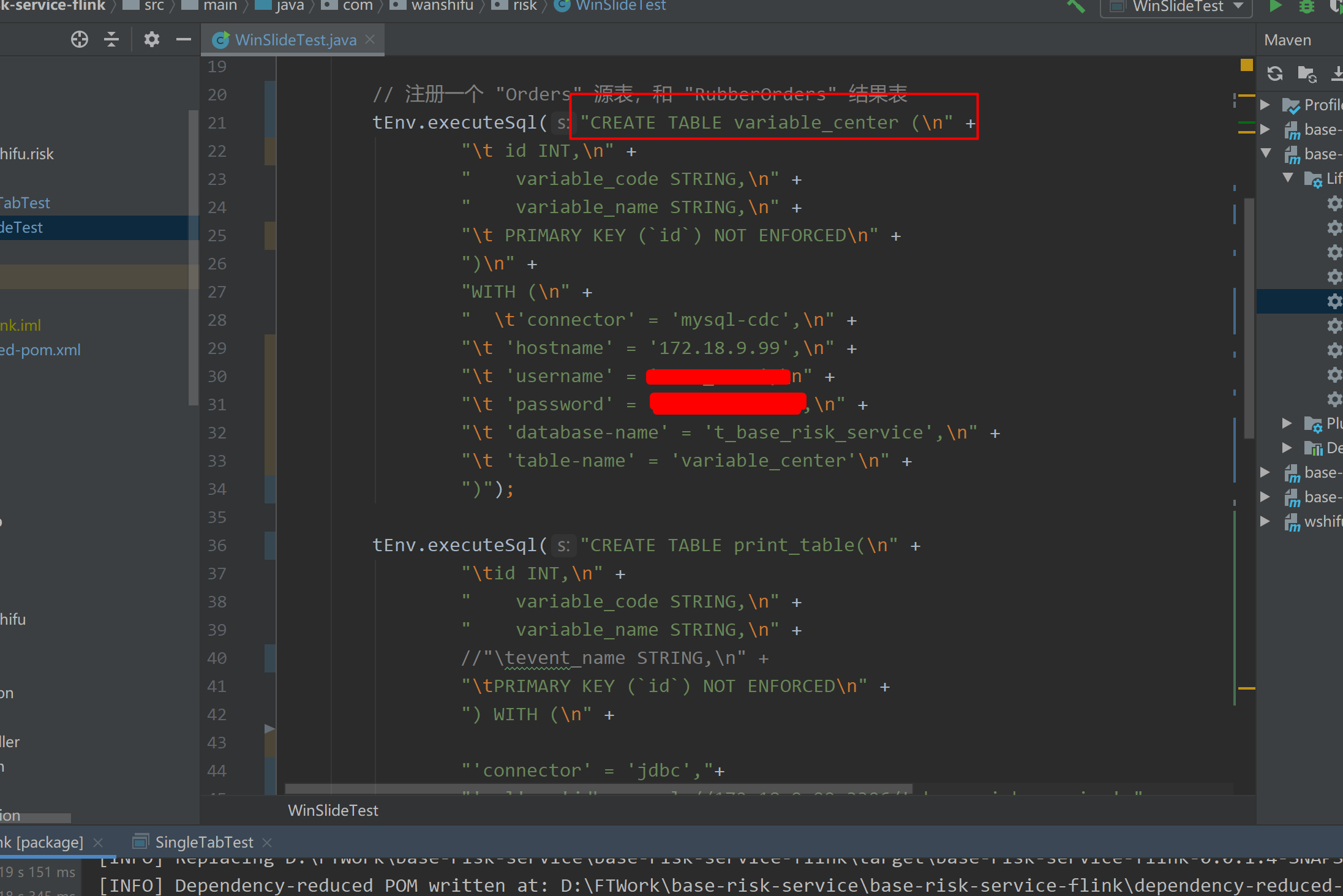
在本地运行Flink作业时可以正常执行,但上传到阿里云实时计算Flink版后报错,这种情况通常与以下因素有关。以下是可能的原因及解决方案:
1. 连接器版本不一致
- 问题描述:本地运行时使用的连接器版本可能与实时计算Flink版支持的版本不一致。例如,某些连接器(如MaxCompute、Kafka等)在本地调试时可能使用了未加密或非商业化的版本,而实时计算Flink版要求使用特定的商业化加密版本。
- 解决方案:
- 确保本地开发和实时计算Flink版使用相同的连接器版本。
- 下载并使用实时计算Flink版官方提供的连接器JAR包(可通过Connector列表获取)。
- 如果需要本地调试,请参考文档中提到的
pipeline.classpaths配置方法,加载包含运行类的uber JAR包。
2. 缺少必要的依赖文件
- 问题描述:实时计算Flink版对作业的依赖文件有严格的管理要求。如果某些依赖文件未正确上传或配置,可能会导致运行时找不到相关类。
- 解决方案:
- 在实时计算控制台中,通过文件管理页面上传所有必要的依赖文件(包括连接器JAR包和其他第三方依赖)。
- 在作业部署时,确保在附加依赖文件项中选择正确的依赖文件路径。
- 如果是Python作业,还需上传PyFlink的官方JAR包,并确保Python作业文件路径填写正确。
3. ClassLoader配置问题
- 问题描述:实时计算Flink版对连接器的ClassLoader有特殊要求。如果未正确配置ClassLoader,可能会导致连接器类无法被加载。
- 解决方案:
- 下载并添加
ververica-classloader-1.15-vvr-6.0-SNAPSHOT.jar到本地运行环境。
- 在IntelliJ IDEA中修改运行配置,将ClassLoader JAR包添加到运行时的classpath中。
- 确保在上传到实时计算Flink版之前,删除本地调试时添加的
pipeline.classpaths配置。
4. 网络连通性问题
- 问题描述:实时计算Flink版运行环境可能与外部服务(如Kafka、MySQL等)存在网络隔离。即使本地运行时网络连通,上传后仍可能出现连接超时等问题。
- 解决方案:
- 检查Flink作业是否能够访问外部服务的Endpoint。例如,对于Kafka,确认其metadata中的Endpoint信息是否可被Flink解析。
- 如果使用域名,请为Flink配置对应的域名解析服务。
- 确保本地公网IP地址已添加到外部服务的白名单中。
5. API兼容性问题
- 问题描述:虽然Flink的DataStream API在本地和云端理论上是一致的,但实时计算Flink版可能对某些API参数或功能进行了限制或增强。例如,某些高版本API参数可能在低版本环境中不可用。
- 解决方案:
- 确保本地开发环境和实时计算Flink版的Flink版本一致。
- 避免使用高版本API参数,尤其是在打包作业时。
6. 其他常见问题
- 问题描述:某些特定场景下的限制可能导致作业在云端运行失败。例如:
- Python作业中依赖的第三方JAR包可能与Flink运行环境的JDK版本不兼容。
- 实时计算引擎VVR版本升级后,可能需要重新测试和部署作业。
- 解决方案:
- 确保Python作业中依赖的第三方JAR包与Flink运行环境的JDK版本兼容。
- 如果升级了实时计算引擎VVR版本,请重新测试并部署作业。
总结
本地运行和云端运行环境的差异可能导致作业在上传后报错。建议从以下几个方面逐一排查: 1. 确认连接器版本一致性。 2. 检查依赖文件是否完整上传。 3. 配置正确的ClassLoader。 4. 解决网络连通性问题。 5. 确保API参数兼容性。
如果问题仍未解决,建议提供具体的错误日志以便进一步分析。