
如何在datawork pyodps 调用oss啊?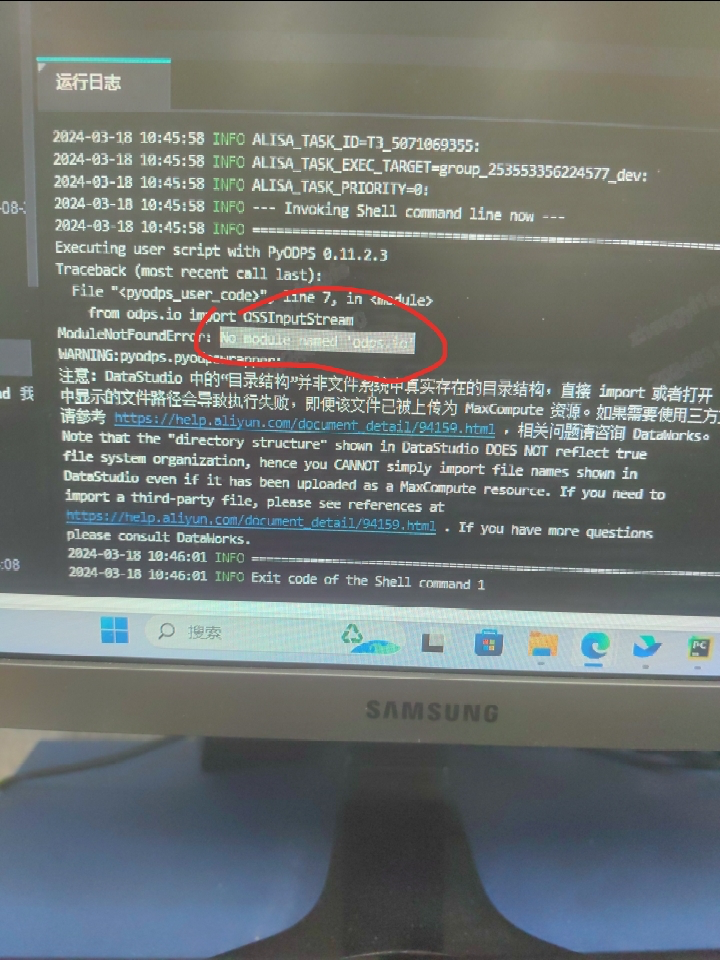
from odps.io import OSSInputStream找不到这个模块?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要在所需的第三方包(例如OSSInputStream所在的包)上传到OSS存储空间。
pip命令来安装包,或者通过其他方式指定包的位置进行安装。from ps.io import OSSInputStream等语句来导入相应的模块,并编写逻辑来读取或写入OSS中的数据。请注意,具体的操作可能需要根据您的DataWorks环境和配置进行调整。如果您在使用过程中遇到from odps.io import OSSInputStream找不到模块的问题,可能是因为您还没有正确安装或导入所需的包。确保您已经按照上述步骤上传并安装了第三方包,并且在PyODPS节点的Python环境中可以访问这些包。
总的来说,以上步骤应该可以帮助您在DataWorks的PyODPS环境中调用OSS。如果仍然有问题,建议查阅官方文档或联系技术支持获取更详细的指导。
要在PyODPS中与OSS交互,主要是通过ODPS表的形式来间接读写OSS数据。例如,您可以创建一个外部表指向OSS中的数据文件,然后像操作普通表一样处理数据。
以下是使用PyODPS读取OSS数据的大致步骤:
from odps import ODPS
# 初始化ODPS客户端
o = ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>')
# 创建一个外部表指向OSS中的数据文件
table_name = 'my_oss_table'
external_table_schema = ['col1 string', 'col2 int'] # 根据实际数据定义列名和类型
location = 'oss://<your-bucket>/<your-object-key>'
if not o.exist_table(table_name):
o.create_external_table(table_name, external_table_schema, 'oss', properties={'odps.properties.table.oss.endpoint': '<your-oss-endpoint>'}, location=location)
# 通过ODPS读取OSS数据
table = o.get_table(table_name)
instance = table.open_reader()
reader = instance.create_record_reader()
# 遍历数据
for record in reader:
print(record)
# 不再需要时记得释放资源
reader.close()
instance.close()
如果需要直接操作OSS文件,而不是通过ODPS表,您可以使用阿里云官方提供的Python SDK aliyun-oss-python-sdk 直接操作OSS对象。安装这个SDK后,您可以直接读写OSS对象:
pip install oss2
import oss2
auth = oss2.Auth('<your-access-key-id>', '<your-access-key-secret>')
bucket = oss2.Bucket(auth, '<your-oss-endpoint>', '<your-bucket-name>')
# 读取OSS文件内容
content = bucket.get_object('<your-object-key>').read()
# 写入OSS文件
bucket.put_object('<your-object-key>', '<file-content-or-bytes>')
请注意替换上述代码中的占位符为您自己的阿里云账户、OSS终端节点、Bucket名和对象Key等信息。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


