
大数据计算MaxCompute数据分区是pt,country,app_type 他还会按照其他key来倾斜吗?这是我对数据做了个查询 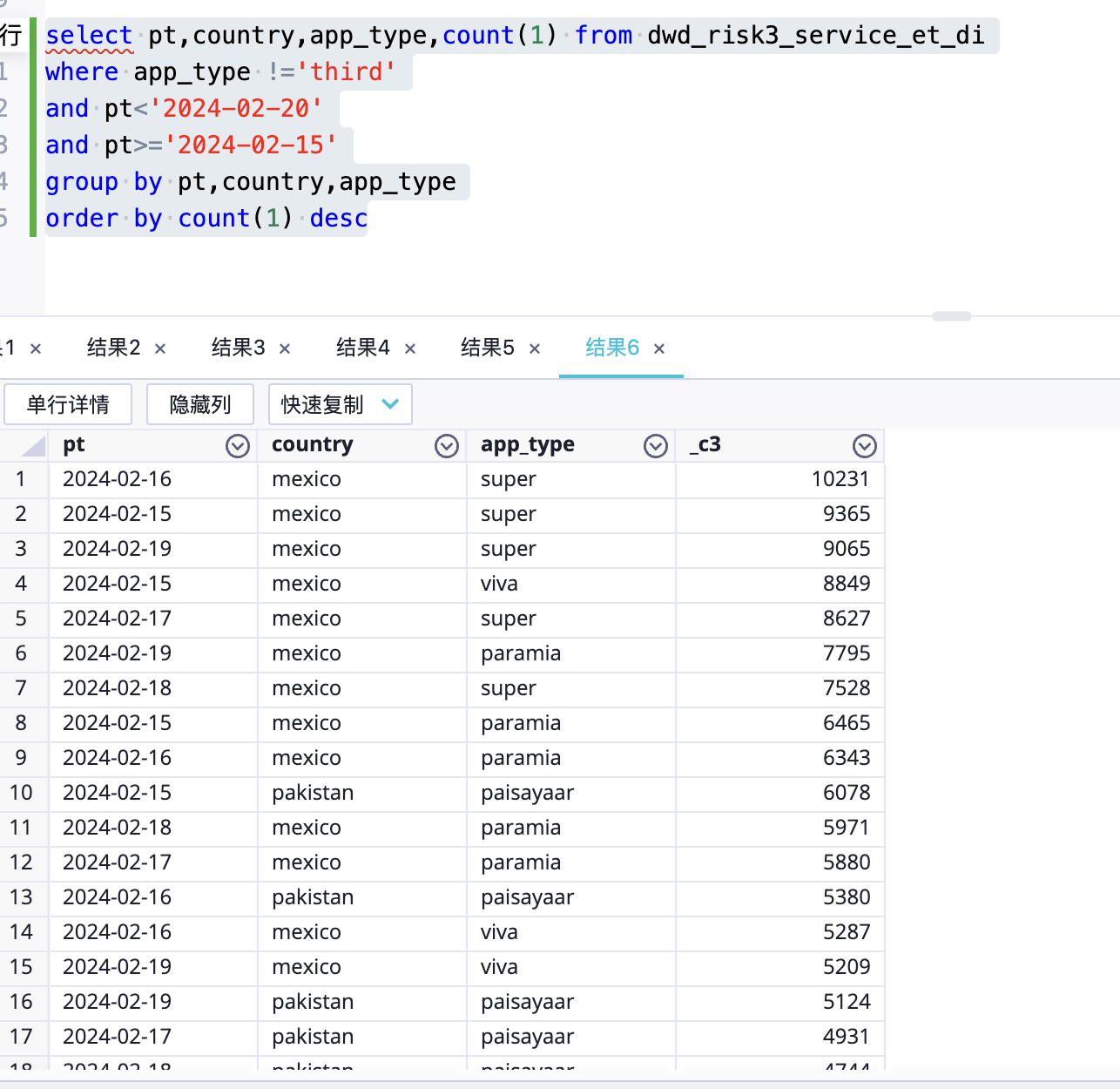
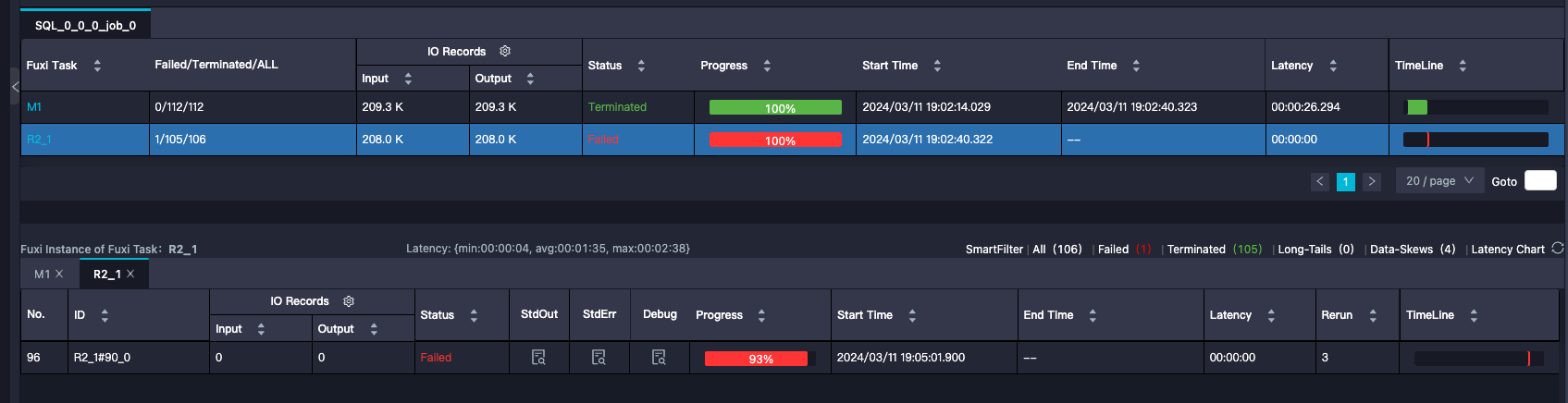
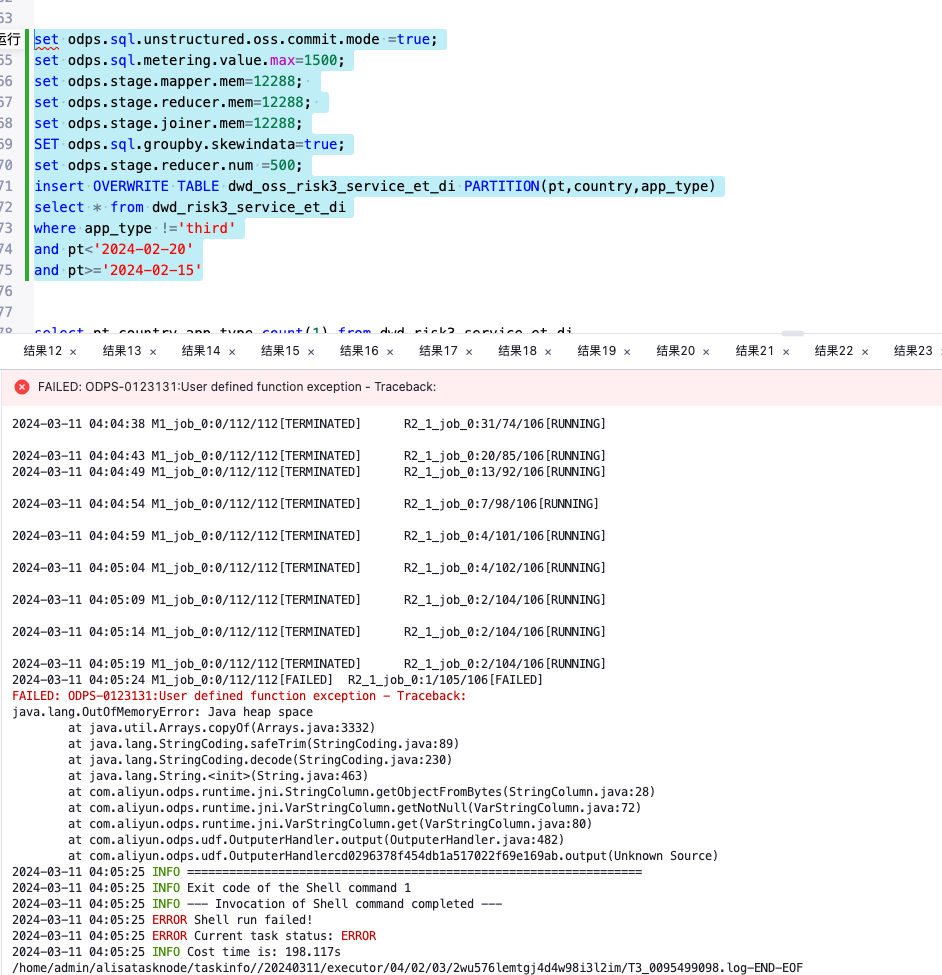
我可以设置jvm的内存大小吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在MaxCompute中,数据分区是通过指定的列(如pt, country, app_type)来划分数据的,而不是通过设置JVM内存大小来控制的。
关于数据倾斜的问题,即使表中的数据已经按照某些键(如pt, country, app_type)进行了分区,仍然有可能发生数据倾斜。这是因为除了分区键之外,其他非分区键的分布可能不均匀,导致某些分区包含的数据量远大于其他分区。这种情况下,即使使用了分区优化,查询时仍可能遇到数据倾斜问题。为了解决这个问题,可以考虑以下几种方法:
至于JVM内存大小的设置,这通常是指在执行MapReduce作业时可以配置的参数,而不是数据分区的一部分。在MaxCompute中,用户可以根据实际情况调整JVM内存大小以优化作业的执行效率。但是,这个设置与数据分区本身没有直接关系。
总之,在MaxCompute中,数据分区是用于优化查询性能和数据管理的工具,而不是用于控制JVM内存大小的。为了避免数据倾斜,需要合理设计分区策略,并在必要时采取适当的措施来处理。
在阿里云大数据计算服务MaxCompute(原名ODPS)中,数据分区是指对表进行逻辑上的划分,如您提到的pt,country,app_type,这些是分区键,用于根据不同的时间点、国家和应用类型对数据进行组织。但是,MaxCompute本身是一个分布式计算系统,其内存管理是在集群层面实现的,并不由用户直接设置单个JVM的内存大小。
MaxCompute会根据作业规模自动分配所需的计算资源,包括CPU、内存以及磁盘空间等。用户提交SQL作业时,可以通过控制台或API指定任务的并发度(即Task Slot数量),进而间接影响到分配给任务的总资源量。
如果您的问题是关于执行MapReduce或者Spark类型的自定义UDF(User Defined Function)程序时如何设置JVM内存,那么对于MaxCompute中的Java SDK或者其他支持的计算框架,在编写这类代码时确实可以设置运行环境的JVM参数,但这通常是在开发定制化组件或函数时通过对应的计算引擎配置来完成,而不是针对整个MaxCompute数据分区操作。例如,如果你使用了E-MapReduce进行计算,则可以在启动应用程序时设置相关JVM参数。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


