
请问千问1.5 72B AWQ的量化模型使用官方提供的代码运时,多个GPU无法并行使用,只是一个一个轮着运行。
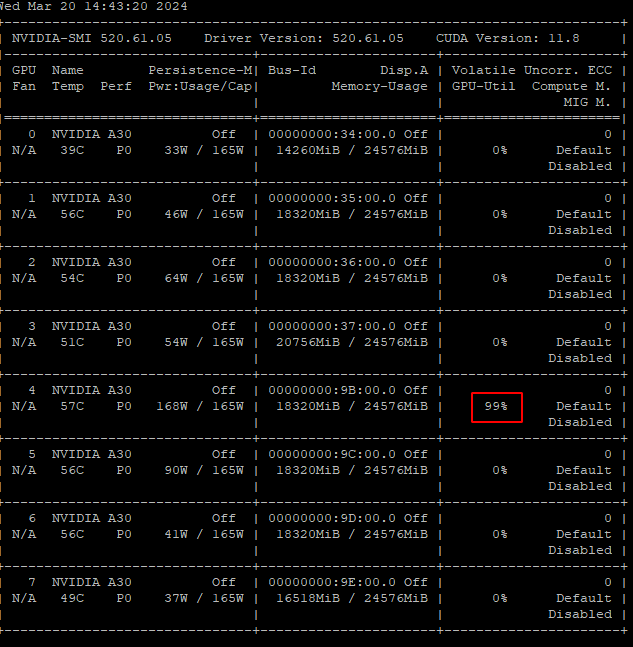
是什么问题造成的啊,代码和官方提供的代码一模一样。GPU为8个A30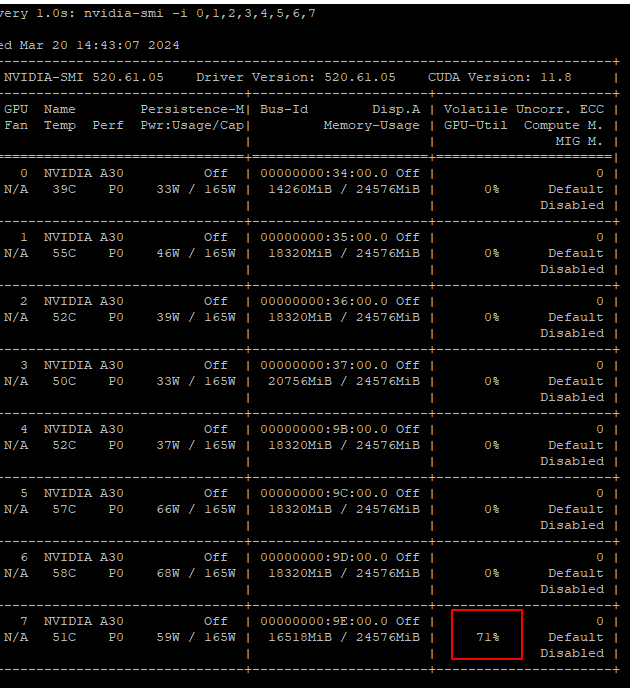
根据您描述的问题,千问1.5 72B AWQ量化模型在使用官方代码运行时,多个GPU无法并行使用,而是逐个轮换运行。这种情况可能由以下几个原因导致:
tensor parallelism(张量并行)和pipeline parallelism(流水线并行)等参数。如果这些参数未正确设置,模型可能默认以单卡模式运行,或者仅在一个GPU上完成计算后切换到下一个GPU。解决方法: - 检查是否正确设置了tp_size(张量并行的GPU数量)和pp_size(流水线并行的GPU数量)。例如,在运行脚本中添加以下参数: bash --tp_size 8 --pp_size 1 - 确保启动命令中包含正确的分布式训练标志,例如: bash deepspeed train.py --deepspeed_config ds_config.json
解决方法: - 确认是否已安装并启用了DeepNCCL或其他通信加速库。可以通过以下命令检查NCCL状态: bash nvidia-smi topo -m - 如果未启用DeepNCCL,请参考相关文档安装并配置。
解决方法: - 检查每块GPU的显存占用情况,确保显存分配均匀。可以使用以下命令监控显存: bash nvidia-smi - 如果显存不足,可以尝试减少batch size或调整量化精度(如从FP16降低到INT8)。
解决方法: - 检查代码中是否正确调用了多GPU并行的相关模块。例如,确认是否使用了torch.distributed或deepspeed的初始化函数: python import torch.distributed as dist dist.init_process_group(backend='nccl') - 如果使用的是官方提供的xxx_cli或deepgpu_cli脚本,确保传入了正确的-tp_size参数。例如: bash qwen_cli -model_dir /path/to/model -tp_size 8 -precision fp16
解决方法: - 使用nvidia-smi topo -m检查GPU之间的互联拓扑,确保它们通过NVLink或高带宽PCIe连接。 - 如果硬件拓扑限制较大,可以尝试减少模型的并行度(如将tp_size设置为4而非8)。
解决方法: - 确认是否已正确安装并启用DeepGPU加速器。可以通过以下命令检查: bash deepgpu-cli --version - 如果未启用,请参考相关文档进行配置。
根据上述分析,建议您按照以下步骤排查问题: 1. 检查分布式训练参数(如tp_size和pp_size)是否正确设置。 2. 确认通信库(如DeepNCCL)是否已安装并启用。 3. 监控显存占用情况,确保显存分配均匀且充足。 4. 检查代码逻辑,确保多GPU并行模块被正确调用。 5. 验证硬件拓扑,确保GPU之间具有高带宽互联。 6. 确认DeepGPU加速器是否已启用。
如果问题仍未解决,建议提供更详细的日志信息(如运行时的输出日志或错误信息),以便进一步定位问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
