
Flink CDC 里我的任务又全局挂了 flink设置的5次重试 akka timeout设置的2min 数据是mysql到cdc再sink到kafka 。 这个异常还出现 是说明mysql到cdc之间通信异常么?还是cdc 到下游kafka之间的subtask没搞完?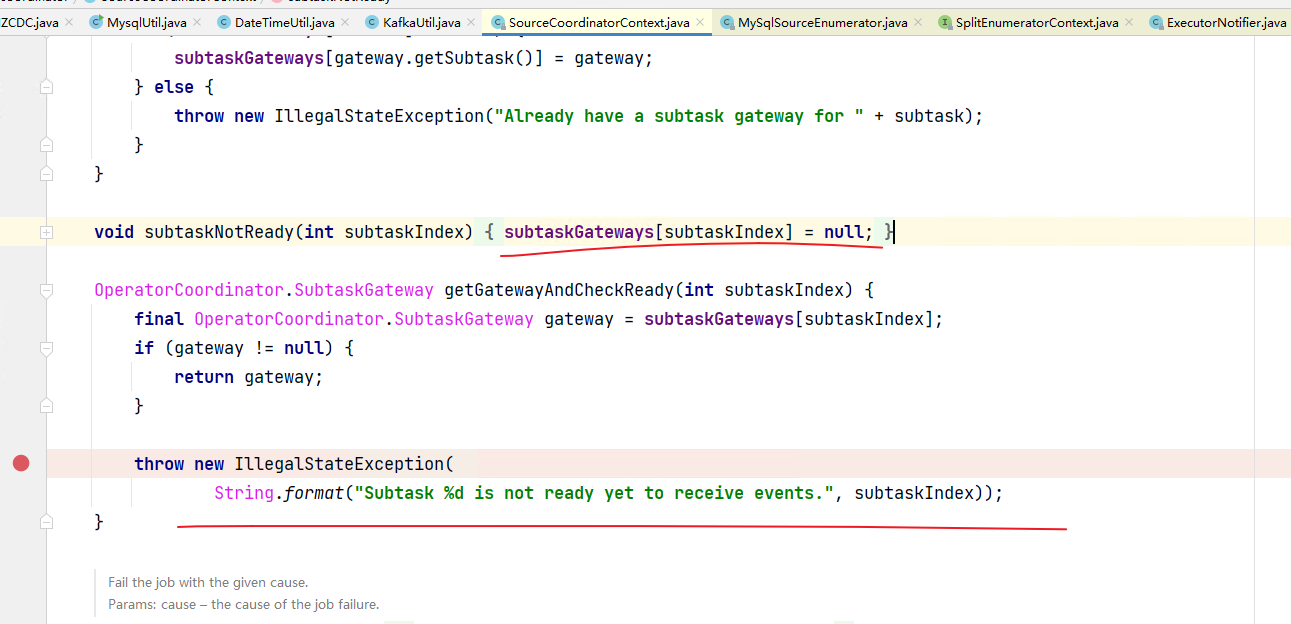
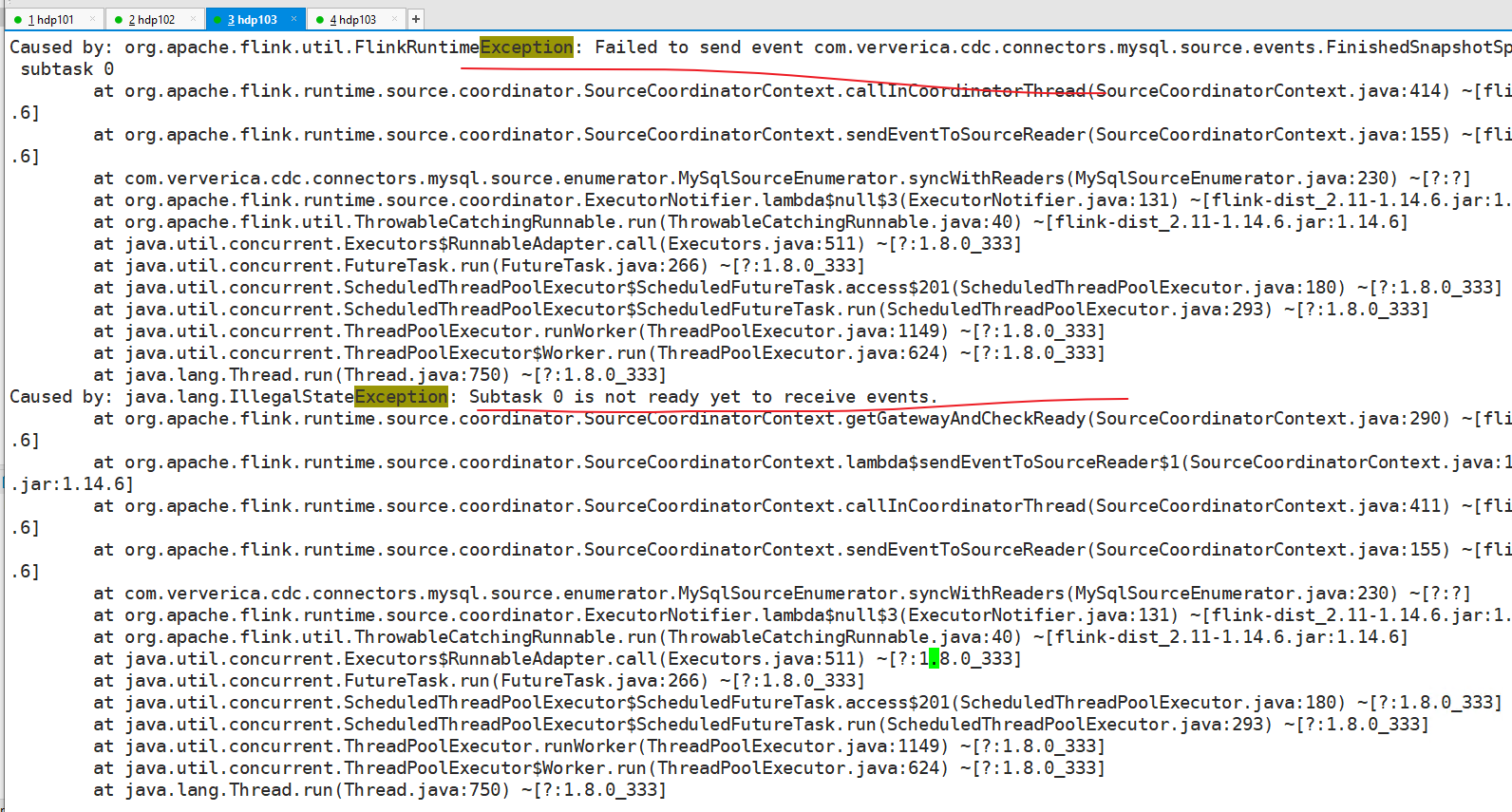 现在不知道根因是在哪里 ?或是参数配的还有问题?
现在不知道根因是在哪里 ?或是参数配的还有问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,Flink CDC任务全局挂起,并且出现了akka timeout异常。以下是针对问题的详细分析和解决建议:
akka.timeout异常可能是由于持续GC或作业规模较大导致的。如果MySQL的数据量较大,或者全量阶段并发读取时资源不足,可能会触发此类问题。timeout expired while fetching topic metadata)。connection-pool-xxx.mysql.rds.aliyuncs.com:3306 - Connection is not available)。akka timeout设置为2分钟,可能不足以应对大规模作业或高延迟场景。max_connections参数,确保其值足够大以支持Flink CDC的并发连接。server-id范围大于等于作业的并发数。zkCli.sh或zookeeper-shell.sh工具检查Kafka Broker的listener_security_protocol_map信息,确保Flink能够连通Kafka的Endpoint。client.timeout、akka.ask.timeout、client.heartbeat.timeout和heartbeat.timeout的值。例如:client.timeout=600s
akka.ask.timeout=600s
client.heartbeat.timeout=600000ms
heartbeat.timeout=600000ms
- 如果Kafka连接池已满,增加connection.pool.size的值(默认值为20)。
retryTimeout=3600000ms
retryInterval=5000ms
akka.ask.timeout和heartbeat.timeout设置为更大的值(如600秒)。INFO或DEBUG,以便捕获更多细节。例如:
<Logger level="INFO" name="org.apache.kafka"/>
<Logger level="INFO" name="org.apache.flink.runtime"/>
检查Flink作业的GC日志:
检查Kafka的消费端点信息:
endPoint配置正确,并且Flink能够解析Kafka的域名。验证MySQL CDC的启动模式:
initial模式进行全量读取,完成后切换至增量模式。监控任务的Subtask状态:
akka.timeout、heartbeat.timeout和Kafka的连接池大小。希望以上建议能帮助您快速定位并解决问题!
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

