
Flink CDC 里hiveserver2的内暂停时间过长是什么原因导致的?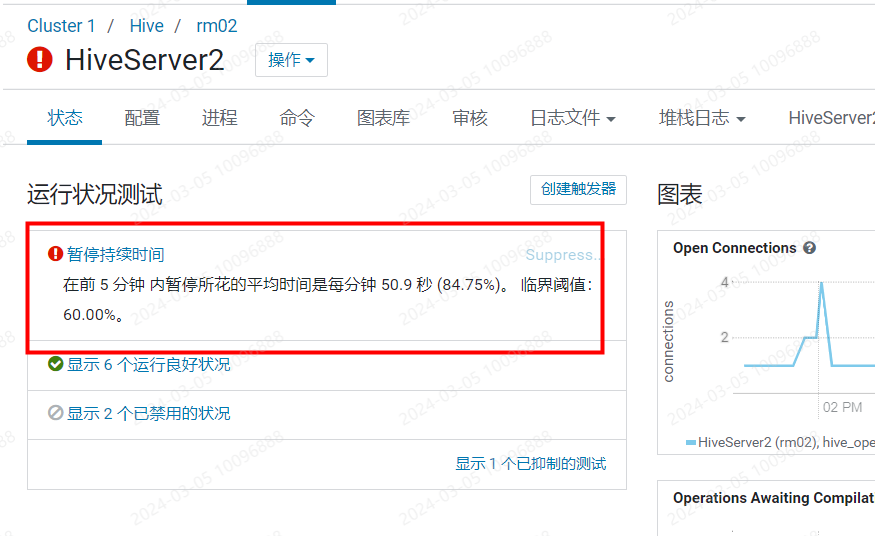
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC 中 HiveServer2 的内暂停时间过长,通常是由以下几个原因导致的。以下是详细的原因分析及对应的解决方案:
HiveServer2 在处理大量元数据操作或复杂查询时,可能会因内存不足而导致性能下降,进而引发内暂停时间过长的问题。
原因:
hive_server2_heapsize 参数值(500 MiB)可能不足以支持高负载场景。解决方案:
hive_server2_heapsizehive_server2_heapsize 参数。Flink CDC 和 HiveServer2 之间的网络延迟可能导致请求响应变慢,从而延长内暂停时间。
原因:
解决方案:
ping 或 traceroute)测试 Flink CDC 节点与 HiveServer2 节点之间的网络延迟。jobmanager.retrieve-taskmanager-hostname: false 来避免 DNS 延迟影响。HiveServer2 依赖 HiveMetaStore 进行元数据管理。如果 HiveMetaStore 出现性能问题,也会间接导致 HiveServer2 的内暂停时间延长。
原因:
max_connect_errors 参数设置过低,可能导致连接被阻塞。解决方案:
hive_metastore_heapsizemax_connect_errors 参数值,或执行 mysqladmin -u root -p flush-hosts 命令解除连接阻塞。Flink 作业的反压问题可能导致数据流处理延迟,从而影响 HiveServer2 的交互效率。
原因:
解决方案:
currentEmitEventTimeLag 和 currentFetchEventTimeLag 指标,分析是否存在拉取或处理延迟。如果 Hive 表的分区过多或小文件数量过多,可能导致元数据操作和数据写入效率降低。
原因:
解决方案:
/mnt/disk1/log/hive/ 目录下的 .log、.err 文件),定位具体错误信息。numRecordsIn 和 numRecordsOut 指标,确认数据流是否正常。Flink CDC 中 HiveServer2 的内暂停时间过长,通常由内存不足、网络延迟、HiveMetaStore 性能瓶颈、Flink 作业反压或表设计不合理等原因引起。通过调整内存参数、优化网络配置、解决反压问题以及改进表设计,可以有效缓解该问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

