
请问一下大数据计算MaxCompute这个是什么原因?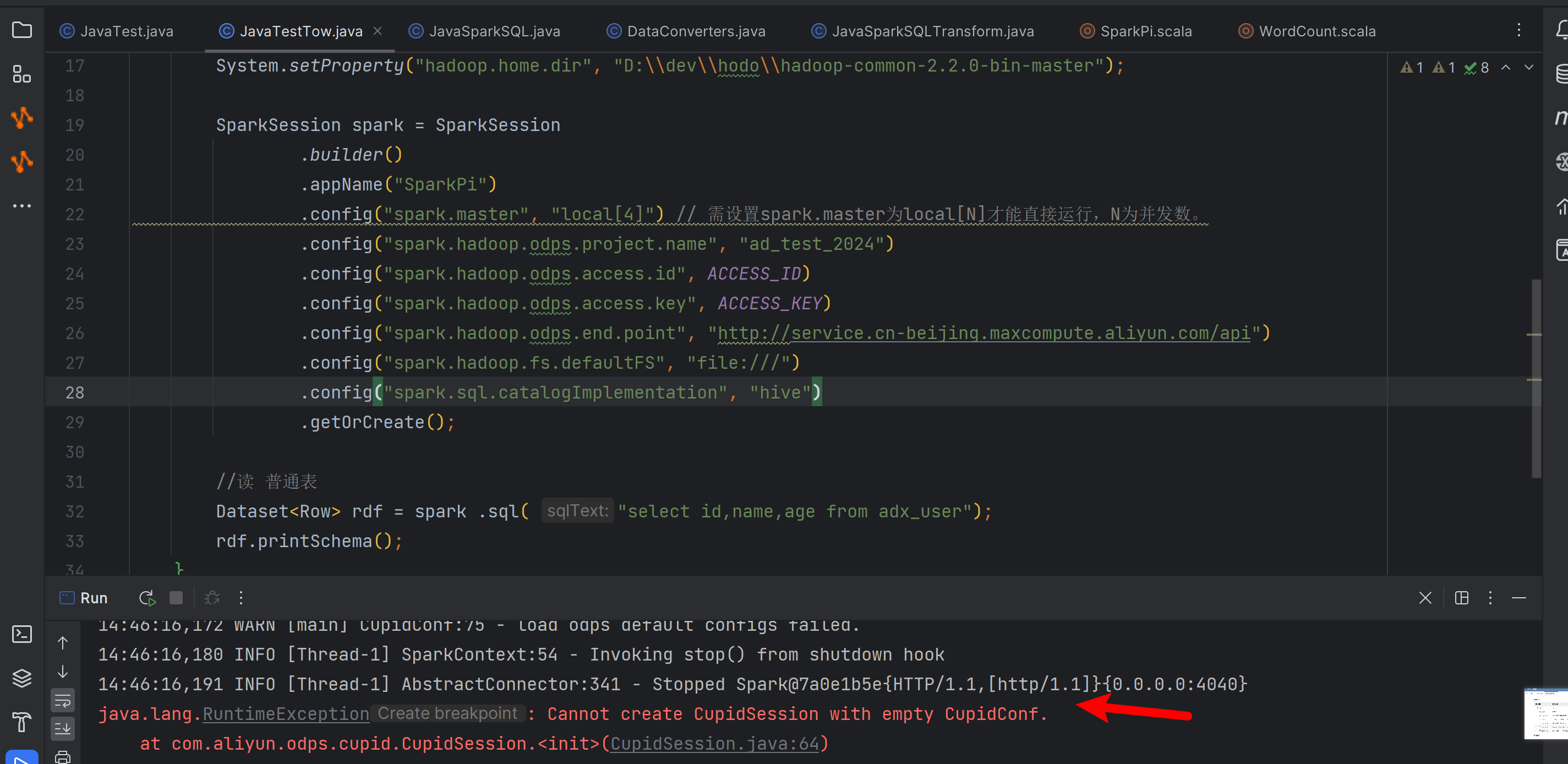
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您的问题提到“大数据计算MaxCompute这个是什么原因?”可能需要进一步明确具体场景或问题背景。不过,根据知识库中的参考资料,我可以从以下几个方面为您解析MaxCompute的相关信息和常见问题原因:
MaxCompute是阿里云提供的一种云原生大数据计算服务,适用于数据分析场景的企业级SaaS模式数据仓库。它以Serverless架构提供快速、全托管的在线数据仓库服务,能够处理TB、PB甚至EB级别的海量数据。
主要功能:
适用场景:
如果您遇到的问题与MaxCompute的功能或使用场景相关,请进一步说明具体需求。
在执行MaxCompute SQL时,可能会遇到Expression not in GROUP BY key的错误。这是由于SQL语句中SELECT查询的列未包含在GROUP BY子句中,或者未通过聚合函数(如SUM或COUNT)加工。
SELECT查询的列满足以下条件之一:
GROUP BY子句中。对于100亿条数据的GROUP BY分组查询,MaxCompute不会对性能产生显著影响,且对数据量无限制。但如果查询结果需要全排序(ORDER BY),可能会导致性能下降或内存溢出问题。
LIMIT限制返回结果数量。MaxCompute作业运行慢通常由以下原因导致: - 资源不足:集群资源分配不足,导致任务排队或执行缓慢。 - 模式回退:交互式查询作业未能命中查询加速模式,回退至普通模式运行。 - 代码逻辑问题:UDF(用户自定义函数)中存在死循环或处理时间过长的情况。
odps.function.timeout和odps.sql.executionengine.batch.rowcount)以适应实际计算需求。MaxCompute Tunnel服务在以下场景中可能出现请求延迟问题: - 共享Tunnel服务资源用满(CPU/网络带宽)。 - 客户端到Tunnel服务的网络链路不稳定。 - 客户端资源不足或代码逻辑不合理。
如果使用PyODPS时出现sourceIP is not in the white list错误,说明当前设备IP未添加至MaxCompute项目的白名单中。
to_global方法。如果您遇到的问题不属于上述范围,可能是以下原因导致: - 参数设置不一致:例如,PyODPS中设置的参数与客户端参数名称不一致(如odps.sql.mapper.split.size与odps.stage.mapper.split.size)。 - 数据存储与压缩问题:数据分散或未进行局部排序可能导致物理存储量增加。 - 攻击类请求:未遵守失败重试策略的请求可能被服务侧隔离处理。
根据知识库内容,MaxCompute的问题可能涉及SQL语法、作业性能、数据传输、IP白名单等多个方面。如果您能提供更多具体信息(如错误日志、操作场景等),我可以为您提供更精确的解决方案。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

