
以下延迟指标 都是flink 内部提供的相关指标,prometheusReporter 推送到pushgateway 的间隔是 60s , 具体配置如下:
prometheus 拉取间隔为 30s :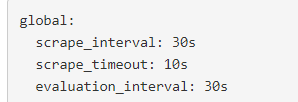
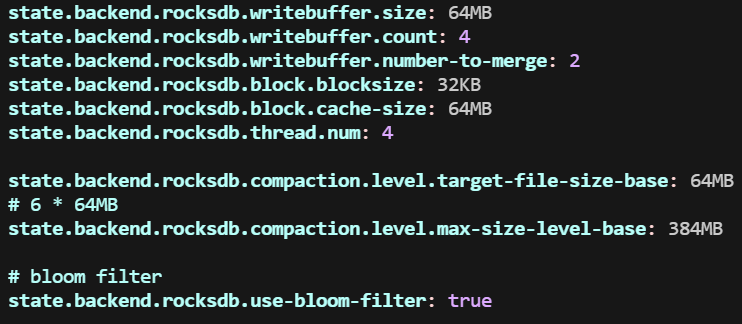
flink_taskmanager_job_latency_source_id_operator_id_operator_subtask_index_latency 指标用来检测端到端延迟,开启时的配置参数如下图:
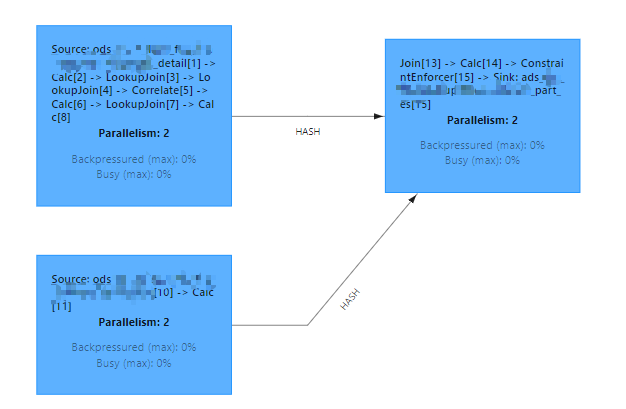
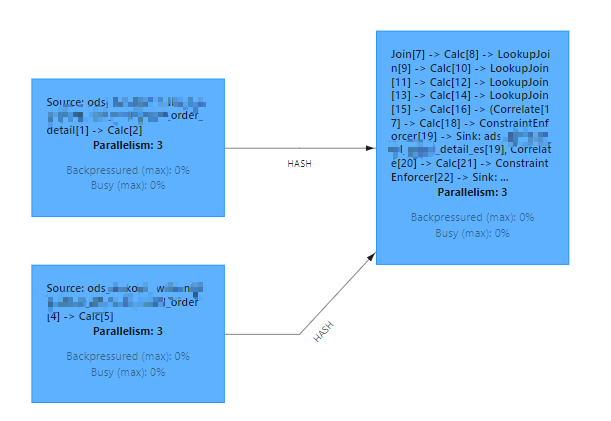
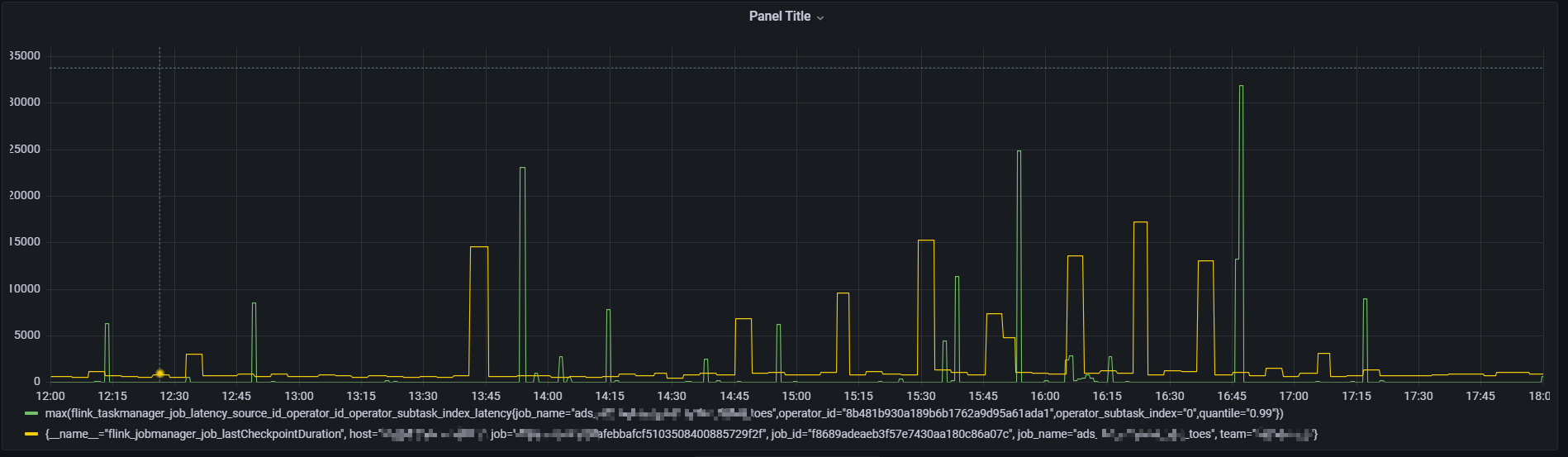
通过对比发现 flink 端到端延迟从 source 到 sink 端延迟 与 source 到 join 算子的 延迟 图形一致,基本可以确定是延迟增大就是 flinkSQL中regular join阶段引起的,以下是 flink 到 join 算子的延迟监控图: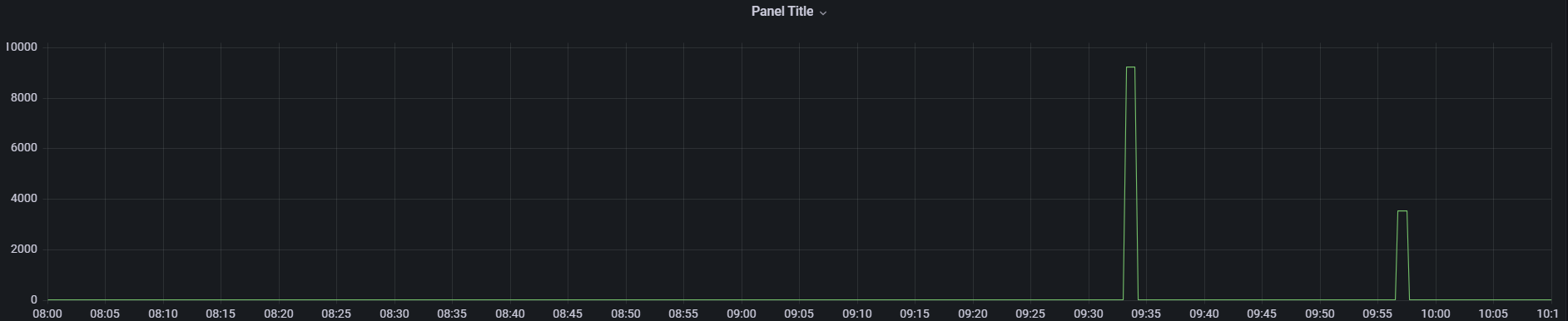

大部分时间延迟都是在一个较小的范围 100ms 以内
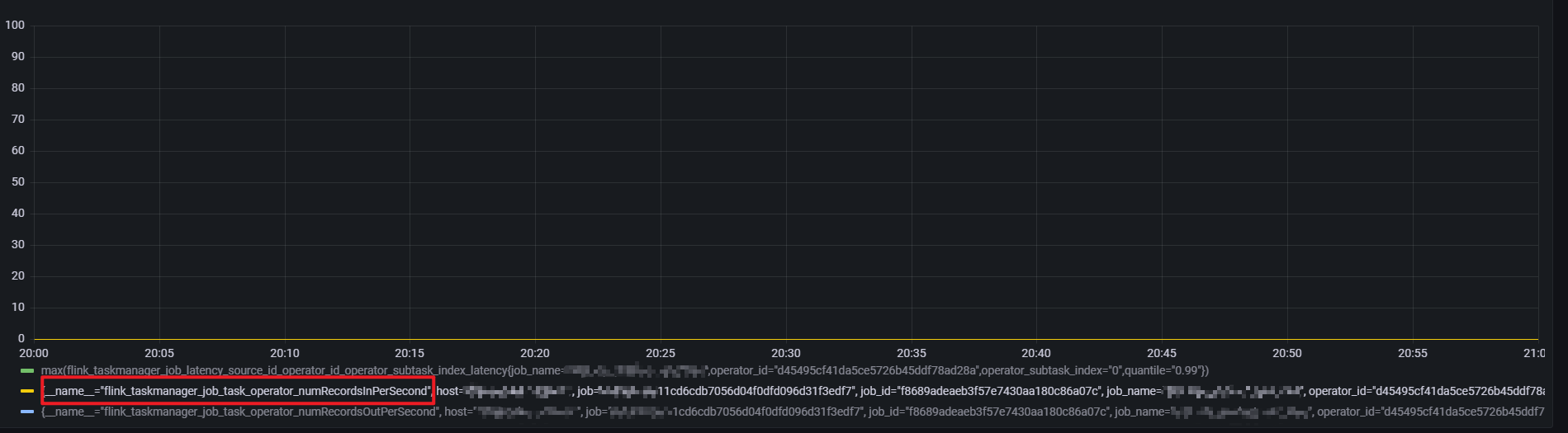
当前任务 join算子链的 flink_taskmanager_job_task_operator_numRecordsInPerSecond 指标,总体上在以下时间段在有数据的情况下每分钟 2-3 (0.033 * 60)条左右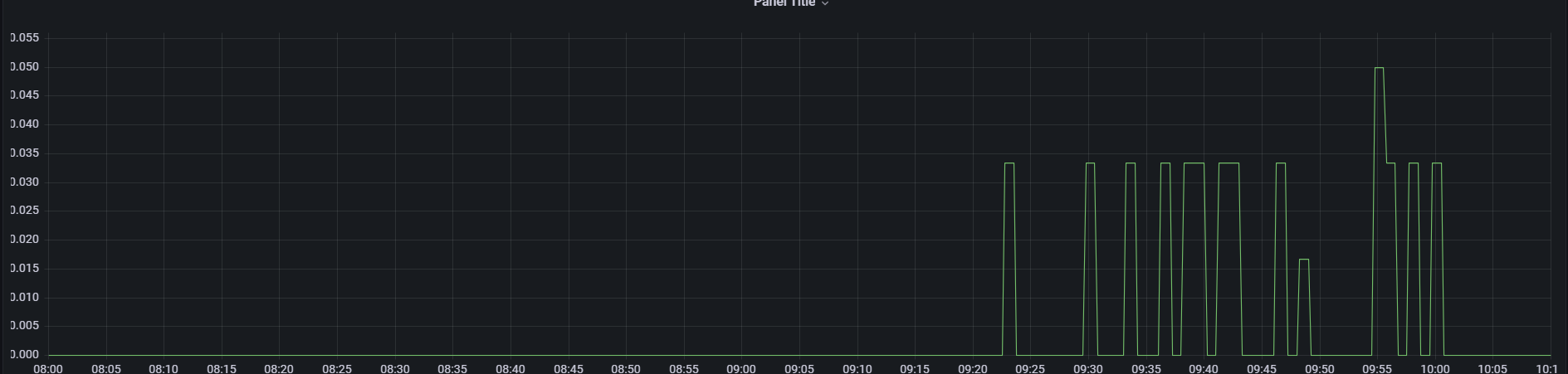
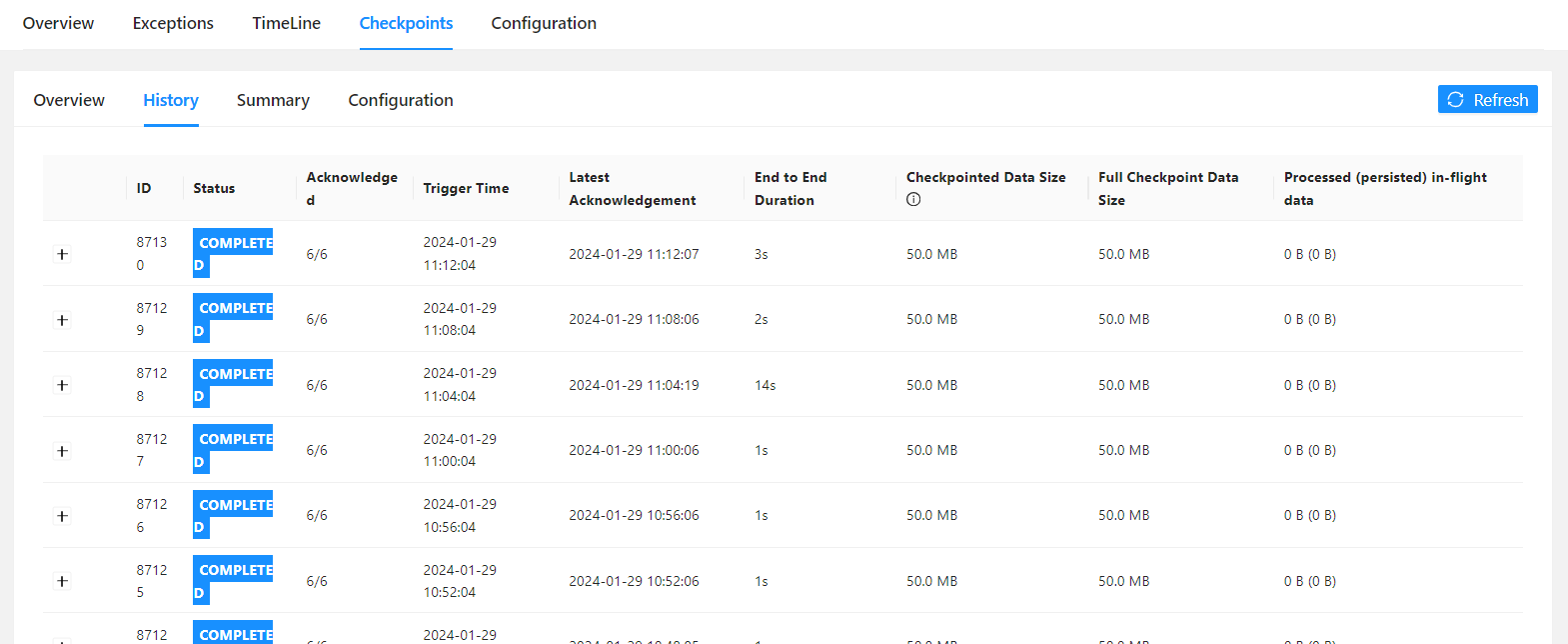
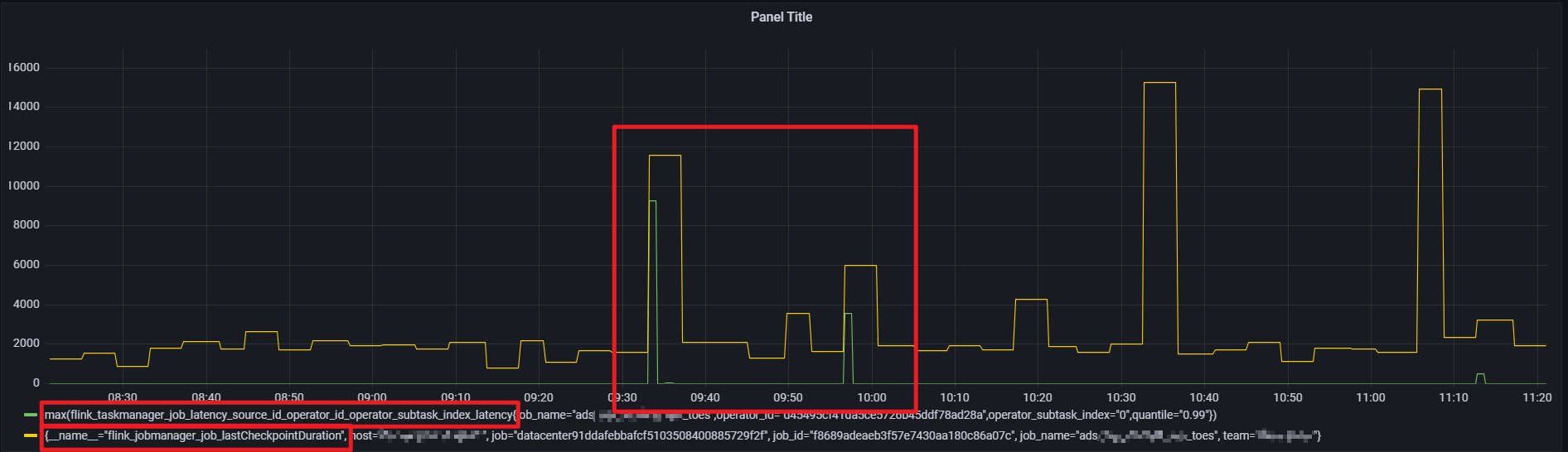
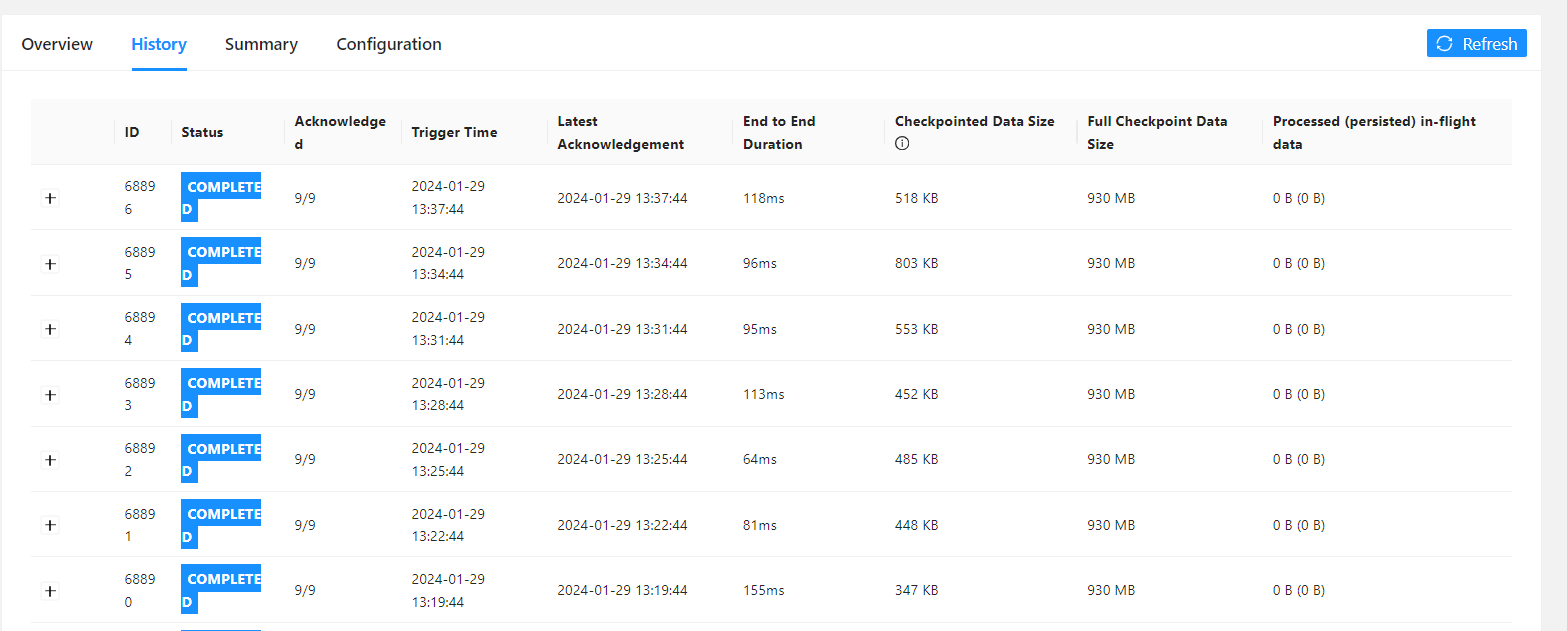
当前任务是全量checkpoint,对于全量做checkpoint ,通过对比发现当延迟增大的时候,一般 checkpoint 时长也会很大(增量checkpoint 现象不明显)
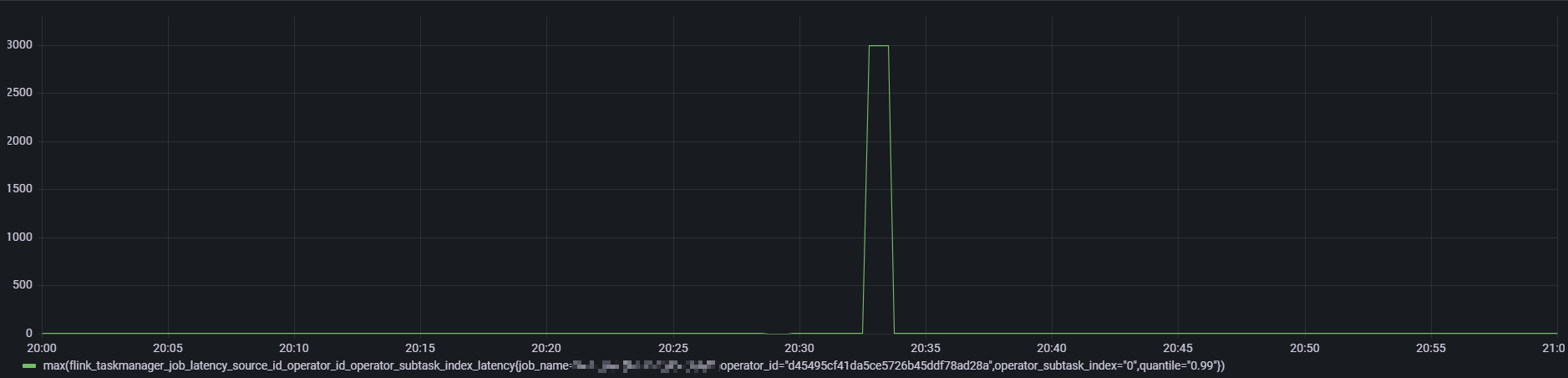
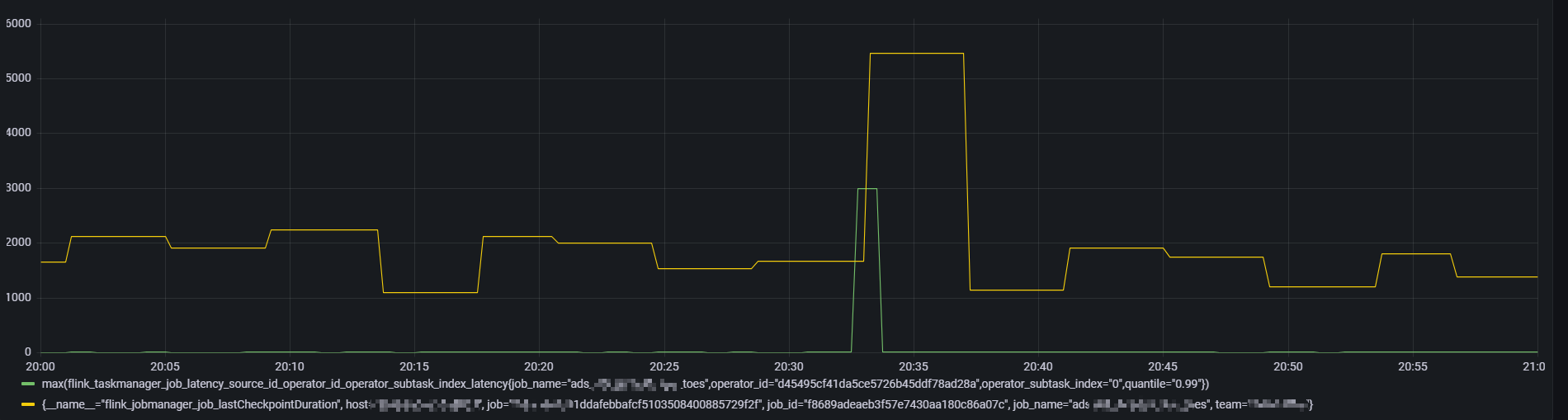

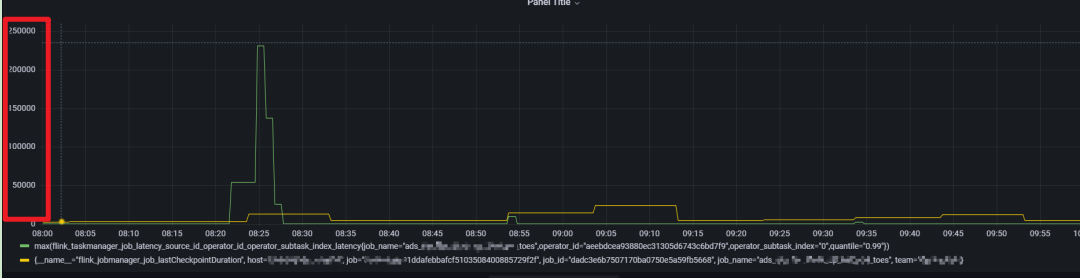
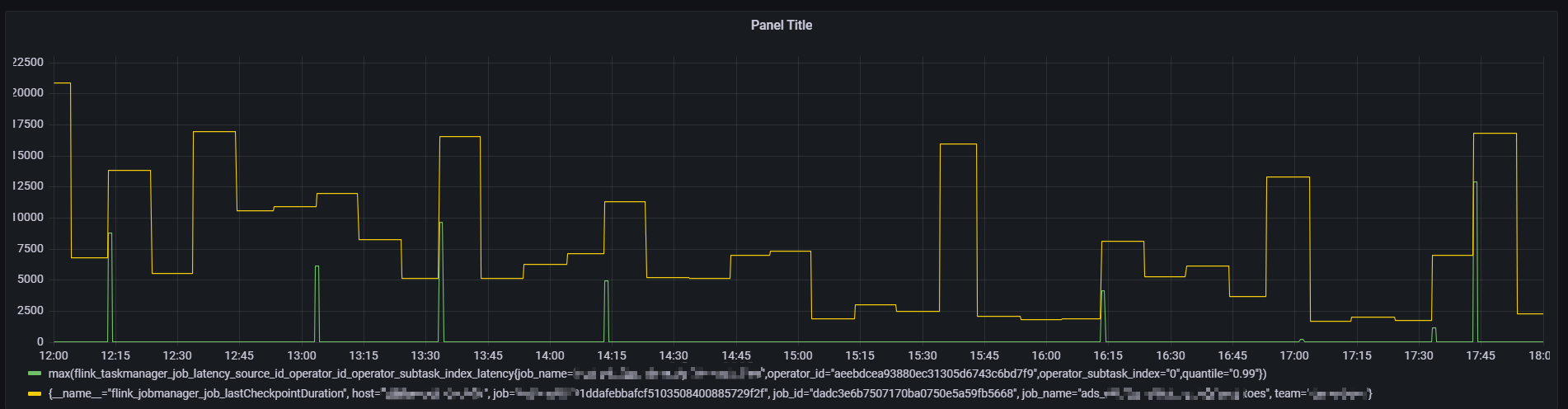
延迟突刺达到 12s ,持续直到下一条数据到来 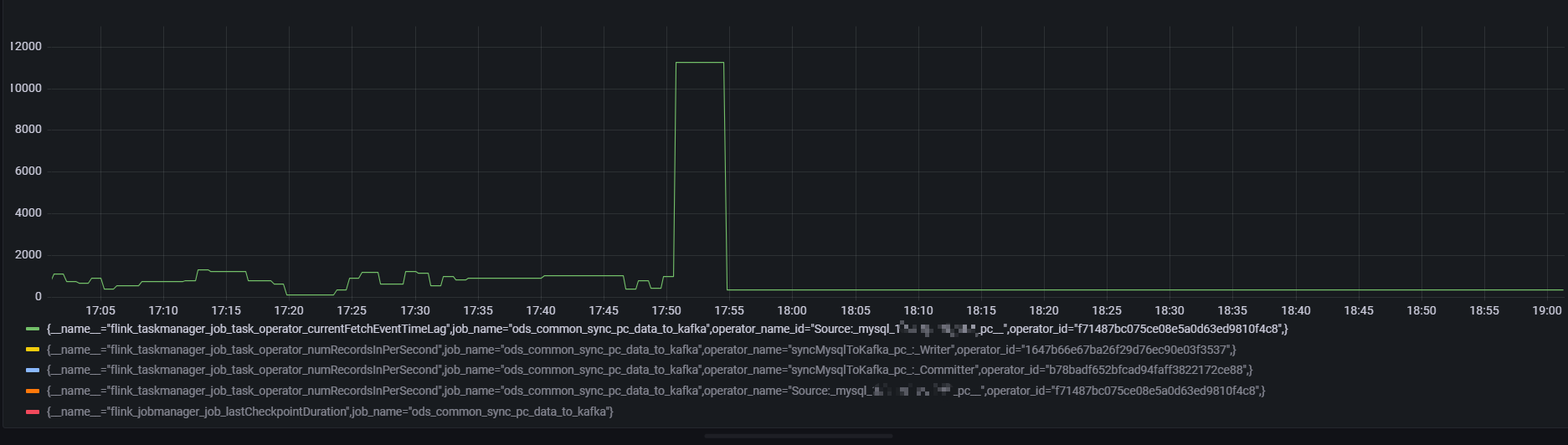
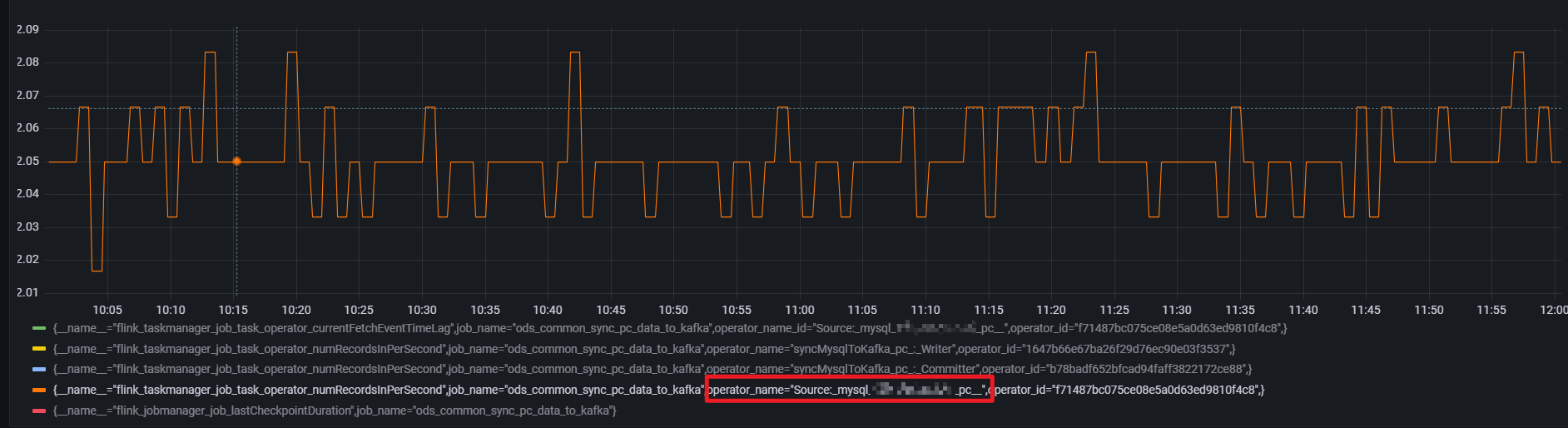
Source的数据的输入是较为稳定的大概是 2.0 * 60s = 120 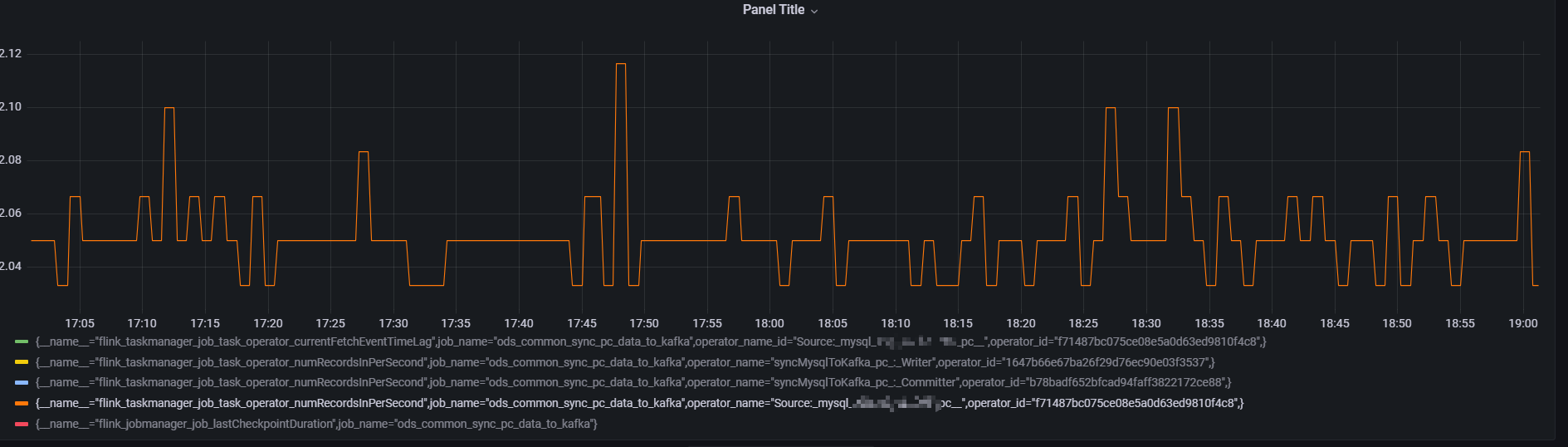
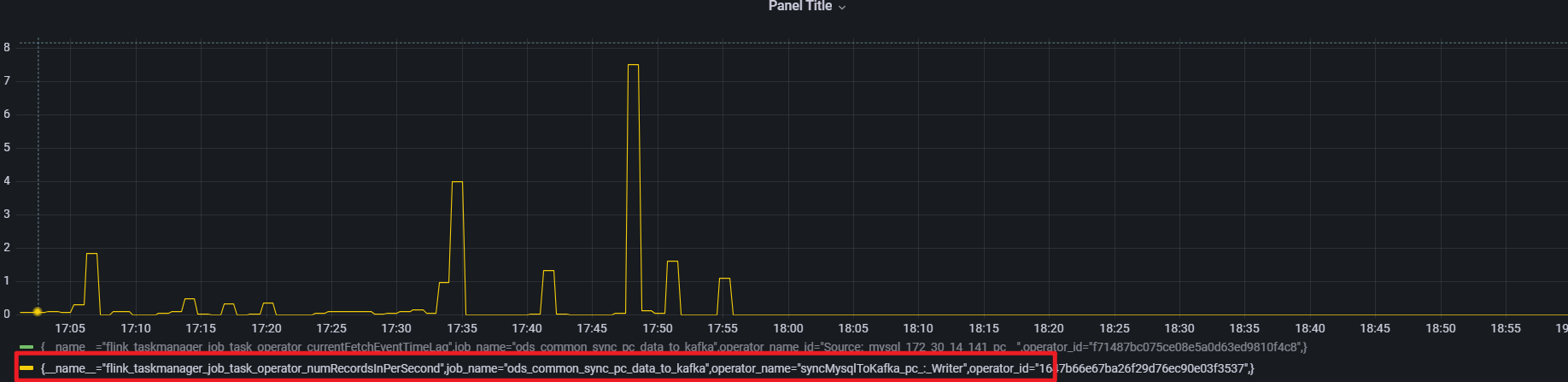
通过source 算子的numRecordsInPerSecond 指标发现存在数据输入,但是延迟指标却一直保持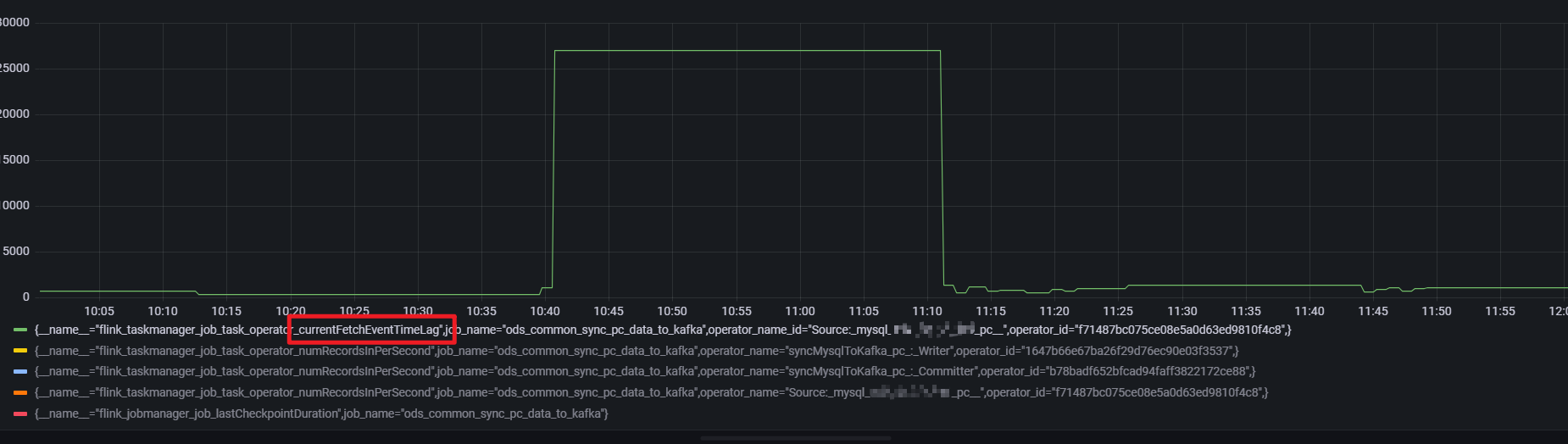
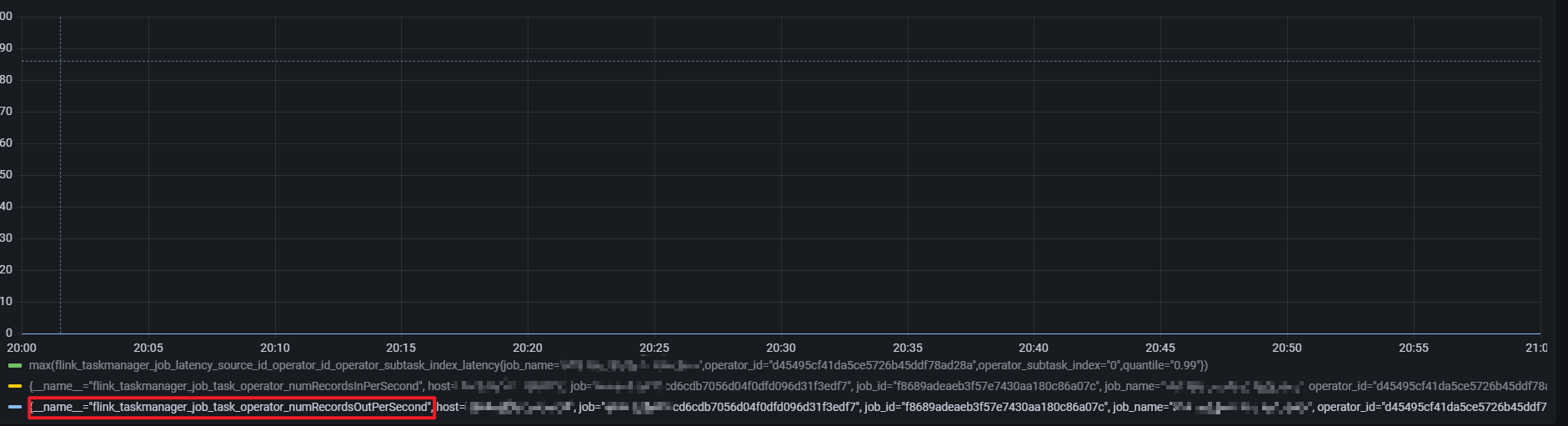
而 writer 算子的numRecordsInPerSecond 指标则可以解释(所以这是为什么,是被过滤了吗,还是flinkcdc 心跳也算作 source 的输入吗)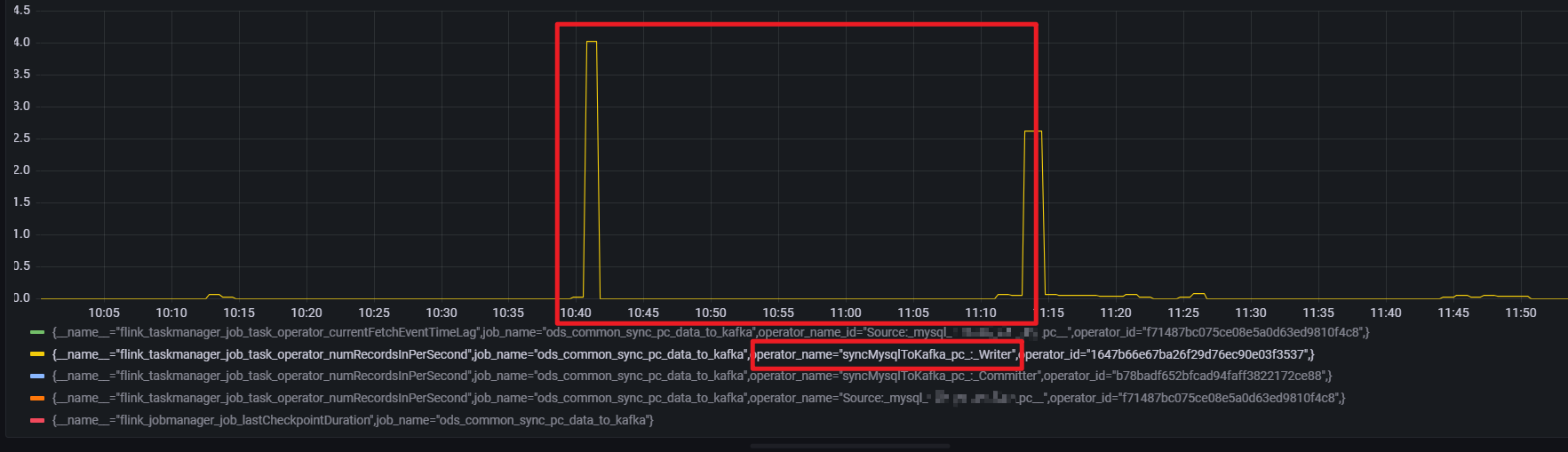
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

