
Flink CDC里 同步 PG的数据,为了获取 delete/update 操作,需要 [ALTER TABLE reptest REPLICA IDENTITY FULL;] ,业务库需要所有表都同步的话,会对线上业务库性能影响很大么? 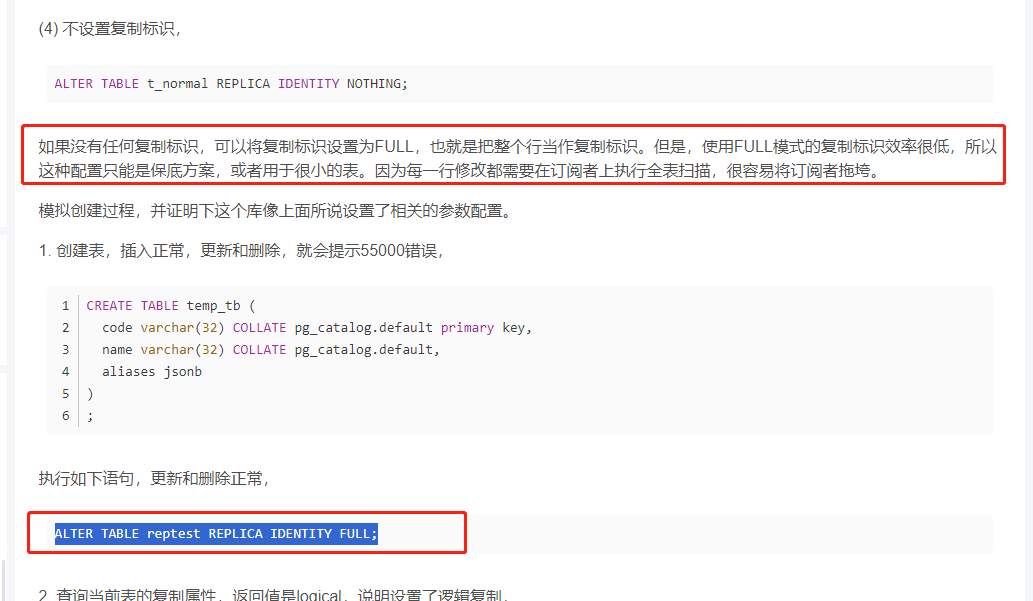
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC同步PostgreSQL(PG)数据时,为了获取DELETE和UPDATE操作的完整变更信息,确实需要对表执行ALTER TABLE reptest REPLICA IDENTITY FULL;命令。这一操作会将表的REPLICA IDENTITY设置为FULL,从而确保逻辑解码插件能够捕获到所有列的旧值。然而,这种配置可能会对线上业务库的性能产生一定影响,具体影响程度取决于以下几个因素:
REPLICA IDENTITY FULL的影响REPLICA IDENTITY设置为FULL时,PostgreSQL会在WAL(Write-Ahead Logging)中记录每一行的所有列的旧值。这会增加WAL日志的大小和写入量,进而对数据库的写入性能造成压力。REPLICA IDENTITY FULL会导致逻辑解码过程中需要处理更多的数据,可能增加复制延迟。如果业务库中的所有表都需要同步,并且都设置了REPLICA IDENTITY FULL,则上述影响会被放大: - 全局性能压力:所有表的UPDATE和DELETE操作都会生成额外的WAL日志,可能导致整体数据库性能下降。 - 高并发场景下的瓶颈:在高并发写入或更新的场景下,WAL日志的生成和处理可能成为性能瓶颈,影响线上业务的响应时间。 - 磁盘空间管理复杂性:随着WAL日志的增长,需要更频繁地清理和归档日志文件,否则可能导致磁盘空间不足。
为了避免对线上业务库性能造成过大影响,可以采取以下优化措施: 1. 仅对必要表启用REPLICA IDENTITY FULL
如果并非所有表都需要捕获完整的DELETE和UPDATE操作,可以选择性地对关键表启用REPLICA IDENTITY FULL,而非全局应用。
调整WAL相关参数
max_wal_size和min_wal_size参数值,以减少WAL日志切换频率,降低性能波动。wal_level设置为logical,并根据实际需求调整max_replication_slots和max_wal_senders参数,以支持更多的逻辑复制槽和并发连接。定期清理Replication Slot
未及时清理的Replication Slot可能导致WAL日志堆积,占用大量磁盘空间。建议定期检查并清理不再使用的Slot。
评估业务负载
在实施全库同步前,建议对业务库的负载进行评估,尤其是高频更新和删除操作的表。可以通过监控工具(如pg_stat_activity、pg_stat_database)分析WAL日志生成量和数据库性能变化。
分阶段实施同步
如果业务允许,可以分阶段对表进行同步,优先同步关键表,逐步扩展到其他表,以降低一次性全库同步带来的性能冲击。
启用REPLICA IDENTITY FULL是获取完整变更数据的必要条件,但会对数据库性能和存储带来额外开销。对于全库同步的场景,建议根据业务需求选择性地启用该配置,并结合上述优化措施,尽量减少对线上业务的影响。如果业务库对性能要求极高,可以考虑在非高峰期执行同步任务,或者通过影子库等方式隔离同步操作对主库的影响。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

