
在大数据计算MaxCompute中,这个意思是说to_pandas方法绝对不能用吗?还是说下载数据的操作通常具备使用to_pandas方法的特征,但调用to_pandas方法的不一定都是下载数据? 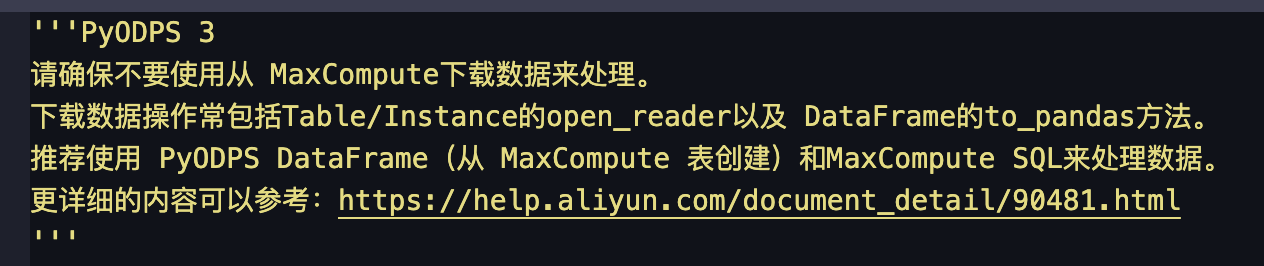
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在大数据计算MaxCompute中,并不是绝对不能使用to_pandas方法,而是在特定情况下推荐使用或避免使用。
首先,to_pandas方法的主要用途是将MaxCompute中的DataFrame对象转换为Pandas DataFrame对象,以便在本地进行更加灵活的数据操作和分析。这个方法在数据量较小、适合在单机环境下处理时非常有用。例如,如果你需要对查询结果进行进一步的数据分析或者可视化,那么使用to_pandas方法将数据下载到本地并转换为Pandas DataFrame是一个很好的选择。
其次,如果数据量较大或者网络带宽有限,直接使用to_pandas方法可能会导致下载数据变得非常缓慢,甚至无法完成。在这种情况下,推荐使用PyODPS提供的DataFrame API来进行数据操作,这样可以利用MaxCompute的强大计算能力来处理大量数据,而无需将所有数据下载到本地。
最后,需要注意的是,to_pandas方法返回的Pandas DataFrame与直接通过Pandas创建的DataFrame在功能上没有任何区别,数据的存储和计算均在本地。这意味着,如果你在本地有足够资源处理数据,使用to_pandas方法是可行的。
总的来说,是否使用to_pandas方法取决于具体的数据处理需求和环境条件。在数据量较小或者需要进行本地分析的情况下,可以使用to_pandas方法;而在数据量大或者网络条件受限的情况下,应该考虑使用PyODPS的DataFrame API来充分利用MaxCompute的计算能力。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


