
文字识别OCR里body_stream = StreamClient.read_from_bytes(data)
recognize_multi_language_request = ocr_api_20210707_models.RecognizeMultiLanguageRequest(
body=body_stream,
# Array, 必填, * 支持语言列表。,
languages=[
'rus'
]
)
,SDK里面读取图像的方式我换成read_from_bytes 一直返回code: 400, The image URL or body is empty. request id: C3721C78-98AC-5D01-A000-BCDF48A93890 传进去的bytes是有数据的。现在我这边的业务是不会生成文件的 只有bytes 要么np数组,
传进去的bytes是有数据的。现在我这边的业务是不会生成文件的 只有bytes 要么np数组,
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您好,这里看了一下文字识别OCR官方提供的示例代码,通过body上传图片二进制文件进行文字识别,示例代码如下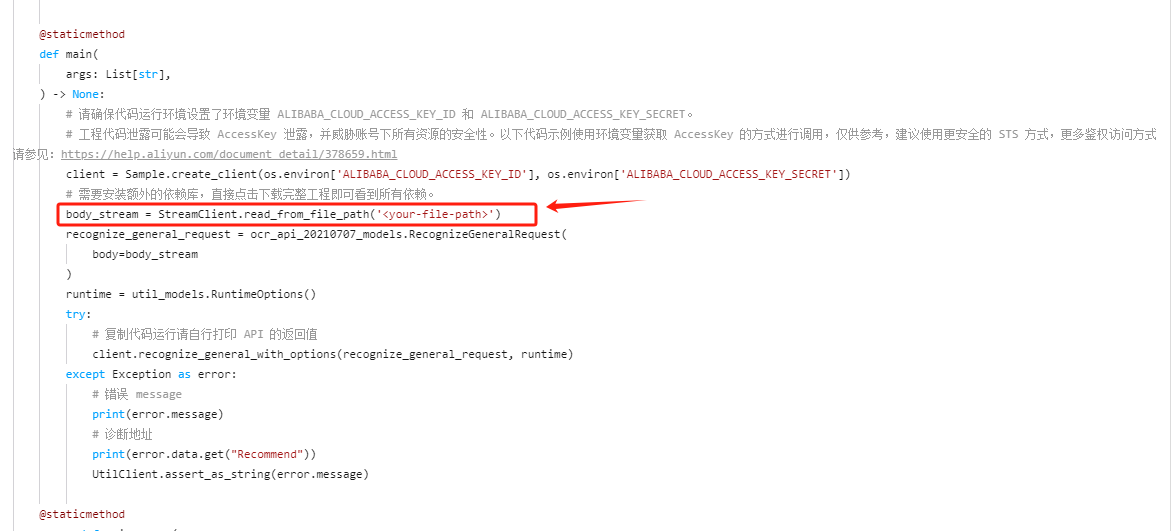
其中 body_stream = StreamClient.read_from_file_path('') 是为了从指定文件路径读取图片二进制文件,如果您传进去的就是bytes的话,那么您可以尝试直接将您的bytes赋值给body_stream,类似这样
body_stream = your_bytes
recognize_general_request = ocr_api_20210707_models.RecognizeGeneralRequest(
body=body_stream
)
如果在使用文字识别OCR时,传入文件不响应,可以尝试以下方法解决:
检查文件路径和文件名是否正确。确保文件存在于指定的路径下,并且文件名没有错误。
检查文件大小是否超过限制。有些API对上传的文件大小有限制,如果文件过大,可能会导致上传失败或响应超时。可以尝试将大文件分割成多个较小的文件进行上传。
检查网络连接是否正常。确保您的计算机可以正常访问互联网,并且网络连接稳定。
使用其他文件格式。如果您的文件是二进制格式(如图片),可以尝试将其转换为文本格式(如PDF、TXT等),然后再进行上传和识别。
联系技术支持。如果以上方法都无法解决问题,建议您联系阿里云技术支持寻求帮助。他们可以为您提供更专业的指导和解决方案。


 此回答来自钉群【官方】阿里云OCR公共云客户交流群。
此回答来自钉群【官方】阿里云OCR公共云客户交流群。