
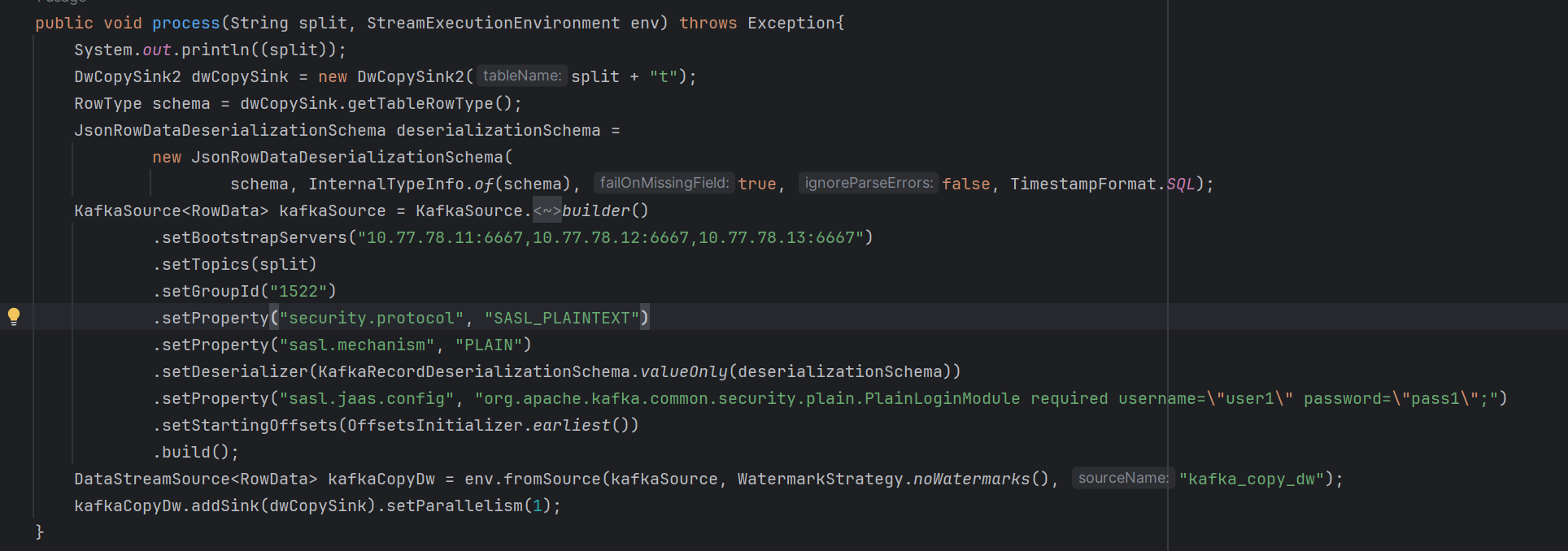
一个主题对应一张表,现在表个数不固定,想通传参的方式传入程序。目前是初始化env后循环初始化source然后处理完再sink,最后execute。问题是循环中只有第一个主题的数据能读出来然后写出去,后面的都写不进去怎么解决。
如何能循环source和sink能同时去执行。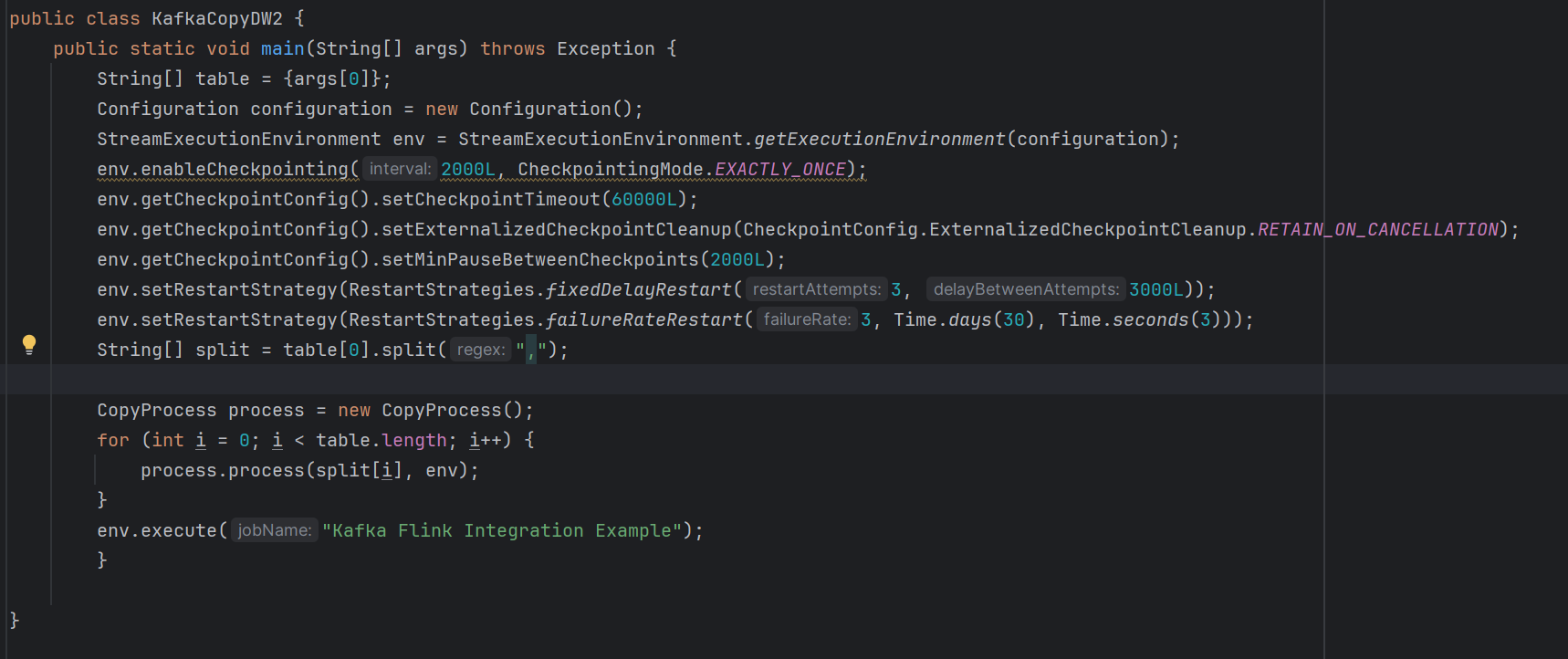
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Apache Flink 的 DataStream API 允许动态创建和注册源(Source)和接收器(Sink),但你所描述的问题可能是由于程序执行逻辑和并行性设置导致的。在你的场景下,一次性执行循环中的所有任务不是一个有效的做法,因为Flink作业一旦开始执行,其数据流图就会被固定下来。
为了实现动态读取不同主题并将数据写入不同的表,你可以考虑以下解决方案:
使用RuntimeContext: 在Flink作业的任务中,可以通过getRuntimeContext()获取运行时上下文,然后结合广播变量或者累加器来传递主题列表并在算子内部动态切换消费的主题。
动态表源和Sink: 使用Flink 1.10及以上版本提供的Table API和SQL,可以结合Catalog系统动态注册表,但这仍然需要在JobClient端预先知道所有的表信息,并且整体提交一次作业。
多个独立作业: 可以考虑启动多个独立的Flink作业,每个作业对应一个主题到表的处理逻辑,通过外部调度系统(如Airflow, Azkaban, 或者自定义脚本)按需启动和管理这些作业。
自定义Source: 自定义一个Source,使其能够从外部存储(比如数据库、配置中心等)拉取主题列表,并根据列表内容动态订阅Kafka主题。不过要注意并发问题,确保各个主题的消费是并发进行的。
下面是一个简化的示例,展示如何在同一个DataStream作业中处理多个主题(使用Kafka作为Source):
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
List<String> topics = ... // 获取主题列表
topics.forEach(topic -> {
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), kafkaConfig);
DataStream<String> streamForTopic = env.addSource(kafkaSource);
// 对每个主题的数据流进行处理
DataStream<YourType> processedStream = streamForTopic.map(...);
// 动态确定表的名称,这里只是一个示例
String tableName = "table_for_" + topic;
// 假设有一个动态创建并注册表的方法
createAndRegisterTable(tableName);
// 将处理后的数据写入对应的表
TableResult result = processedStream.executeInsert("catalogName.dbName." + tableName);
});
env.execute("Dynamic Topic Processing Job");
这个示例仅供参考,实际上在单个Flink作业中循环添加多个Source并执行可能会遇到并发问题,因为在execute之前必须构建完整的执行图。因此,更推荐采用第3或第4种方案。
你可以尝试使用多线程或异步的方式来解决这个问题。在循环中,为每个主题创建一个单独的线程或任务,这样它们就可以同时执行了。以下是一个使用Python的示例:
import threading
def process_topic(topic):
# 初始化source
source = initialize_source(topic)
# 处理数据
processed_data = process_data(source)
# 初始化sink
sink = initialize_sink(topic)
# 写入数据
write_data(sink, processed_data)
# 获取所有主题
topics = get_all_topics()
# 为每个主题创建一个线程
threads = []
for topic in topics:
t = threading.Thread(target=process_topic, args=(topic,))
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
这个示例中,我们首先定义了一个process_topic函数,它负责处理单个主题的数据。然后,我们获取所有主题,并为每个主题创建一个线程。最后,我们等待所有线程完成。
注意:这个示例仅适用于Python,如果你使用的是其他编程语言,你需要根据该语言的特性进行调整。
你可以尝试使用多线程或异步的方式来解决这个问题。在循环中,为每个主题创建一个单独的线程或任务,这样它们就可以同时执行了。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


