dataworks数据同步的时候是全量更新还是增量更新,还是都支持?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
DataWorks数据同步功能支持全量更新和增量更新两种方式,根据实际业务需求,可以选择合适的同步类型来保证数据的一致性和时效性。
全量更新指的是一次性同步所有数据到目标表或分区中,适合初始数据加载或者定期刷新数据的场景。在全量同步过程中,会将源头表的全部数据导出并导入到目标表中,覆盖任何现有的数据。这种方式简单直接,但可能会造成较大的数据量传输和存储压力。
增量更新则是指只同步自上次同步以来发生的数据变动。这通常包括新插入的数据、更新后的数据或是删除的数据。通过配置增量同步任务,可以设置数据过滤条件,比如根据时间戳或其他标识来识别新增或变更的数据,从而实现更高效的数据同步。增量同步能显著减少数据传输量,节省资源,并确保只有变化的数据被同步,适用于数据频繁变动且需要及时反映这些变动的场景。
在使用DataWorks进行数据同步时,可以根据数据表的特征和业务需求,选择合适的同步类型。例如,对于日志数据等不会频繁更新的数据,可以采用全量同步;而对于人员表、订单表等会持续发生变动的数据,则可以每天进行增量同步,以便获取历史数据和当前数据的全貌。此外,DataWorks还提供了调度参数和增量字段的配置,使得增量同步任务能够根据业务时间的动态变化来自动调整数据过滤条件,进一步提高数据同步的灵活性和准确性。
DataWorks数据同步支持全量更新和增量更新两种方式,具体选择哪种方式取决于实际需求和场景。
全量更新:全量更新是将整个数据表或数据集一次性同步到目标端。这种方式比较简单直接,但是如果数据量很大,可能会对目标端的存储和计算造成较大压力。全量更新适用于初次同步数据或数据量较小的情况。
增量更新:增量更新只同步新增或变更的数据,这种方式可以减少数据传输量和存储压力,提高同步效率。但是,增量更新需要保证源端和目标端的数据一致性和完整性,实现起来相对复杂,需要处理好数据冲突和版本控制等问题。
在DataWorks中,可以根据实际需求选择全量更新或增量更新的方式。如果数据量较大,建议采用增量更新的方式,以提高同步效率;如果数据量较小或初次同步数据,可以选择全量更新方式。
另外,DataWorks还提供了数据合并、去重、冲突解决等功能,以帮助用户更好地实现数据同步和管理。如果数据量非常大且需要实时同步,建议使用DataWorks提供的实时流处理功能,该功能可以实时捕获数据变更并同步到目标端。
总之,DataWorks数据同步支持全量更新和增量更新两种方式,具体选择哪种方式需要根据实际需求和场景来决定。
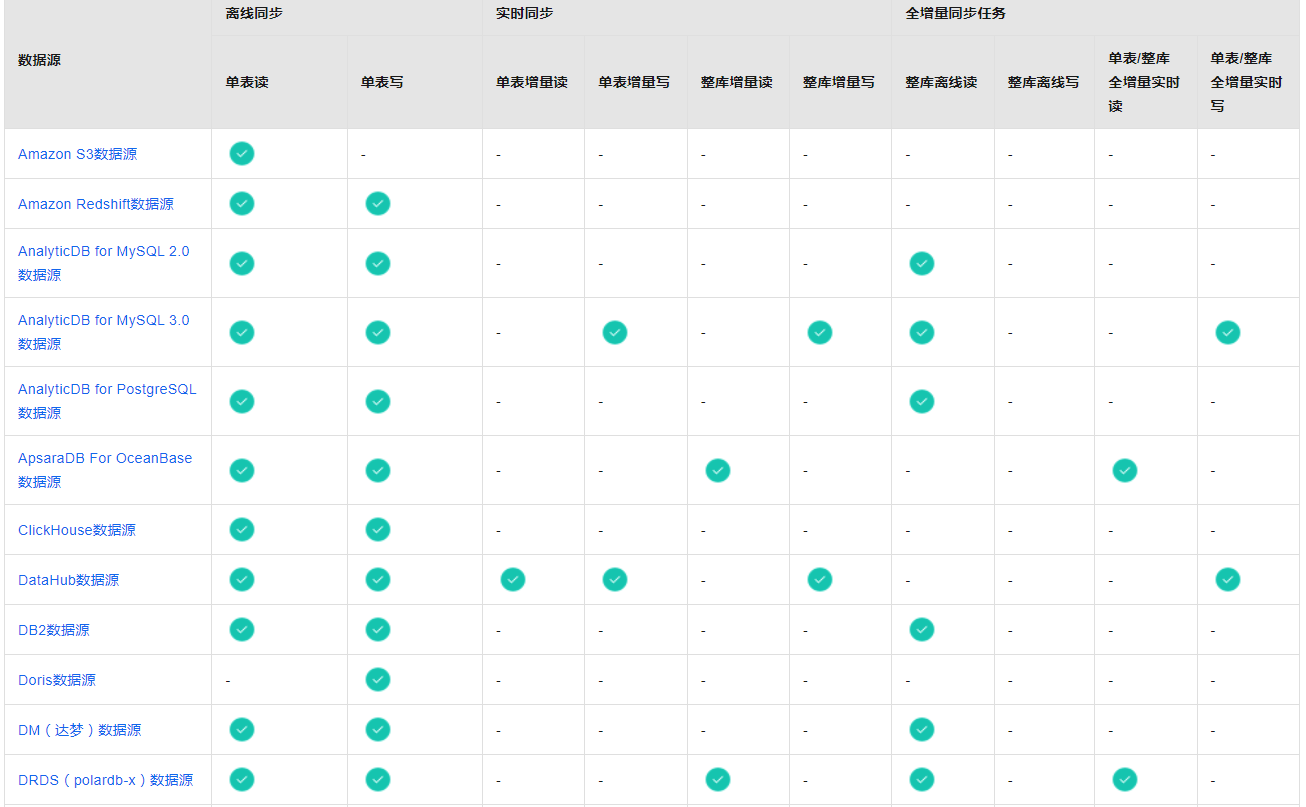
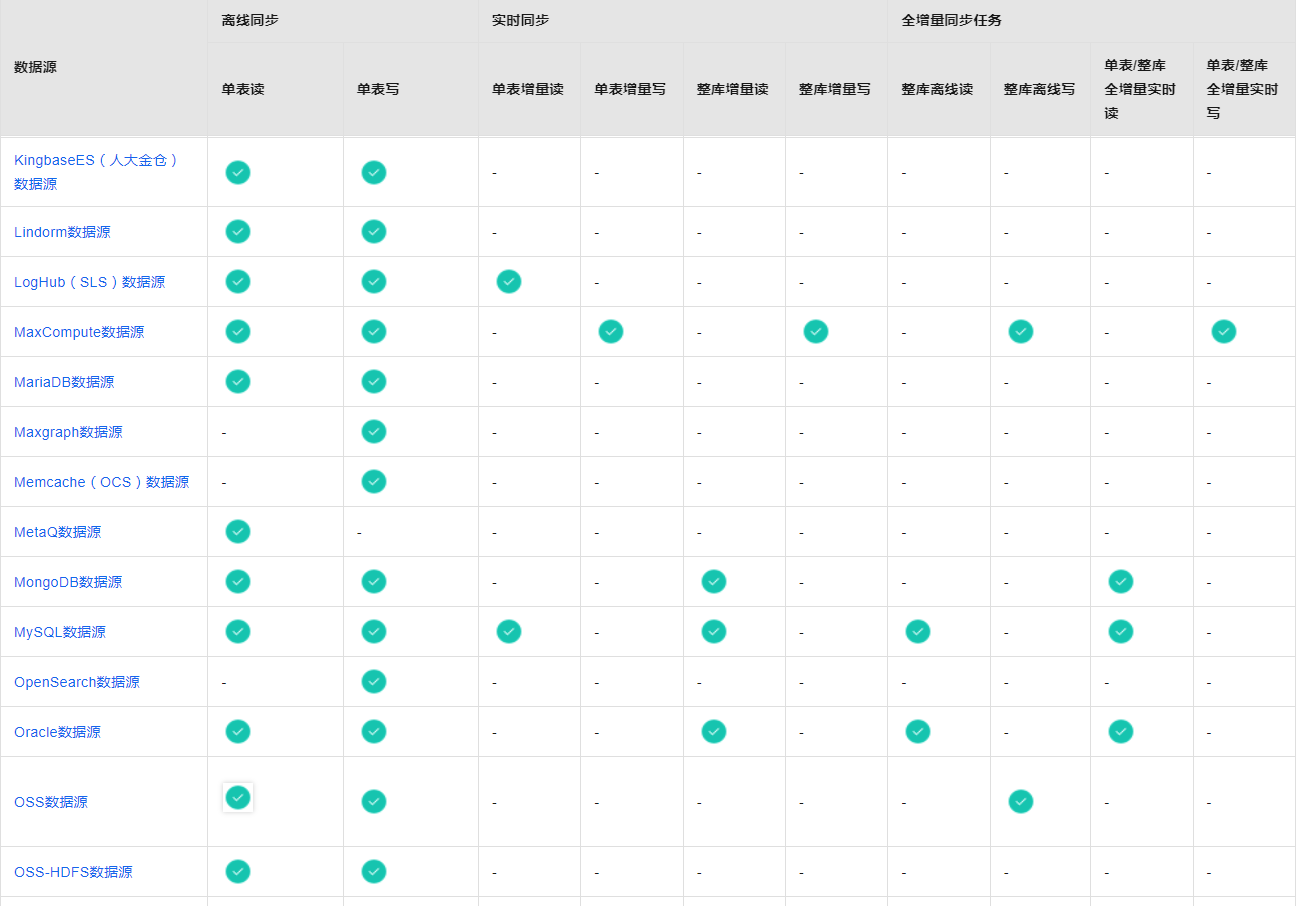
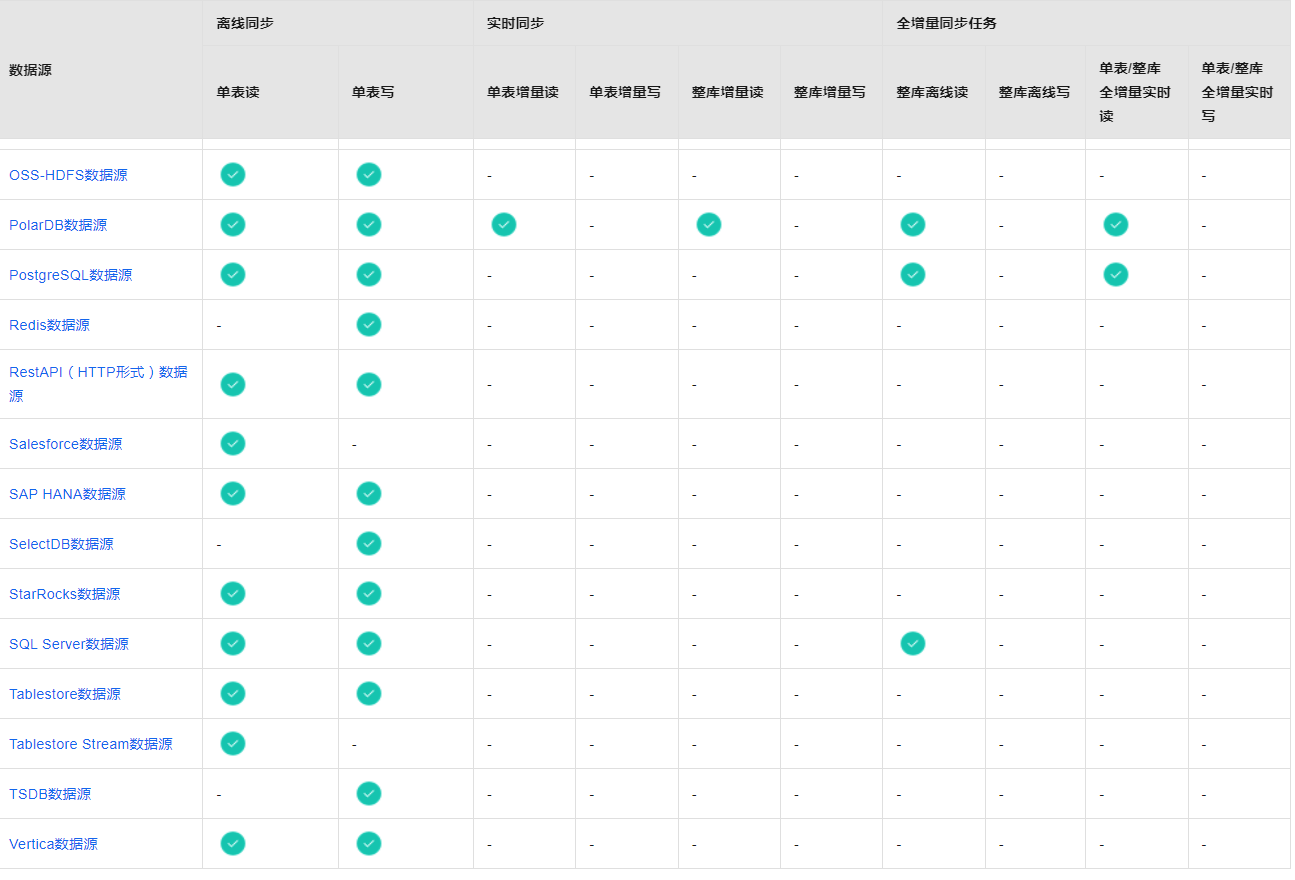
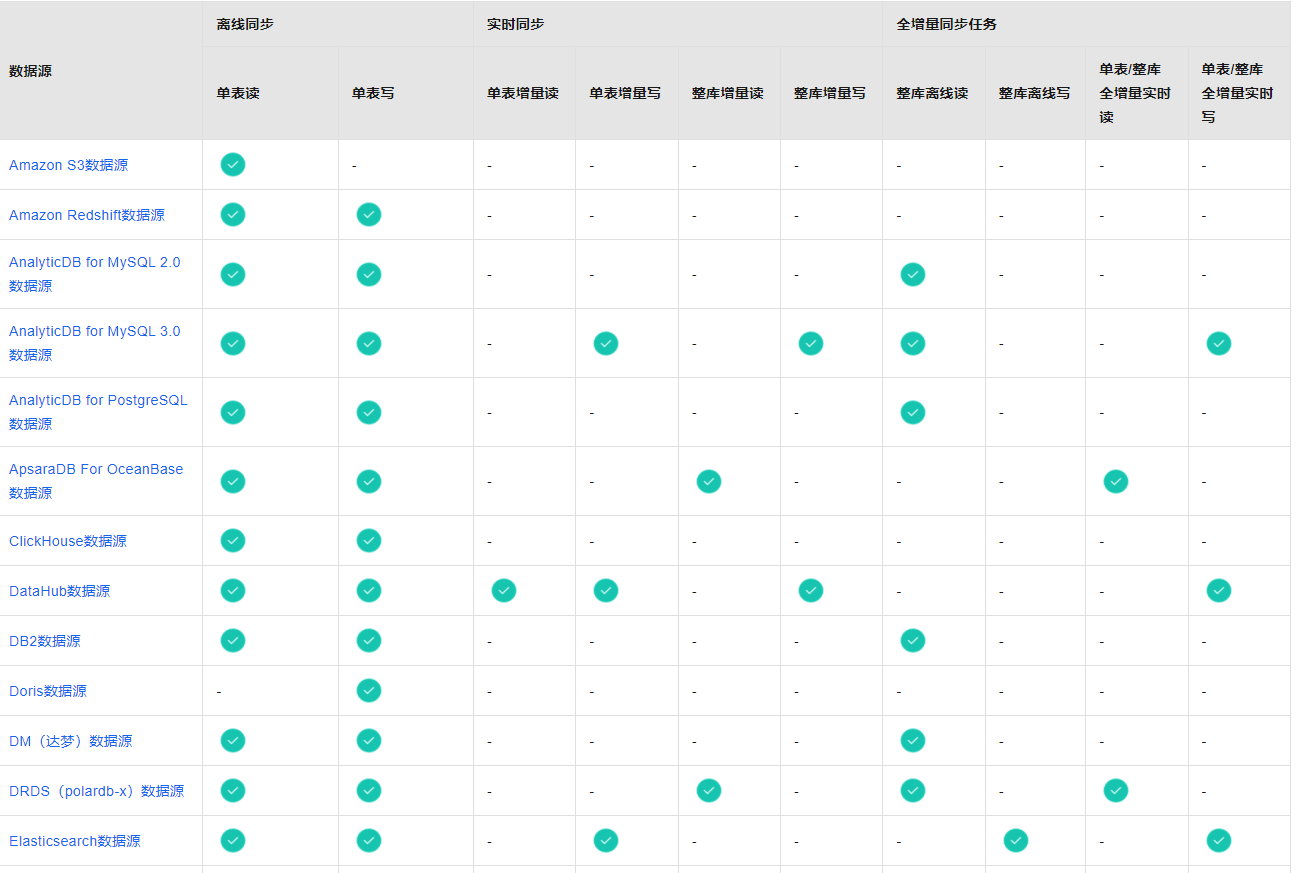
支持的数据源及同步方案https://help.aliyun.com/zh/dataworks/user-guide/supported-data-source-types-and-read-and-write-operations?spm=a2c6h.13066369.question.7.7bae34c3Vlps97
数据集成包括离线同步、实时同步和全增量同步任务三个功能模块,您可以根据各模块对数据源的支持情况,选择对应的功能模块进行同步任务的配置。
DataWorks离线同步为您提供数据读取(Reader)和写入插件(Writer)实现对数据源的读写操作。
DataWorks实时同步支持您将多种输入及输出数据源搭配组成同步链路进行单表或整库数据的实时增量同步。
DataWorks还为您提供多种数据源之间进行不同数据同步场景(整库离线同步、全增量实时同步)的同步。
DataWorks的数据同步功能既支持全量更新也支持增量更新。对于持续更新的数据,例如人员表、订单表等,建议每天进行全量同步,这样您可以方便地获取历史数据和当前数据。然而,当需要根据数据的变更情况进行同步时,可以使用增量同步。增量同步的核心是数据源中存在一个DateTime类型的列,通过定义调度参数以及该列的过滤条件,来实现只同步有变化的数据。同时,离线同步任务支持您通过配置类似的数据过滤功能来决定同步全量数据还是增量数据,配置过滤条件时,将只同步满足过滤条件的数据。因此,无论是全量更新还是增量更新,DataWorks都可以根据您的需求进行灵活的配置和调整。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。