
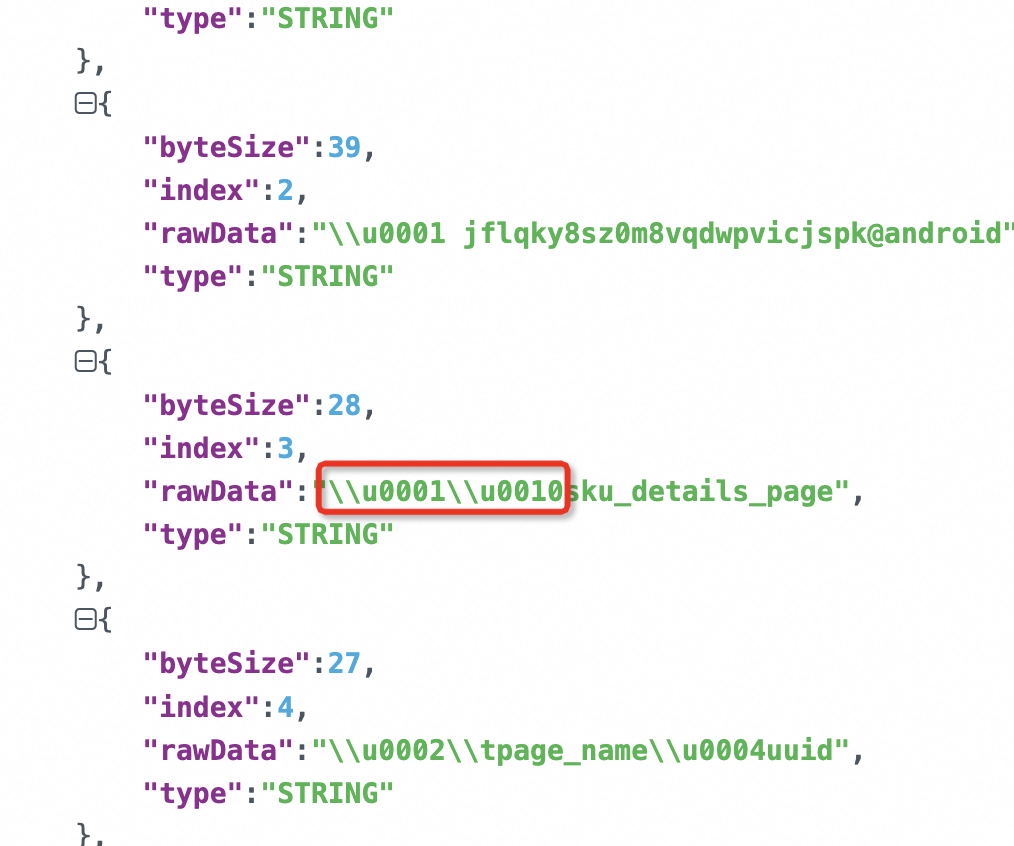
"在DataWorks中,即使没有执行truncate操作也出现了报错现象,启用了对脏数据的容忍机制,仍然无法成功写入任何记录,并且当前数据表的结构一致,当数据转为string,出现特殊字符\u0001、\0001,\0010、\u0010,该怎么处理呢?
 "
"
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用DataWorks进行数据集成时,遇到TRUNCATE操作报错的问题,首先需要明确的是,DataWorks的实时同步任务在设计上是不直接支持TRUNCATE操作的。如果源端数据库表进行了TRUNCATE操作,那么在实时同步任务中不会自动触发相应的清理操作,可能会导致数据同步时的错误。
对于您提到的即使容忍脏数据也无法写入任何数据的情况,这可能是因为实时同步任务配置的并发数过低,或者资源组规格不足以处理当前数据量导致的延迟问题。在这种情况下,您可以尝试以下解决方法:
检查并调整实时同步任务的并发设置。根据您的数据量和资源组规格,适当提高并发数,以便能够处理更多的数据同步任务。
升级资源组规格。如果当前资源组规格无法满足数据同步需求,可以考虑扩大资源组规格,提高其处理能力和稳定性。
优化数据同步策略。例如,可以通过增加写入端并发数,调整JVM参数等方式来提高实时同步的性能。
使用内网进行数据同步。如果可能的话,确保实时同步任务通过内网进行数据传输,以减少网络延迟和不稳定因素的影响。
至于特殊字符的处理,DataWorks数据集成在同步数据时,对于一些特殊字符或不规范的数据格式可能引发问题。为了确保数据同步的稳定性,建议您在数据同步前对数据进行清洗和校验,转换成统一的、符合目标数据表要求的格式。这可以通过编写数据处理脚本或者在数据集成工作流中增加数据质量校验环节来实现。
此外,还需要确保目标数据源有足够的存储空间和性能资源来接收和处理新的数据。如果目标数据库性能不佳或负载过高,同样会导致写入延迟增大,甚至无法写入数据。在这种情况下,您可能需要联系数据库管理员寻求支持,优化数据库性能或进行必要的维护操作。
在DataWorks中,如果遇到特殊字符,可以使用Python的str.encode()和bytes.decode()方法进行转换。对于特殊字符\u0001、\0001、\0010和\u0010,可以尝试以下方法进行处理:
# 将特殊字符转换为字符串
special_chars = ["\\u0001", "\\0001", "\\0010", "\\u0010"]
for char in special_chars:
converted_char = bytes(char, "utf-8").decode("unicode_escape")
print(converted_char)
这段代码会将特殊字符转换为对应的字符串。如果需要将这些字符串插入到其他字符串中,可以直接使用转换后的字符串。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



