
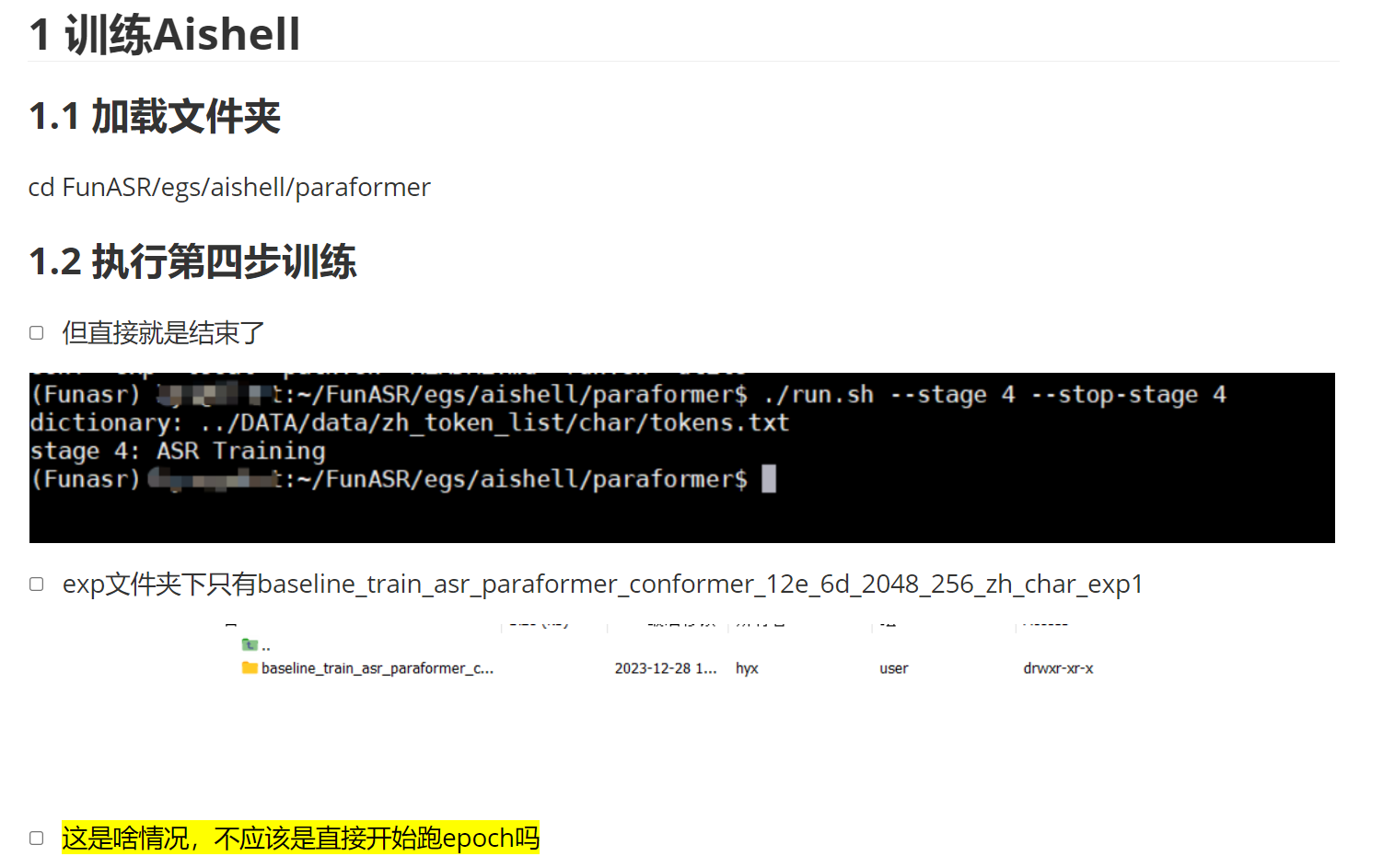
modelscope-funasr想咨询一个训练模型相关的问题,求解答?
在 ModelScope-FunASR 中训练模型涉及多个步骤,包括环境准备、数据集配置、超参数调整以及训练任务的执行。以下是详细的解答和操作指南:
在开始训练之前,请确保您的开发环境已正确配置。根据知识库中的信息,您需要完成以下步骤: - 安装依赖包:克隆 FunASR 代码仓库并安装相关依赖。
git clone https://github.com/alibaba-damo-academy/FunASR.git
cd FunASR
pip install -r requirements.txt
pip install funasr[clip]
python -c "import funasr.utils.cli_utils; funasr.utils.cli_utils.print_info()"
注意:FunASR 的安装需要 Python 3.7 或更高版本,并且需要 PyTorch 和其他依赖包的支持。请确保您的环境满足这些要求。
训练模型需要高质量的数据集。您可以按照以下步骤进行数据集的准备和配置: - 上传数据集:将本地数据集上传至云存储(如 OSS)。如果尚未创建数据集,可以通过 PAI 平台的 新建数据集 功能完成。 - 选择数据集:在训练界面中,通过下拉菜单选择已上传的数据集。如果没有可用数据集,请先创建并上传。 - 验证数据集:建议添加一个验证数据集以评估模型性能。验证数据集的配置方法与训练数据集相同。
重要提示:确保数据集格式符合模型要求(如 JSON 或 JSONL 文件),否则可能导致训练失败。
不同的模型支持不同的超参数配置。您可以根据业务需求调整以下关键参数: - 学习率:控制模型训练的速度和稳定性。 - 批量大小(Batch Size):影响训练效率和内存占用。 - 训练轮数(Epochs):对于小数据集,增加训练轮数可能提升效果;但对于大数据集,过多的轮数可能导致过拟合。
建议:在难任务上,几千条数据通常需要训练 20 轮左右。具体参数需根据实际任务进行实验调整。
完成上述准备工作后,您可以启动训练任务: 1. 在 PAI 平台中,单击 训练 按钮。 2. 配置输出路径,用于保存训练生成的模型和日志文件。 3. 选择计算资源规格(如 GPU 类型和数量)。对于大模型(如 Qwen-72B),建议使用显存更大的 GPU(如 GU100 或 GU108 机型)。 4. 单击 训练,页面将跳转至任务详情页,您可以实时查看训练状态和日志。
如果训练任务失败,您可以按照以下步骤排查问题: - 查看任务诊断:在 PAI-Model Gallery > 任务管理 > 训练任务中,鼠标悬停于失败任务,系统会显示错误原因及解决办法。 - 检查日志信息:常见错误包括数据集格式不正确、输入路径错误或内存不足等。例如: - ValueError: output channel must be directory:检查输出路径是否为文件夹。 - torch.cuda.OutOfMemoryError:选择更大内存的计算资源。
训练完成后,您可以对模型进行评估并提取最优模型: - 评估模型:选择测试集并查看推理结果。如果结果满意,可提取模型;否则重置模型重新训练。 - 提取模型:在评估界面中点击 提取模型,训练流程结束。
以上是 ModelScope-FunASR 训练模型的完整流程。如果您在训练过程中遇到具体问题,可以参考 PAI 平台的任务诊断功能或联系技术支持团队获取帮助。
特别提醒:确保数据隐私和安全,阿里云不会将您的数据用于模型训练。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
